Im Bereich des maschinellen Lernens und der Datenwissenschaft ist die Berechnung von Distanzen zwischen Datenpunkten eine fundamentale Operation. Die Distanzfunktion torch.cdist ist in der PyTorch-Bibliothek genau hierfür verantwortlich und wird häufig in Clustering-Algorithmen, Nearest-Neighbor-Suchen und zahlreichen anderen Anwendungen verwendet. Trotz ihrer Vielseitigkeit kann die Standardimplementierung bei größeren Datensätzen zu Performanceproblemen führen. Hier setzt eine neue Entwicklung an: Die effiziente Implementierung von torch.
cdist mit Hilfe von Triton, einer Plattform zur Erstellung performanter GPU-Kernels, die auf moderne Hardwarearchitekturen optimiert ist. Triton ermöglicht die nahtlose Integration programmierbarer Low-Level-GPU-Kernels in Python, wodurch kritische Rechenoperationen signifikant beschleunigt werden können. Die Optimierung von torch.cdist durch Triton konzentriert sich auf die parallele Berechnung der paarweisen Distanzen größerer Tensoren, wobei sowohl Speicherzugriffe als auch Rechenoperationen effizient gestaltet werden. Dadurch wird die Laufzeit erheblich verkürzt, ohne auf die wichtigen Eigenschaften wie Differenzierbarkeit für Backpropagation zu verzichten.
Die Installation dieser optimierten Variante ist unkompliziert. Über den einfachen Befehl "pip install git+https://github.com/jinensetpal/triton_cdist.git" kann die Bibliothek bezogen und in bestehende PyTorch-Projekte eingebunden werden. Durch die Einbindung wird ein neuer Operator registriert, der als vollwertiger Ersatz für torch.
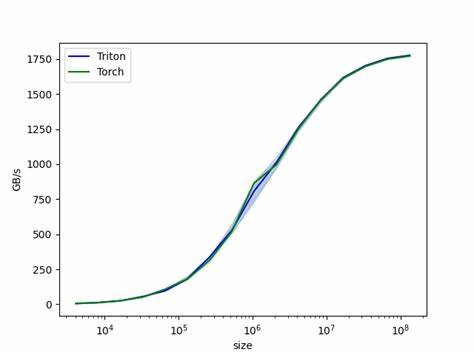
cdist dient. Somit sind Nutzer in der Lage, ihre gewohnte API beizubehalten und von den Performance-Vorteilen transparenter zu profitieren. Die Leistungsverbesserungen sind beeindruckend. Bei kleineren Datensätzen mit beispielsweise jeweils 32 Datenpunkten in den Eingangstensoren beträgt die Ausführungszeit der Triton-Implementierung nur einen Bruchteil der Standardversion. Selbst wenn die Dimensionen und Datenmengen auf mehrere Tausend steigen, zeigt die Triton-Version durchweg eine schnellere oder zumindest gleichwertige Performance.
Besonders deutlich wird der Unterschied bei großen p-Normen wie p=2 oder höheren Werten, die bei der Distanzberechnung eingesetzt werden. Wo Torch standardmäßig deutlich mehr Zeit benötigt, läuft die Triton-Variante wesentlich effizienter und ressourcenschonender. Diese Optimierung eröffnet nicht nur für Forschungsprojekte Vorteile, sondern auch für produktive Systeme, die auf Echtzeit- oder Near-Echtzeit-Analysen angewiesen sind. Beim Training großer neuronaler Netze oder bei der Verarbeitung massiver Punktwolken kann die beschleunigte Berechnung von Distanzen zu drastischen Time-to-Result-Verbesserungen führen. Gerade in Bereichen wie Computer Vision, Natural Language Processing oder 3D-Datenanalyse wird der Nutzen schnell sichtbar.
Wesentlich für die Anerkennung einer alternativen Implementierung ist deren Kompatibilität mit automatischer Differenzierung. Die Triton-basierte torch.cdist unterstützt vollständig die Rückpropagation, was bedeutet, dass sie problemlos in bestehende Trainingspipelines integriert werden kann, ohne Anpassungen oder Workarounds zu erfordern. Dadurch steht der beschleunigten Berechnung auch während des Optimierungsprozesses von neuronalen Netzen nichts im Weg. Trotz der zahlreichen Vorteile hat die aktuelle Version der Triton-Implementierung einige Einschränkungen.
Die Batch-Verarbeitung wurde bislang eher rudimentär umgesetzt, sodass bei komplexen mehrdimensionalen Eingaben eine Optimierung noch aussteht. Allerdings sorgt die intelligente Broadcast-Logik dafür, dass zumindest Fälle, in denen nur einer der Eingangstensoren gebatched ist, ohne nennenswerte Performanceeinbußen verarbeitet werden können. Die Initiative, torch.cdist auf Triton umzustellen, gehört zu einer wachsenden Bewegung innerhalb der Machine-Learning-Community, die versucht, kritische Rechenoperationen näher an der Hardware auszurichten und so das volle Potenzial moderner GPUs auszuschöpfen. Tritons Entwicklungsansatz, benutzerdefinierte CUDA-Kernels in Python einfach nutzbar zu machen, senkt dabei die Barriere für Entwickler massiv und beschleunigt den Innovationszyklus.
Aus SEO-Sicht fokussieren sich viele Anwender und Entwickler darauf, wie sie ihre Deep-Learning-Workflows effizienter gestalten können. Hier bietet die Triton-unterstützte torch.cdist eine praktische Lösung, die konkrete Vorteile bei der Berechnung komplexer Distanzmatrizen liefert. Suchanfragen rund um "Torch cdist beschleunigen", "Optimale Distanzberechnung PyTorch" oder "Triton GPU Optimierungen für cdist" finden so eine klare, nachvollziehbare Antwort. Die Zukunft sieht vielversprechend aus.
Mit stetigen Weiterentwicklungen und der aktiven Community um Triton ist zu erwarten, dass die Implementierung von torch.cdist noch weiter optimiert und an verschiedene Anwendungsszenarien angepasst wird. Möglichkeiten wie bessere Batch-Verarbeitung, kompaktere Speicherlayouts oder die Nutzung zusätzlicher Hardwarefeatures könnten die Effizienz weiter erhöhen. Gleichzeitig eröffnet die beschleunigte Distanzberechnung spannende Möglichkeiten in angrenzenden Forschungsfeldern. In der Bioinformatik, Robotik oder bei der Analyse großer Zeitreihen werden Berechnungen, die sonst prohibitiven Zeitaufwand erfordern, durch diese Fortschritte derart beschleunigt, dass neue Anwendungsfälle realistisch werden.
Somit trägt die verbesserte torch.cdist Implementierung maßgeblich dazu bei, dass vielfältige Datenanalyse- und Lernaufgaben schneller in die Praxis umgesetzt werden können. Insgesamt steht die effiziente Berechnung von Torch.cdist mit Triton exemplarisch für den Trend hin zu performanter, gleichzeitig benutzerfreundlicher Software im Deep-Learning-Bereich. Entwickler erhalten Werkzeuge an die Hand, die Leistungsengpässe beseitigen, ohne Komplexität unnötig zu erhöhen.