In der heutigen datengetriebenen Welt gewinnt die effiziente Verarbeitung und Umwandlung großer Datenmengen zunehmend an Bedeutung. Besonders Unternehmen wie Uber, die täglich Millionen von Datenpunkten aus unterschiedlichen Quellen sammeln, stehen vor der Herausforderung, diese Daten schnell, präzise und skalierbar zu verarbeiten. Dabei spielen ETL-Pipelines – Prozesse zum Extrahieren, Transformieren und Laden von Daten – eine zentrale Rolle. Nach einem intensiven fünfstündigen Studium der Datenarchitektur von Uber wird deutlich, dass das Unternehmen traditionelle Ansätze wie reine Batch- oder Streaming-Pipelines bewusst hinter sich lässt und stattdessen innovative Modelle verfolgt, die neue Maßstäbe für moderne Dateninfrastrukturen setzen.Die meisten Unternehmen setzen bei der Datenverarbeitung entweder auf Batch-Pipelines, bei denen Daten in großen Chargen verarbeitet werden, oder auf Streaming-Pipelines, die Daten kontinuierlich in Echtzeit verarbeiten.
Uber jedoch verfolgt einen hybriden, nahezu revolutionären Ansatz, um den extremen Anforderungen an Skalierbarkeit und Geschwindigkeit gerecht zu werden. Statt sich auf starre Kategorien zu beschränken, nutzt das Unternehmen eine flexible Architektur, die Elemente beider Welten kombiniert und darüber hinaus dynamische Steuerungselemente implementiert, um jederzeit einen optimalen Datenfluss zu gewährleisten.Ein wesentlicher Grund für Ubbers innovative ETL-Architektur liegt in der Geschäftsanforderung. Als globale Plattform mit Millionen von Fahrten, Anfragen, Zahlungen und Nutzerdaten in Echtzeit muss Uber Daten nicht nur zuverlässig sammeln, sondern auch blitzschnell analysieren, um operative Entscheidungen zu unterstützen. Beispielsweise müssen Routenoptimierungen, Fahrpreisberechnungen und Fahrerzuweisungen fast ohne Verzögerung erfolgen, während Business-Analytics Teams gleichzeitig historische Daten für strategische Auswertungen benötigen.
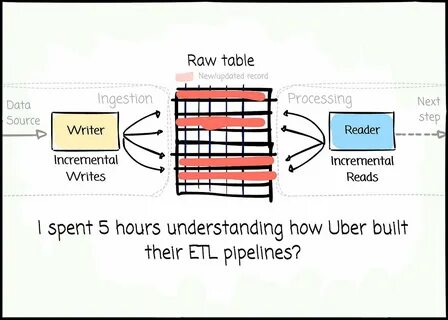
Diese vielfältigen Anforderungen haben Uber dazu veranlasst, herkömmliche ETL-Paradigmen zu hinterfragen und eine datenorientierte Lösung zu entwickeln, die sowohl Echtzeitdaten als auch historisierte Datensätze nahtlos verarbeitet.Die Grundlage der ETL-Pipelines bei Uber bildet ein fortgeschrittenes Event-basierendes System, das alle Datenereignisse zunächst in einem zentralen, verteilten Datenstrom aggregiert. Dieses System stellt sicher, dass sämtliche Ereignisse, wie Benutzerinteraktionen, Transaktionen oder Systemmeldungen, im Originalzustand gespeichert werden, ohne Datenverluste oder Verzögerungen. Die Persistenz dieser Rohdaten ermöglicht es, Daten mehrfach und aus unterschiedlichen Blickwinkeln zu transformieren. Dadurch können verschiedene Teams innerhalb des Unternehmens maßgeschneiderte Ansichten der Daten erschaffen, die exakt ihren spezifischen Anforderungen entsprechen, ohne dass die Rohdaten erneut extrahiert werden müssen.
Die Transformationsphase, traditionell oft als Batch-Aufgabe durchgeführt, ist bei Uber dynamisch gestaltet. Dank eines flexiblen Frameworks können Daten kontinuierlich und adaptiv transformiert werden. Die Pipeline reagiert sofort auf Änderungen in den Datenstrukturen oder den Geschäftsvorgaben und passt die Verarbeitungslogik automatisch an. Diese Automatisierung vermeidet langwierige manuelle Eingriffe und minimiert Fehlerquellen, wodurch die Datenqualität signifikant erhöht wird. Zudem setzen die Entwickler bei Uber auf eine modulare Architektur, sodass Transformationen als isolierte Einheiten implementiert werden, die bei Bedarf schnell ausgetauscht oder erweitert werden können.
Uber integriert bei seiner ETL-Architektur modernste Technologien und bewährte Open-Source-Tools, die auf Skalierbarkeit und Fehlertoleranz ausgelegt sind. Technologien wie Apache Kafka und Apache Flink spielen eine zentrale Rolle im Datenstrommanagement und bei der Echtzeitverarbeitung. Gleichzeitig kommen spezialisierte Datenbanken und Data Warehouses zum Einsatz, um umfangreiche historische Daten effizient zu speichern und auszuwerten. Ein signifikanter Vorteil dieses Ansatzes liegt darin, dass sich Uber nicht auf einzelne Technologien beschränkt, sondern ein offenes Ökosystem schafft, das ständigen Innovationen und Anpassungen standhält.Ein weiterer bemerkenswerter Aspekt bei Ubbers ETL-Pipelines ist der Fokus auf Monitoring, Observability und Data Governance.
Durch integrierte Überwachungssysteme wird sicherstellt, dass Datenflüsse stets transparent sind und eventuelle Anomalien frühzeitig erkannt werden. Darüber hinaus sorgt ein starkes Governance-Modell dafür, dass alle Datenzugriffe kontrolliert und dokumentiert sind, was insbesondere im Hinblick auf Datenschutz und Compliance höchste Priorität besitzt. Diese ganzheitliche Herangehensweise an Datenmanagement gewährleistet nicht nur technische Effizienz, sondern auch Vertrauen in die verarbeiteten Daten.Aus technischer und organisatorischer Perspektive zeigt sich, dass Uber ETL-Pipelines nicht nur als reine Datenverarbeitungsprozesse betrachtet, sondern als zentrale Nervenzentren der gesamten Datenstrategie. Die Pipeline bildet das Rückgrat, auf dem zahlreiche datengetriebene Anwendungsfälle aufsetzen, von der Produktentwicklung über Echtzeitanalysen bis hin zur strategischen Planung.