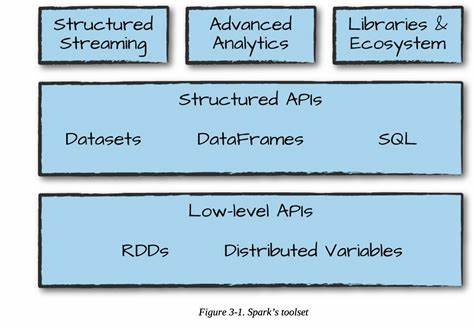
Apache Spark hat sich seit seiner Einführung als eines der führenden Frameworks für Big-Data-Verarbeitung etabliert. Mit der Veröffentlichung von Apache Spark 4.0 im Mai 2025 erreicht die Plattform einen neuen Meilenstein, der die Art und Weise, wie Unternehmen und Entwickler mit großen Datenmengen umgehen, grundlegend verändert. Spark 4.0 setzt auf bedeutende Verbesserungen in verschiedenen Kernbereichen wie SQL, Streaming, Python APIs und der neuen Spark Connect Architektur.
Diese Neuerungen machen Spark leistungsfähiger, benutzerfreundlicher und stärker auf moderne Anforderungen zugeschnitten, ohne dabei die Kompatibilität zu bestehenden Workloads zu verlieren. Der folgende Überblick beleuchtet die wichtigsten Innovationen von Apache Spark 4.0 und erklärt, wie sie das Big-Data-Ökosystem nachhaltig prägen. Die Architektur hinter Spark 4.0 wurde maßgeblich durch die Weiterentwicklung von Spark Connect, der neuen Client-Server-Struktur von Spark, geprägt.
Spark Connect trennt die Anwendungsebene vom Spark-Cluster und ermöglicht damit eine modulare und skalierbare Arbeitsweise. In Version 4.0 wurde die Feature-Parität zwischen Spark Connect und dem klassischen Ausführungsmodus nahezu vollständig erreicht. Besonders die Schnittstellen für Python und Scala sind nun optimal aufeinander abgestimmt, was eine reibungslose Migration von bestehenden Spark Classic Anwendungen erleichtert. Zusätzlich eröffnet Spark Connect dank der Unterstützung neuer Programmiersprachen wie Go, Swift und Rust neue Entwicklerwelten.
Diese Mehrsprachigkeit erweitert den Nutzerkreis und erlaubt die direkte Integration von Spark in unterschiedlichste Projekte und Technologien. Das Aktivieren von Spark Connect ist mit der simplen Einstellung "spark.api.mode" schnell umgesetzt und empfiehlt sich für neue Projekte, um von den Optimierungen zu profitieren. Eines der zentralen Upgrade-Elemente in Spark 4.
0 betrifft die SQL-Funktionalität. Die Erweiterung des SQL-Sprachumfangs macht komplexe Analysen einfacher und schneller handhabbar. So unterstützt Spark 4.0 jetzt SQL User-Defined Functions (UDFs) direkt innerhalb der SQL-Skripte, was die Wiederverwendbarkeit von Logik fördert und gleichzeitig die Performance durch eine bessere Integration in den Query Optimizer erhöht. Parallel dazu wurde eine neue PIPE-Syntax eingeführt, die es erlaubt, SQL-Operationen mit dem |> Operator funktional zu verketteten.
Diese syntaktische Neuerung trägt zu einer klareren und übersichtlicheren Abbildung von Datenfluss und Transformationen bei. Zudem bietet Spark 4.0 eine erweiterte Kollations-Option für STRING-Typen, welche sprach-, akzent- und groß-/kleinschreibungsbewusste Sortierungen ermöglicht. Session-Variablen, die innerhalb von SQL-Sitzungen verwaltet werden können, erlauben die Speicherung und Nutzung von Zuständen ohne Fremdcode, während neue Parameter-Markierungen (":var" und "?") Sicherheit und Flexibilität beim Umgang mit dynamischen Query-Parametern erhöhen. Parallel zu den Sprachverbesserungen wurde die Entwicklerproduktivität durch strenge Datenintegrität optimiert.
Der Default-Modus für SQL in Spark 4.0 ist nun der ANSI SQL-Modus. Diese Umstellung sorgt dafür, dass kritische Fehler wie numerische Überläufe oder Divisionen durch Null konsequent als Fehler signalisiert werden, anstatt stumm fehlerhafte Ergebnisse zu produzieren. Für Entwickler bedeutet das mehr Transparenz, Stabilität und eine bessere Migration von SQL-Workloads zu Spark, da ANSI-Kompatibilität den Standard in vielen Datenbanken und Analyseplattformen widerspiegelt. Zusätzlich wurde der neue VARIANT-Datentyp eingeführt, der speziell für semi-strukturierte Daten wie JSON entworfen wurde.
VARIANT ermöglicht die Speicherung komplexer verschachtelter Datenstrukturen in einer einzigen Spalte und erleichtert deren effiziente Abfrage und Indexierung, was gerade bei modernen, vielfältig formatierten Datenquellen zunehmend wichtig ist. Für eine verbesserte Überwachbarkeit und Fehlersuche bietet Spark 4.0 ein strukturiertes Logging, bei dem Logeinträge als JSON-formatierten Zeilen ausgegeben werden. Diese strukturierte Protokollierung erlaubt eine nahtlose Integration mit Monitoring- und Analysewerkzeugen wie ELK, Splunk oder spezialisierten Spark SQL-Dashboards. Durch diese Maßnahme wird das Troubleshooting beschleunigt und die Kontrolle über komplexe Produktionsumgebungen erleichtert.
