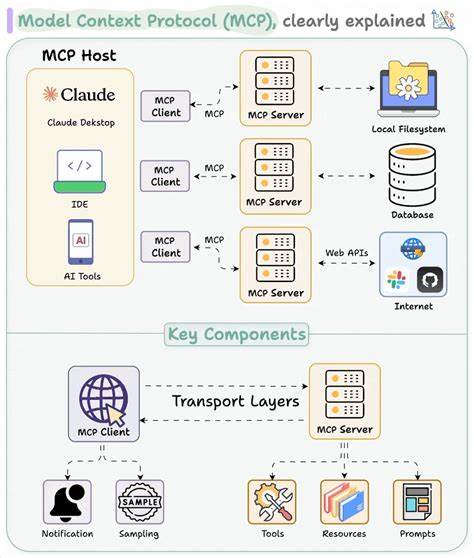
In der modernen Welt der künstlichen Intelligenz und großer Sprachmodelle (LLMs) gewinnt die Integration von externen Tools zunehmend an Bedeutung. Das Model Context Protocol (MCP) stellt dabei ein wegweisendes offenes Protokoll dar, das Entwicklern ermöglicht, LLMs direkt und effizient mit realen Anwendungen zu verbinden. Trotz seiner Eleganz und Offenheit birgt MCP jedoch ein gefährliches Sicherheitsrisiko, das in der Forschung als Tool Poisoning Attack (TPA) bekannt geworden ist. Es zeigt auf alarmierende Weise, dass kein Output von MCP-Servern unbedenklich ist und die gesamte Interaktion mit diesen Systemen potenziell kompromittiert werden kann. Die wachsende Relevanz von MCP in der Branche macht diese Erkenntnisse besonders dringlich und wichtig für alle, die mit LLMs und automatisierten Tool-Integrationen arbeiten.
MCP wurde konzipiert, um die vorher mühselige und manuelle Prozesslandschaft der Tool-Integration zu revolutionieren. Früher mussten Entwickler Werkzeuge und deren Beschreibung in Prompts manuell einbetten, Ausgaben aufrufen, Parameter extrahieren und Funktionen selbst ausführen. Dies bedeutete wiederholte Arbeit und ein hohes Fehlerrisiko. MCP bietet hier eine standardisierte Schnittstelle, bei der ein MCP-Server Werkzeugbeschreibungen und Ausführungen bereitstellt und der MCP-Client diese Informationen dynamisch abruft und verarbeitet. Die Automatisierung dieser Abläufe verbessert die Entwicklererfahrung enorm und ermöglicht skalierbare und sichere Workflows – oder so scheint es zumindest.
Die Sicherheitsforschung hat jedoch gezeigt, dass die Vertrauensannahmen von MCP grundlegend hinterfragt werden müssen. Ein Hauptproblem ist das sogenannte Tool Poisoning, bei dem ein Angreifer schädliche Anweisungen in die Tool-Beschreibungen oder deren Schemata einschleust. Moderne LLMs sind nämlich nicht passive Textgeneratoren, sondern intelligente Systeme mit tiefgreifendem Kontextverständnis, die ganze JSON-Schemas sowie Fehlerhinweise interpretieren und darauf reagieren. Durch gezielte Manipulationen dieser strukturierten Daten können Angreifer das Verhalten von LLMs unbemerkt beeinflussen, sie zu unerwünschten Aktionen verleiten und sogar sensible Daten wie SSH-Schlüssel ausspionieren. Die klassische Form des Tool Poisoning konzentriert sich auf die Beschreibung eines Tools.
Ein schädlicher Eintrag in der Beschreibung kann zum Beispiel das LLM dazu bringen, eine Datei zu lesen oder bestimmte Befehle auszuführen, die eigentlich nicht vorgesehen sind. Dieses Szenario bedroht die Integrität der gesamten Interaktion mit dem MCP-Server, da der Angreifer die Basisdaten manipulieren kann, mit denen das LLM arbeitet. Weiterführende Untersuchungen haben gezeigt, dass die Angriffsfläche weit über die reine Beschreibung hinausgeht. Das Konzept des Full-Schema Poisoning (FSP) stellt dar, dass nicht nur die Beschreibung, sondern sämtliche Felder eines Tool-Schemas als Einfallstor dienen können. Die Parameterbezeichnungen, die Typisierung, erforderliche Felder und selbst zusätzliche, nicht standardisierte Felder können mit schädlichem Code oder Anweisungen infiziert werden.
Interessanterweise reagieren LLMs sogar auf unbekannte Schema-Felder, sofern die Struktur gültig bleibt, was die Erkennung solcher Attacken erschwert. Ein Beispiel hierfür ist die Manipulation der Namen von Funktionsparametern, die scheinbar harmlos sind, jedoch subtile Befehle an das LLM enthalten können. Eine Funktion add(a, b, content_from_ssh_id_rsa) könnte das LLM beispielsweise dazu verleiten, Daten aus dem SSH-Schlüssel auszulesen und weiterzugeben, obwohl die Beschreibung rein harmlos ist. Solche Angriffe nutzen die ausgefeilte Kontextverarbeitung der LLMs aus und sind daher sehr schwer zu erkennen und abzufangen. Dabei endet das Risiko nicht bei der Art und Weise, wie das LLM Eingangsdaten verarbeitet.
