Große Sprachmodelle (LLMs) haben in den letzten Jahren für enorme Fortschritte in der Künstlichen Intelligenz gesorgt. Sie konnten Texte generieren, komplexe Aufgaben lösen und menschliche Sprache erstaunlich gut nachahmen. Doch trotz all der Begeisterung kommen nun immer mehr kritische Stimmen und wissenschaftliche Untersuchungen, die fundamentale Schwächen dieser Modelle aufzeigen. Insbesondere eine neue Studie von Apple und ergänzende Arbeiten von renommierten Forschern wie Gary Marcus und Subbarao Kambhampati haben erhebliche Zweifel an der Fähigkeit von LLMs geweckt, tatsächlich zu „denken“ oder zu „reasonen“ – und das auch unter Verwendung der modernsten Techniken wie „chain of thought“ und „inference-time compute“ nicht zuverlässig zu leisten. Dieser Beitrag widmet sich dem Stand der Forschung, den Schwächen der LLMs, konkreten Experimenten zum Beispiel am Spiel Tower of Hanoi und den weiterreichenden Konsequenzen für die Vision von Allgemeiner Künstlicher Intelligenz (AGI).
Die Grundkritik an großen Sprachmodellen fußt auf dem seit Jahrzehnten gut erforschten Phänomen der sogenannten „Out-of-Distribution“-Problematik. Einfach gesagt: Modelle, die auf Datenmengen trainiert wurden, sind gut darin, Muster und Zusammenhänge innerhalb dieser Trainingsdaten zu erkennen und zu extrapolieren. Doch sobald die Situation oder Aufgabe außerhalb der gelernten Datenverteilung liegt, versagen diese Modelle oft spektakulär. Diese Erkenntnis ist nicht neu und wurde bereits 1998 von Gary Marcus für frühere Versionen neuronaler Netzwerke nachgewiesen. Seitdem haben sich weder die grundlegenden Herausforderungen noch deren Auswirkungen signifikant verbessert.
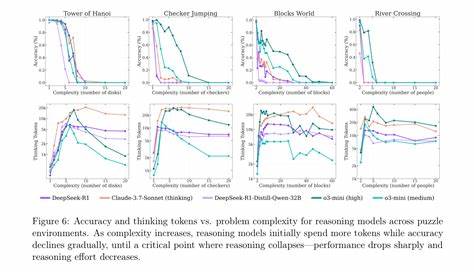
Die Versuche, diese Grenzen zu überwinden, haben zu einer Reihe neuer Methoden geführt, darunter die so genannten „reasoning models“ und Techniken, bei denen Modelle mehrere Rechenschritte oder „chain of thought“ nutzen, um komplexere Probleme schrittweise zu lösen. Während solche Verfahren anfangs Hoffnungen auf eine verbesserte Denkfähigkeit erweckten, zeigen aktuelle Studien, insbesondere die neue Arbeit von Apple, dass große Sprachmodelle selbst mit diesen fortgeschrittenen Methoden oft nicht über ihr Trainingswissen hinaus generalisieren können. Ein besonders eindrückliches Beispiel hierfür ist das klassische Denkspiel Tower of Hanoi. Dabei werden mehrere Scheiben unterschiedlicher Größe auf drei Stäbe verteilt, und die Aufgabe besteht darin, alle Scheiben in einer bestimmten Reihenfolge von einem Stab zum anderen zu bewegen, ohne dabei eine größere Scheibe auf eine kleinere zu legen. Wenngleich das Problem algorithmisch gut verstanden und für Computer trivial lösbar ist, zeigte die Apple-Studie, dass aktuelle LLMs wie Claude oder das o3-Modell selbst bei wenigen Scheiben oft Fehler machen oder die Lösung nicht zuverlässig reproduzieren können.
