Gesetze, Machtgesetze und Statistiken: Ein Blick hinter die Kulissen der Datenanalyse In der Welt der Wissenschaft und Forschung gibt es viele Diskurse, die sich um die Bedeutung von Daten und deren korrekter Analyse drehen. Besonders im Bereich der Physik, Biologie und Sozialwissenschaften ist die Fähigkeit, Daten richtig zu interpretieren, von herausragender Bedeutung. Es sind nicht nur die Theorien, die in der wissenschaftlichen Community diskutiert werden, sondern auch die Methodologien, die zur Überprüfung dieser Theorien eingesetzt werden. Ein zentrales Thema in dieser Diskussion ist die Analyse von Gesetzen und Machtgesetzen sowie deren statistische Validierung. Das Verständnis von Machtgesetzen, die in vielen natürlichen und sozialen Phänomenen auftreten, hat seit einiger Zeit an Bedeutung gewonnen.
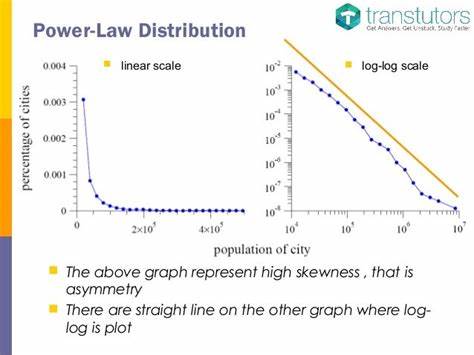
Ein bekanntes Beispiel ist das Gutenberg-Richter-Gesetz, das die Verteilung von Erdbebenenergie beschreibt. Es zeigt, dass die Wahrscheinlichkeit von Erdbeben mit zunehmender Energie umkehrt – nach dem Prinzip, dass größere Erdbeben seltener auftreten. Diese wissenschaftliche Entdeckung ist nicht nur für Geophysiker von Interesse, sondern auch für Ökonomen, Biologen und sogar Informatiker, die ähnliche Verteilungen in ihren jeweiligen Disziplinen beobachten. Aber was ist ein Machtgesetz genau? Es beschreibt eine Beziehung zwischen zwei Größen, bei der eine Größe als Potenz einer anderen dargestellt werden kann. In einfachen Worten bedeutet dies: Wenn man bestimmte Parameter in logarithmischer Form betrachtet, ergibt sich eine lineare Beziehung.
Dies hat weitreichende Implikationen, da es darauf hinweist, dass bestimmte Phänomene unabhängig von ihrer Skala ähnliche Verhaltensmuster aufweisen. Während es in der Theorie einfach scheint, die Realität einer Datenanalyse ist oft viel komplexer. Ein wesentliches Problem besteht darin, dass Datenanalysen oft von einer Vielzahl von subjektiven Faktoren beeinflusst werden. Forschungsfragen, Hypothesen und die Auswahl von Daten können das Ergebnis maßgeblich beeinflussen. Oft wird das Gefühl, dass eine Regressionstechnik angenommen wird, um die „richtige“ Antwort zu finden, als sichere Vorgehensweise betrachtet.
Doch genau hier liegt die Gefahr: Die menschliche Neigung zu wishful thinking kann dazu führen, dass Fehler übersehen oder Daten falsch interpretiert werden. Ein Beispiel für diese Problematik zeigt sich in den Forschungen von Aaron Clauset und seinen Kollegen, die darauf hinweisen, dass die Standardmethoden der statistischen Analyse, wie sie oft in der Datenwissenschaft verwendet werden, in vielen Fällen nicht die besten Ergebnisse liefern. Insbesondere die herkömmliche lineare Regression kann schwerwiegende Fehler verursachen, wenn es um die Analyse von logarithmierten Daten geht. Die Beziehung zwischen den Variablen wird dadurch verzerrt, was zu falschen Schlussfolgerungen führen kann. Zur besseren Analyse von Machtgesetzen sind daher höhere statistische Fertigkeiten erforderlich.