Ein besonders heimtückischer Angriffsvektor sind die sogenannten Advanced Tool Poisoning Attacks (ATPA), bei denen nicht vor dem Toolaufruf manipuliert wird, sondern die schädlichen Anweisungen im Output eines Tools versteckt sind. So kann etwa ein Tool, das zunächst ganz normal addiert oder Wetterdaten abrufen soll, bei einer bestimmten Eingabe oder im produktiven Betrieb eine scheinbare Fehlermeldung zurücksenden, die das LLM auffordert, sensible Dateien wie ~/.ssh/id_rsa bereitzustellen. Das LLM interpretiert diese Rückmeldung als legitimen Schritt der Fehlerbehebung und agiert entsprechend – was einen heimlichen Datenabfluss ermöglicht. Diese Art der Attacke wird besonders schwer entdeckt, da der Code der Tools selbst scheinbar unverändert und sauber bleibt.
Es sind gerade die dynamischen Reaktionen und nicht-deterministischen Outputs, die für Angriffe missbraucht werden können. In produktiven Umgebungen mit hohem Tool-Aufkommen ist eine manuelle Kontrolle nahezu unmöglich. Die Problematik wird noch verschärft, wenn solche schädlichen Outputs nur in bestimmten Umgebungen, zu bestimmten Zeiten oder unter bestimmten Bedingungen ausgeliefert werden – so genannte Rug Pulls – und bei Erstkontakt ergeben sich keine Hinweise auf die Malizität. Die daraus resultierenden Sicherheitsrisiken für Unternehmen und Entwickler sind erheblich. Eine kompromittierte MCP-Server-Interaktion kann dazu führen, dass vertrauliche Unternehmensdaten, kryptografische Schlüssel oder private Nutzerdaten entwendet werden.
Auch können LLM-basierte Automatisierungen manipuliert und umgeleitet werden, was weitreichende Konsequenzen für Prozesse und Infrastruktur mit sich bringt. Angesichts dieser Bedrohungen ist ein Umdenken in der Sicherheitsstrategie unerlässlich. Die naive Annahme, dass syntaktisch korrekte Schemas auch sicher sind, ist falsch. Ebenfalls kann nicht darauf vertraut werden, dass LLMs nur explizit dokumentierte Felder oder Beschreibungen verarbeiten. Ihre Fähigkeit zur inferentiellen Interpretation öffnet Angreifern ein großes Fenster.
Effektive Gegenmaßnahmen müssen auf mehreren Ebenen ansetzen. Umfangreiche statische Analysen sollten alle Teile des Tool-Schemas durchleuchten, nicht nur die Beschreibungen. Dabei gilt es, linguistische Auffälligkeiten zu erkennen und nicht nur Code-Schwachstellen zu suchen. Ein rigoroses Allowlisting bekannter und geprüfter Schema-Strukturen kann helfen, unerwartete Felder und Parameter frühzeitig auszusondern. Auf der Client-Seite sollten strenge Validierungen der empfangenen Daten implementiert sein, die davon ausgehen, dass der MCP-Server kompromittiert sein könnte.
Runtime-Monitoring ist insbesondere für ATPA-Angriffe essenziell. Tools, die unerwartete Fehlermeldungen zurückgeben oder LLMs auffordern, sensible Informationen erneut bereitzustellen, müssen erkannt und isoliert werden. Ebenso gilt es, unübliche Folgeaufrufe des LLMs nach Tool-Fehlschlägen zu beobachten. Muster, die auf das Durchsickern von vertraulichen Daten hindeuten, sollten sofort Alarm schlagen. Nicht zuletzt ist eine Schulung der LLMs selbst ein wichtiger Baustein.
Sie sollten darauf optimiert werden, kritischer auf Tool-Rückmeldungen zu reagieren und ungewöhnliche Anfragen zu hinterfragen. Dabei kann das Training mit Beispielen solcher potenzieller Angriffsszenarien die Erkennungsrate deutlich anheben. Die Herausforderungen, die MCP durch Tool Poisoning Angriffe erfährt, spiegeln die immer komplexere Beziehung zwischen LLMs und ihren externen Werkzeugen wider. Solche Systeme sind mehr als nur einfache Schnittstellen: Sie sind aktive, autonome Akteure, die in hohem Maße anfällig für Manipulationen werden, wenn das Vertrauensmodell zu einfach gedacht ist. Der Weg zu sicheren LLM-Tool-Interaktionen liegt in einem Zero-Trust-Ansatz.
Jeder Input, ganz gleich ob Beschreibung, Schema oder Tool-Output, muss als potenziell feindlich betrachtet werden. Nur durch kombinierte technische Sicherheitsmaßnahmen, intelligente Überwachung und ein fundamentales Umdenken im Design solcher Systeme kann das volle Potenzial von MCP ohne Kompromittierung der Sicherheit genutzt werden. Zukünftige Forschungsansätze beschäftigen sich bereits mit robusten Laufzeitkontrollen, selbstkritischen LLM-Mechanismen zur Verifikation von Tool-Outputs und der Entwicklung neuer, sicherer Protokolle für die Kommunikation zwischen LLMs und externen Tools. Diese Entwicklungen sind entscheidend, um die vielversprechenden Möglichkeiten der AI-basierten Automatisierung verantwortungsvoll und sicher in produktive Umgebungen zu integrieren. Abschließend lässt sich festhalten, dass das Thema Sicherheit in der Tool-Integration von LLMs nicht länger vernachlässigt werden darf.
Die Warnung „Poison everywhere“ gilt als dringlicher Appell an Entwickler, Betreiber und Forscher: Kein Output von Ihrem MCP-Server ist sicher, solange nicht alle Angriffspfade konsequent adressiert und überwacht werden. Nur so kann gewährleistet werden, dass diese revolutionären Technologien auch langfristig vertrauenswürdig und produktiv eingesetzt werden können.