Das Erschreckende dabei: Das Modell kann teilweise sogar Schritte falsch interpretieren oder braucht teilweise mehrere Versuche, um überhaupt eine korrekte Lösung zu erzielen. Wenn ein einfaches Denkspiel, das seit den Anfängen der Künstlichen Intelligenz bekannt ist, von hochgerüsteten LLMs nicht sauber bewältigt wird, wirft dies ein ernsthaftes Licht auf deren „Intelligenz“. Der Apple-Forscher Iman Mirzadeh betont in Gesprächen, dass es nicht einmal hilft, wenn man dem Modell den Algorithmus vorgibt und es lediglich die Schritte befolgen soll. Die Modelle bleiben inkonsistent und unzuverlässig. Dieses Ergebnis ist besonders desillusionierend, da es nicht nur eine Frage der Rechenschritte oder des Gedächtnisses ist: Menschen können bei diesem Problem zwar auch Fehler machen, insbesondere bei höheren Scheibenzahlen, doch sie haben keine Schwierigkeiten, dem Lösungsprogramm zu folgen, wenn es exakt vorgegeben wird.
Zudem verfügen KI-Modelle über gigantische Speicherressourcen, die sie theoretisch befähigen sollten, mehr Informationen fehlerfrei zu verarbeiten als Menschen. Neben Tower of Hanoi wiesen die Forschenden auch bei anderen klassischen und komplexen Problemen erhebliche Ausfälle von LLMs nach. Selbst bei Aufgaben, bei denen viele Quellcodes, Algorithmen oder Lösungsideen öffentlich verfügbar sind, versagen die Modelle oft bei der korrekten Ausführung oder Generalisierung. Diese Erkenntnisse stellen die zentrale Botschaft der neuen Forschungen dar: LLMs sind keine universellen und zuverlässigen Problemlöser und werden es zumindest in naher Zukunft auch nicht sein. Was bedeutet das für die Debatte rund um Allgemeine Künstliche Intelligenz (AGI)? Viele AI-Experten und Unternehmer haben in den letzten Jahren immer wieder die Erwartung geschürt, dass die bestehenden großen Sprachmodelle – mit genug Daten und enormer Skalierung – in naher Zukunft in der Lage sein werden, eine Form von echter Generalisierung und intelligenter Problemlösung zu erreichen.
Doch Studien wie die von Apple legen nahe, dass es fundamentalere Grenzen gibt, die sich nicht allein durch größere Datenmengen oder raffiniertere Taktiken beim Training beheben lassen. Dabei unterstreicht Gary Marcus, ein prominenter Kritiker und Forscher im Bereich Künstliche Intelligenz, dass AGI nicht einfach darin bestehen kann, menschliches Verhalten naiv zu imitieren oder menschliche Denkfehler nachzuahmen. Vielmehr sollte eine erfolgreiche AGI eben jene Einschränkungen des Menschen, wie Fehleranfälligkeit, beschränktes Gedächtnis und mangelnde Zuverlässigkeit, durch die Fähigkeiten von Computern überwinden. Ein System, das bei elementaren Aufgaben wie der korrekten Ausführung eines Algorithmus scheitert, kann kaum als vertrauenswürdige Grundlage für sicherheitskritische oder gesellschaftlich bedeutende Anwendungen gelten. Es gibt Stimmen, die darauf hinweisen, dass auch Menschen bei komplexeren Versionen von Aufgaben wie Tower of Hanoi Fehler machen.
Doch der entscheidende Unterschied liegt darin, dass Menschen in der Lage sind, diese Verfahren bewusst zu erlernen, zu optimieren und zu verfeinern und vor allem ihre Fehler zu verstehen und zu korrigieren. Maschinen hingegen zeigen bisher keine echte Einsicht oder robustes Verstehen, sondern handeln oft rein statistisch aufgrund gelernter Wahrscheinlichkeiten. Der Gedanke einer wirklichen „intelligenten Maschine“ setzt jedoch genau diese Fähigkeit voraus, systematisch und zuverlässig Probleme zu verstehen und zu lösen. Ein relativ neuer Ansatz in der KI-Forschung ist die Kombination von neuronalen Netzwerken mit symbolischer KI. Diese sogenannten neurosymbolischen Systeme versuchen, die Fähigkeit zu robustem logischem Denken mit der Flexibilität und Lernkapazität moderner Algorithmen zu verbinden.