Python-Anwender profitieren mit Spark 4.0 von essentiellen Neuerungen, die die native Arbeit mit PySpark wesentlich vereinfachen und erweitern. Eine herausragende Ergänzung ist die eingebaute Plot-Funktion auf DataFrames, die mit Plotly als Backend arbeitet. Dies erlaubt es, einfache Visualisierungen wie Histogramme oder Streudiagramme direkt aus Spark heraus zu erstellen, ohne den Umweg über das Sammeln der Daten in pandas einlegen zu müssen. Die Integration dieser Visualisierungsfunktion erhöht die Effizienz des Explorativen Data Analysis (EDA) und unterstützt Datenwissenschaftler, schneller Hypothesen zu prüfen und Erkenntnisse zu gewinnen.
Darüber hinaus führt Apache Spark 4.0 eine neue Python Data Source API ein, die es ermöglicht, eigene Datenquellen für Batch- und Streaming-Daten vollständig in Python zu bauen. Das entfernt die bisherige Notwendigkeit, hierfür Scala oder Java programmieren zu müssen und macht Spark als Plattform für eine breitere Entwicklerbasis zugänglicher. Individualisierte Datenformate oder APIs können so direkt ohne fremde Sprachbrücken eingebunden werden. Die Unterstützung polymorpher UDTFs (User-Defined Table Functions) für Python ist eine weitere zukunftsweisende Innovation.
Hiermit lassen sich dynamisch ändernde Tabellenschemata realisieren, was bei variierenden Eingabedaten, wie beispielsweise unterschiedlichen JSON-Strukturen, äußerst praktisch ist. Polymorphe UDTFs können während der Laufzeit ihr Ausgabeformat bestimmen, was komplexe, flexible Datenverarbeitungen in Spark noch leistungsfähiger macht. Ein weiteres Kernstück von Apache Spark ist die Structured Streaming Engine, die mit Version 4.0 wichtige Weiterentwicklungen erfährt. Das neue Arbitrary Stateful Processing API namens transformWithState bietet einen vielseitigen und robusten Ansatz für eigene zustandsbehaftete Streaming-Anwendungen.
Dabei werden Features wie Timer-Handling, TTL (Time-to-Live) für gespeicherte Zustände und komplexe, objektorientierte Logik unterstützt. Die API ist in Scala, Java und Python verfügbar und ermöglicht damit einheitliches Streaming-Design über alle relevanten Programmiersprachen hinweg. Mit dem neu eingeführten State Store Data Source-Reader können State-Daten deutscher Streaming-Jobs als abfragbare DataFrames konsumiert werden. Dies eröffnet bisher unbekannte Transparenz in die inneren Zustandsmechanismen von stateful Streaming-Pipelines und ist ein mächtiges Werkzeug zur Überwachung, Fehlererkennung und Optimierung von Streaming-Aufträgen. Parallel dazu wurden verschiedene State Store-Performancefeatures weiter verbessert, darunter eine effizientere Verwaltung von SST-Dateien (Static Sorted Table), eine neue Checkpoint-Struktur sowie umfangreichere Logging- und Fehlerklassifizierungsmechanismen.
Apache Spark 4.0 dokumentiert damit den Stand einer äußerst aktiven und lebendigen Community, die das Ökosystem aus über 400 individuellen Contributors und namhaften Unternehmen wie Databricks, Apple, LinkedIn, Intel oder OpenAI formt. Insgesamt wurden über 5000 JIRA-Issues geschlossen, was die enorme Innovationskraft und den Einsatz der Entwickler widerspiegelt. Zusätzliche Features wie Unterstützung für Java 21, neue Kubernetes Operatoren, XML-Konnektoren und erweiterte Profiling-Möglichkeiten bei PySpark UDFs runden das Release umfassend ab. Spark 4.
0 ist frei verfügbar und wird standardmäßig in Databricks Runtime 17.0 ausgeliefert, ist jedoch auch als Open-Source-Projekt auf spark.apache.org downloadbar. Für Anwender, die Spark in einer Cloudumgebung testen möchten, bietet Databricks eine kostenlose Community Edition und Testzeiträume an, so dass der Einstieg unkompliziert gelingt.
Angesichts der zahlreichen Verbesserungen in Performance, Skalierbarkeit und Benutzerfreundlichkeit stellt Spark 4.0 eine exzellente Wahl für Unternehmen dar, die ihre Big Data-Architektur zukunftssicher gestalten und gleichzeitig komplexe Analyseaufgaben effizienter bewältigen wollen. Zusammenfassend zeigt Apache Spark 4.0 eindrucksvoll, wie kontinuierliche Innovation Big Data Workflows revolutionieren kann. Die neuen Funktionen in SQL, Python und Streaming sind nicht nur Erweiterungen, sondern durchdachte Werkzeuge, die Entwickler und Data Engineers in die Lage versetzen, anspruchsvolle Anwendungen einfacher zu erstellen, zu warten und zu skalieren.
Indem Spark 4.0 ältere Versionen unterstützt und zugleich neue Programmiersprachen und Technologien integriert, ist es ein bedeutender Schritt in Richtung einer noch breiteren Akzeptanz und vielseitigeren Nutzung von Spark als universelle Datenplattform. Unternehmen, die den Umstieg wagen, profitieren von einer stabileren, sichereren sowie performanteren Umgebung und einem modernen Entwicklungs- und Analyse-Toolkit für die Herausforderungen von morgen.