Die kontinuierliche Weiterentwicklung von Grafikprozessoren (GPUs) spielt eine entscheidende Rolle in der Beschleunigung maschinellen Lernens und datenintensiver Anwendungen. In diesem Zusammenhang steht der AMD Instinct MI300X als hochmoderner Vertreter, der mit beeindruckenden technischen Spezifikationen neue Maßstäbe im Bereich Speicherbandbreite und Rechenleistung setzt. Das Verständnis der tatsächlichen Speicherübertragungsgeschwindigkeit – abgebildet durch einen sogenannten Memcpy-Benchmark – ist dabei essenziell, um Leistungsgrenzen und Optimierungspotenziale realer Anwendungen besser einschätzen zu können. Der MI300X ist mit 192 GB HBM3E-Speicher ausgestattet, was einen herausragenden Speicherdurchsatz von bis zu 5,3 Terabyte pro Sekunde erlaubt. Zudem verfügt die GPU über eine enorm starke Rechenleistung, gemessen in Petaflops, was besonders für datenintensive Workloads, wie etwa bei großen Sprachmodellen (Large Language Models, LLMs), von Bedeutung ist.
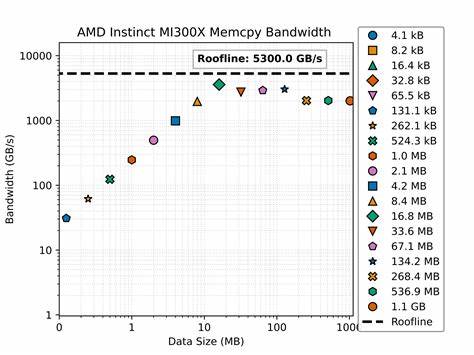
Memcpy-Operationen, also Kopiervorgänge innerhalb des GPU-Speichers, dienen als eine zentrale Benchmark, um die Effektivität der Speicherhierarchie sowie die Kopiergeschwindigkeit bei verschiedenen Datenvolumina zu messen. Die Durchführung des Benchmarks umfasst das schrittweise Kopieren von Datenmengen, die von wenigen Kilobyte bis hin zu mehreren Gigabyte reichen. Dabei wird gemessen, wie viel Speicherbandbreite bei den einzelnen Blockgrößen genutzt wird. Eine wichtige Erkenntnis aus den Tests ist, dass sehr kleine Kopiergrößen unterhalb von 1 MB die Bandbreite stark begrenzen – hier werden Werte von weniger als 100 GB/s erreicht, was insbesondere durch Latenz und Overhead bedingt ist. Mit zunehmender Datenmenge steigt die Bandbreite deutlich an und erzielt innerhalb eines Bereiches von 10 bis 100 MB Werte, die nahe an die theoretische Höchstgrenze von 5,3 TB/s heranreichen.
Interessanterweise erreicht die reale Memcpy-Bandbreite allerdings meist nur etwa 40 bis 60 Prozent der maximalen, theoretisch möglichen Bandbreite. In der Praxis bedeutet dies Transferleistungen von 2.000 bis 3.000 GB/s bei größeren Datensätzen. Dieser Wert ist in Bezug auf den theoretischen Maximalwert gut, wenn man bedenkt, dass Speicher- und Prozessorkomponenten in Realität durch zahlreiche Faktoren beeinflusst werden – darunter Speicherverwaltung, Caches und Betriebsfrequenzen.
Die Bandbreitencharakteristik spiegelt das typische Verhalten hierarchischer Speichersysteme wider. Kleinere Datenblöcke sind durch den Overhead von Speicheraufrufen und Latenzzeiten limitiert, während mittlere Übertragungsgrößen am effizientesten genutzt werden können. Mit noch größeren Transfers übersteigt man teilweise die Kapazitäten der Speicherverwaltungsarchitektur, was zu einem Plateau in der Bandbreitennutzung führt. Für Entwickler und Ingenieure, die mit GPUs arbeiten, zeigen die Benchmark-Ergebnisse eine klare Richtung: Es ist ratsam, Speicheroperationen auf Datenblöcke von etwa 10 bis 100 MB auszurichten. Diese Größenordnung optimiert die Ausnutzung des Speicherbusses und minimiert Verzögerungen.
Besonders bei LLMs, in denen große Embedding-Tabellen verarbeitet werden, ist diese Erkenntnis maßgeblich für Performance-Tuning und effiziente Ressourcenallokation. Das Benchmarking des MI300X wurde mittels eines in PyTorch umgesetzten Memcpy-Kernels durchgeführt. Dabei wurde sichergestellt, dass die Zeitmessung akkurat erfolgt, indem GPU-spezifische Synchronisationsmechanismen und Timing-Events verwendet wurden. Besonders wurde auf einen Warm-up-Mechanismus geachtet, der es erlaubt, die GPU bei voller Leistungsaufnahme zu messen, ohne Verzerrungen durch initiale Startup-Zeiten zu riskieren. Der Kernel selbst führt wiederholte Kopiervorgänge aus, bis mindestens eine Sekunde vergangen ist, um aussagekräftige Messwerte zu erhalten.
Die Methode copy_ wurde eingesetzt, um die Daten in-place zu kopieren und unnötige Speicherallokationen zu vermeiden. Mit solch einer rigorosen Messmethode lässt sich ein realistisches Bild der tatsächlichen Speicherbandbreitenauslastung zeichnen. Die Benchmark-Implementierung berücksichtigt zudem plattformübergreifende Aspekte. So sorgt eine speziell entworfene Abstraktionsebene für die korrekte Handhabung von Timing-Events, egal ob auf GPUs oder CPUs. Dies ermöglicht die Portierbarkeit des Benchmarks über verschiedene Hardwarekonfigurationen hinweg und erleichtert den Vergleich verschiedener Systeme.
Die Messungen wurden innerhalb einer kontrollierten Umgebung durchgeführt, die durch eine Docker-basierte Infrastruktur bereitgestellt wird. Das Projekt ScalarLM, auf dem der Benchmark aufbaut, stellt ein umfassendes Framework für das Testen von LLM-Hardware dar und garantiert durch die Verwendung eines standardisierten Containers konsistente und reproduzierbare Ergebnisse. Durch die Offenlegung des Benchmark-Codes auf der ScalarLM GitHub-Plattform wird Transparenz geschaffen und es wird ermöglicht, den Benchmark einfach anzuwenden oder anzupassen. Dies fördert die Weiterentwicklung von Performancemessungen und erlaubt es Anwendern, spezifische Optimierungen für ihre Anwendungen zu evaluieren. In der Zukunft versprechen ähnliche Benchmarks, kombiniert mit weiteren Analysewerkzeugen, tiefere Einblicke in Speicher- und Rechenverfahren auf modernen GPUs.