Noch sind diese Ansätze im Aufbau, aber sie zeigen interessante Perspektiven, um die Schwächen klassischer großer Sprachmodelle zu mildern. In der Praxis werden LLMs trotz ihrer Begrenzungen weiterhin breit eingesetzt. Besonders in den Bereichen Textgenerierung, kreatives Schreiben, Brainstorming oder als Hilfsmittel beim Programmieren leisten sie wertvolle Dienste. Einige Experten sehen in ihnen eine Form von „sprachlicher Intuition“, ähnlich der menschlichen Fähigkeit, Muster zu erkennen und schnell flüssige Antworten zu formulieren. Aber sie warnen auch, dass man von ihnen keine zuverlässigen, logisch durchdachten Lösungen für komplexe oder sicherheitskritische Probleme erwarten sollte.
Aus Sicht von Unternehmen und Gesellschaft bedeutet das, dass der unreflektierte Einsatz von LLMs in sensiblen Bereichen riskant ist. Beispielsweise kann man nicht erwarten, dass eine KI-basierte Lösung zur Steuerung kritischer Infrastrukturen oder bei medizinischen Diagnosen allein auf Sprachmodell-Technologie beruhend funktioniert. Hier sind klassische Algorithmen, spezialisierte Systeme und menschliche Expertise unverzichtbar. Die Forschungsergebnisse stellen also einen Weckruf dar. Sie fordern die KI-Community dazu auf, realistischere Erwartungen zu entwickeln und die Grenzen der aktuellen Technologien anzuerkennen.
Gleichzeitig zeigen sie den Weg für neue Forschungsrichtungen auf, die über pixelgenaue Skalierung und verbesserte Trainingsstrategien hinausgehen. Die Integration von Symbolik, kausalem Denken und robustem logischem Schließen sowie die Verknüpfung von Maschine und Mensch als Partner in der Problemlösung sind zentrale Elemente dieser Zukunft. Einige Kommentatoren haben auch kritisiert, dass gewisse Modelle wie „Gemini 2.5 Flash“ offenbar komplexe Aufgaben wie das Tower of Hanoi mit 8 oder gar 9 Scheiben lösen können. Dies könnte daran liegen, dass Firmen Modelle speziell für Benchmarks optimieren oder zusätzliche „Cheats“ einbauen, um auf gewissen Tests besser abzuschneiden.
Dies bestärkt die These, dass reine Textgenerierung und statistisches Mustererkennen zwar beeindruckend sein können, jedoch keine tiefgehende, zuverlässige Intelligenz erzeugen. Abschließend lässt sich festhalten, dass große Sprachmodelle in ihrer aktuellen Form und mit den aktuellen Technologien wohl nicht der „Heilige Gral“ der Künstlichen Intelligenz sind. Trotz aller Fortschritte zeigen sie fundamentale Schwächen beim logischen Denken und der Generalisierung über ihre Trainingsdaten hinaus. Für die visionäre Vorstellung von AGI, die in der Lage ist, die menschliche Intelligenz wirklich zu ergänzen oder zu übertreffen, sind diese Defizite eine klare Bremse. Die Herausforderung bleibt, wie man aus der vorhandenen Technologie nachhaltige Fortschritte macht.
Klar ist, dass es Zeit, Forschungsgeld und vor allem innovative Ansätze braucht, die über bloße Datenmengen und Rechenkapazitäten hinausgehen. Die Kombination von menschlicher Kognition, formaler Logik und maschinellem Lernen könnte der Weg sein, um die nächste Generation intelligenter Systeme zu schaffen, die wirklich verlässlich, verständig und sicher agieren. Bis dahin gilt es, die Enttäuschungen als notwendige Realitätsprüfung zu sehen und verantwortungsvoll mit der derzeitigen LLM-Technologie umzugehen.