Clauset et al. schlagen vor, dass eine erste logische Maßnahme darin besteht, die Wahrscheinlichkeit zu bewerten, dass die empirischen Daten, wenn die zugrunde liegende Physik tatsächlich ein Machtgesetz impliziert, tatsächlich so beschaffen sind. Dieses Vorgehen ähnelt dem Finden eines p-Werts in der traditionellen Statistik, erfordert jedoch zusätzliche Überlegungen, da hier die Verteilung nicht vorab bekannt ist. Die wahre Herausforderung besteht jedoch nicht nur darin, die Wahrscheinlichkeit eines Machtgesetzes zu bewerten, sondern auch andere mögliche Verteilungen in die Analyse einzubeziehen. Der Vergleich von Machtgesetzen mit Alternativen wie exponentiellen Verteilungen oder anderen physikalisch motivierten Verteilungen kann zusätzlichen Aufschluss über die Daten geben.
Diese sorgfältige Betrachtung ist entscheidend, um die Gültigkeit von Hypothesen in der Wissenschaft zu überprüfen. Ein weiteres zentrales Element der Datenanalyse ist der Umgang mit Fehlern und Ungewissheiten. In der Wissenschaft werden selten perfekte Daten gesammelt. Oft sind die Informationen unvollständig oder unscharf, was die Interpretationen erschwert. Statistische Analysen müssen daher Möglichkeiten bieten, diese Unsicherheiten zu berücksichtigen.
Die Re-Analysen von Clauset et al. für prominente Datensätze haben gezeigt, dass die Unterstützung für Machtgesetze variieren kann. Während einige Verteilungen, wie etwa die Verteilung von Waldbränden, moderat gut zu einem Machtgesetz passen, schneiden andere wie die Vermögensverteilung nicht gut ab. Die Bedeutung dieser Erkenntnisse kann nicht überbewertet werden, da sie die wissenschaftliche Community dazu drängen, die Grenzen von Machtgesetzen und deren Anwendbarkeit zu überdenken. Der Ruf nach einer rigorosen Datenanalyse wird immer lauter.
Wissenschaftler, die sich an den Erwartungen festklammern, dass ihre Ansätze gültig und ihre Daten überzeugend sind, müssen lernen, dass Datenanalyse kein kreativer Prozess im herkömmlichen Sinne ist. Vielmehr handelt es sich um eine disziplinierte Herangehensweise, die sowohl die Kreativität des Erfindens neuer Theorien als auch die Methodik des Überprüfens dieser Theorien miteinander verbindet. In der dominierenden Kultur der Robotik und künstlichen Intelligenz erleben wir einen weiteren Wandel, der das Potenzial hat, die Art und Weise, wie wir Daten analysieren, grundlegend zu verändern. Algorithmen und maschinelles Lernen bieten neue Methoden zur Identifizierung von Mustern in großen Datensätzen. Allerdings stellt sich die Frage, wie weit diese Technologien in der Lage sind, die vorgenannten Probleme aufgrund menschlicher Neigungen und begrenzter statistischer Fähigkeiten zu überwinden.
Zusammenfassend lässt sich sagen, dass die Analyse von Machtgesetzen und statistischen Daten in der Wissenschaft ein entscheidendes Element für den Fortschritt ist. Die bisherigen Erfahrungen haben gezeigt, dass wir uns nicht ausschließlich auf einfache Regressionstechniken oder visuelle Darstellungen stützen dürfen. Stattdessen ist es von entscheidender Bedeutung, einen kreativen, aber gleichzeitig rigorosen Ansatz zur Analyse von Daten zu wählen. Der Wert einer akkuraten Datenanalyse reicht über die einfache Feststellung hinaus, was "passt" oder "nicht passt". Sie schützt vor dem Einfluss von Wunschdenken und fordert Wissenschaftler dazu auf, die Integrität ihrer Hypothesen und Theorien ständig zu hinterfragen.
In einer Welt voller Informationen müssen wir sicherstellen, dass wir die Wahrheit erkennen und verstehen, wie und warum bestimmte Muster in den Daten erscheinen.