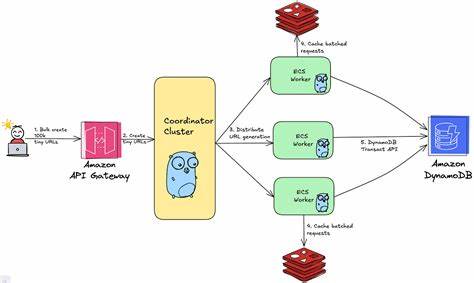
Die zunehmende Digitalisierung und die damit verbundene steigende Anzahl an Webinhalten sorgen für eine immer größere Nachfrage an URL-Verkürzungsdiensten. Dienste wie TinyURL oder Bitly sind sehr beliebt, weil sie lange URLs in kurze, leicht teilbare Links umwandeln. Doch was passiert, wenn eine Plattform plötzlich Millionen von Links in kürzester Zeit generieren muss? Insbesondere wenn 100.000 URLs pro Sekunde verarbeitet werden sollen, stellen sich enorme technische Herausforderungen. Das Ziel ist es, eine verteilte Architektur zu schaffen, die nicht nur leistungsfähig, sondern auch zuverlässig und skalierbar ist.
Dabei müssen Aspekte wie Latenz, Datenkonsistenz und Betriebskosten berücksichtigt werden. Ein Blick auf die Praxis zeigt, dass einfache monolithische Ansätze bei solch hohen Anforderungen schnell an ihre Grenzen stoßen. Besonders bemerkenswert ist die Leistung der Firma Rebrandly, die in Zusammenarbeit mit ihrem Kunden WonderCave eine TinyURL-Lösung entwickelte, die es ermöglichte, in Sekundenschnelle 100.000 URLs zu generieren. Das war entscheidend für das Gelingen einer lebenswichtigen SMS-Kampagne während eines Hurrikans und demonstriert, wie essenziell technische Exzellenz in kritischen Anwendungen sein kann.
Zunächst ist es wichtig, die grundsätzlichen Herausforderungen zu verstehen, die beim Design eines Systems auftreten, das URLs im hunderttausender Bereich pro Sekunde verarbeitet. Der Kernprozess besteht darin, eine kurze URL zu erzeugen, sie mit der langen Original-URL zu verknüpfen und diese Zuordnung dauerhaft zu speichern. Die Generierung der Kurz-URLs muss sicherstellen, dass keine doppelten oder ungültigen Links entstehen. Gleichzeitig soll das System möglichst geringe Latenzen aufweisen, damit Nutzer sofort den gekürzten Link erhalten können. Dies erfordert eine optimierte Verarbeitungspipeline und hochperformante Datenbanken.
Die Verteilung der Last über mehrere Server beziehungsweise Instanzen ist essenziell, um gleichmäßige Skalierung zu ermöglichen und Ausfallrisiken zu minimieren. Bei der Wahl des Datenbankmodells steht man vor der Entscheidung zwischen relationalen Datenbanken und NoSQL-Lösungen. Relationale Systeme bieten starke Konsistenzmodelle, skalieren aber oft schlecht bei extrem hoher Schreiblast. NoSQL-Datenbanken wie Cassandra oder DynamoDB sorgen für eine verteilte Speicherung und hohe Verfügbarkeit, allerdings um den Preis eventueller Inkonsistenzen. Für das TinyURL-System ist eine starke Konsistenz bei der Kurz-URL-Zuordnung entscheidend, da falsche Zuordnungen zu unerwartetem Verhalten führen würden.
In der Praxis werden daher oft hybride Architekturen eingesetzt, die sowohl schnelle Lesezugriffe als auch schnelle Schreiboperationen gewährleisten. Ein weiterer technischer Fokus liegt auf der Art und Weise, wie Kurz-URLs generiert werden. Eine einfache Methode ist die Nutzung einer fortlaufenden ID, die dann in ein alphanumerisches System umgewandelt wird. Diese Methode ist einfach, führt aber zu einem möglichen Single Point of Failure beim Generieren der ID. Ein alternatives Verfahren ist die Verwendung von Hash-Funktionen oder Zufallsalgorithmen.
Hash-basierte Codes können jedoch zu Kollisionen führen und brauchen Mechanismen zur Kollisionserkennung. Zufallscodes sind flexibel, doch die Wahrscheinlichkeit der doppelten Werte muss durch geeignete Designs auf ein Minimum reduziert werden. Um die Skalierbarkeit zu gewährleisten, nutzen viele Systeme Sharding-Strategien. Dabei werden URL-Daten auf mehrere Datenbank-Partitionen verteilt, um parallele Zugriffe zu ermöglichen. Die Herausforderung besteht darin, eine gleichmäßige Verteilung zu erreichen, damit kein Knoten zum Flaschenhals wird.
Zudem muss die Systemarchitektur die Ausfallsicherheit berücksichtigen. Distributed Systeme sind anfällig für Netzwerkpartitionen und temporäre Fehler. Daher sind Failover-Strategien, Replikation und automatische Wiederherstellung unverzichtbar. Der Einsatz von Caching-Systemen wie Redis oder Memcached beschleunigt die Lesezugriffe erheblich, vor allem für häufig genutzte Links. In der Praxis zeigen Implementierungen wie bei Rebrandly, dass eine Kombination aus mehreren Techniken den Erfolg sichert.
Der Einsatz von Event-getriebenen Architekturen, Microservices und serverlosen Komponenten unterstützt eine flexible Skalierung. Automatisiertes Monitoring und alert-basierte Reaktionen ermöglichen es, Engpässe frühzeitig zu erkennen und dynamisch Ressourcen anzupassen. Zudem ist die Wahl der richtigen Cloud-Infrastruktur ein wichtiger Hebel. Anbieter wie AWS, Google Cloud oder Azure bieten verwaltete Datenbankservices, Content Delivery Networks und elastische Compute-Ressourcen, die sich automatisch an wechselnde Lasten anpassen. Sicherheit spielt ebenfalls eine große Rolle.
Die URL-Daten müssen vor unbefugtem Zugriff geschützt werden. Zudem sollten Maßnahmen gegen Missbrauch erfolgen, beispielsweise das Sperren von Spam-Links oder Phishing-Versuchen. Das erfordert intelligente Algorithmen zur Erkennung verdächtiger Muster. Zusammenfassend lässt sich sagen, dass die Entwicklung eines Systems zur Verarbeitung von 100.000 URLs pro Sekunde keine triviale Aufgabe ist.
Es erfordert ein tiefes Verständnis verteilten Systemdesigns, Datenbanken, Skalierungsmechanismen und Sicherheitsaspekte. Die Praxis belegt, dass kombinierte Ansätze aus skalierbaren Datenbanken, effizienter ID-Generierung, Lastverteilung, Caching und modernen Cloud-Infrastrukturen eine Lösung ermöglichen, die sowohl leistungsfähig als auch robust ist. Unternehmen, die sich diesen Herausforderungen stellen, profitieren nicht nur von technologischem Fortschritt, sondern schaffen auch Geschäftsmodelle, die in kritischen Situationen verlässlich funktionieren und Millionen von Nutzern erreichen können.