In der Welt der Softwareentwicklung und Systemgestaltung ist die Gewährleistung von Datenintegrität und die Vermeidung von Fehlerzuständen ein zentrales Anliegen. Ein Prinzip, das in den letzten Jahren zunehmend an Bedeutung gewonnen hat, trägt den Namen „Ungültige Zustände undenkbar machen“. Dieses Konzept bietet einen eleganten Lösungsansatz, um komplexe Problemstellungen durch eine durchdachte Datenrepräsentation von vornherein zu umgehen – indem man Zustände so modelliert, dass ungültige oder unerwünschte Szenarien rein mechanisch ausgeschlossen sind, bevor sie überhaupt entstehen können. Der Ursprung und die Bedeutung dieses Prinzips sind eng mit der Idee verwandt, dass eine Software nicht nur korrekt funktionieren, sondern auch möglichst resistent gegen falsche Eingaben oder Fehlkonfigurationen sein sollte. Statt sich im Nachhinein mit Fehlern, Inkonsistenzen oder unvorhergesehenen Sonderfällen beschäftigen zu müssen, zielt „Ungültige Zustände undenkbar machen“ darauf ab, durch eine bewusste Gestaltung der Datenstrukturen und Schnittstellen nur gültige Zustände überhaupt abzubilden.
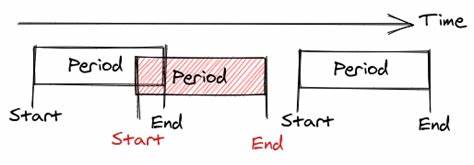
Ein überzeugendes Beispiel hierfür liefert die Arbeit an der Modellierung von zusammenhängenden Zeitabschnitten. Traditionell werden Zeiträume oft einfach durch Start- und Enddaten definiert, womit sich Listen von Zeitraum-Datensätzen ergeben. Solch ein scheinbar einfacher Ansatz birgt jedoch viele Risiken: Es können leicht Lücken zwischen den Abschnitten entstehen oder sich diese überlappen, was zu widersprüchlichen Zeitverläufen führt und große Probleme bei der Verarbeitung verursachen kann. Die verbesserte Methode besteht darin, die redundanten Informationen zu eliminieren und die Zeitachse stattdessen über eine Menge von Zeitpunkten zu definieren, welche als Stunden- oder Tagesgrenzen fungieren. Dadurch wird die Kontinuität garantiert und die Komplexität beim Hinzufügen oder Teilen von Zeitabschnitten reduziert sich deutlich, denn durch das einfache Hinzufügen eines neuen Zeitpunkts zur Menge entsteht automatisch eine korrekte Teilung ohne Überschneidungen oder Lücken.
Die Vorteile einer solchen Repräsentation gehen über die reine Datenintegrität hinaus: Sie erleichtert auch spätere Anpassungen und Erweiterungen, weil komplexe Korrekturen der Datenstruktur entfallen. Diese „Normalisierung“ der Zeitperioden kann problemlos in andere Darstellungsformen transformiert werden, etwa Listen von Start- und Enddaten, wobei das zugrundeliegende Modell weiterhin die strikten Regeln der Gültigkeit einhält. Ein weiteres anschauliches Fallbeispiel zeigt die Verwaltung von Verträgen in einem System, in dem Kunden wiederkehrende Mietzahlungen auf Basis von Verträgen leisten. Ursprünglich wurden sowohl befristete als auch sogenannte Standardverträge als separate Einträge in einer Vertragstabelle geführt, wobei Start- und Enddaten oft optional waren, um unterschiedliche Vertragsarten abzudecken. Diese klassische objektspezifische Modellierung führte zu typischen Problemen: Es entstanden Lücken zwischen Verträgen, was realistisch nicht vorgesehen war, und befristete Verträge hatten gelegentlich kein Enddatum, was ihre Definition unterlief.
Die Folge waren immer wiederkehrende Inconsistenzen im System, deren Behebung aufwändig war und unverhältnismäßig viele Stunden Entwicklung erforderte. Die Ursache lag in der Fehlentscheidung, Standardverträge als eigenständige Entitäten zu repräsentieren, obwohl sie logisch als Fallback gelten sollten. Durch Umgestaltung des Modells und die konsequente Inferenz der Standardverträge anstelle der expliziten Speicherung verschwanden diese Problemfälle und es wurde eine klare, lückenlose Vertragsansicht sichergestellt. Dieses Beispiel illustriert deutlich den Einfluss traditioneller objektorientierter Denkweisen auf die Datenmodellierung: Die Tendenz, jedes Konzept als „Objekt“ mit physischer Existenz in der Datenbank zu entwerfen, kann dazu führen, dass logische Vereinfachungen und wirkungsvolle Abstraktionen verloren gehen. Datenbankdesign profitiert erheblich, wenn es als Abbildung von logischen Aussagen und nicht bloß als Persistenzmechanismus für Softwareobjekte verstanden wird.
Die Ausbildung von Zustandsübergängen und Validierungen im Datenmodell selbst ist essenziell für robuste Systeme. Verbesserungen wie „excludes“-Constraints, die Überlappungen zwischen Verträgen direkt in der Datenbank verhindern, sind pragmatische Werkzeuge. Allerdings können komplexere Anwendungen auch von einer Zweiteilung zwischen Schreib- und Lesemodell profitieren: Während Überlappungen im Schreibmodell erlaubt sind, werden sie im Lesemodell aufgelöst und verarbeitet, um eine konsistente Sicht zu garantieren. So bleiben Daten vollständig und historisierbar, Mutation und Löschung sind minimiert, und fehleranfällige Operationen entfallen. Die Prinzipien hinter „Ungültige Zustände undenkbar machen“ sind keine revolutionäre Neuerfindung, sondern eine Konsequenz sorgfältiger Logik und systematischer Datenmodellierung, die in der Praxis enorme Vorteile bringt.