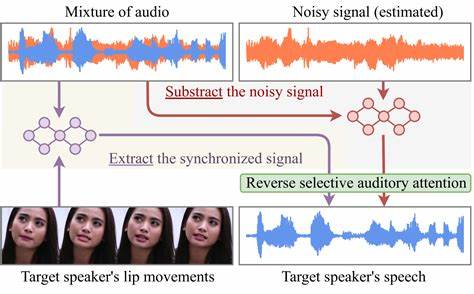
Die Fähigkeit, gezielt die Stimme eines bestimmten Sprechers aus einem Sprachgemisch herauszufiltern, gewinnt in zahlreichen Anwendungen zunehmend an Bedeutung. Ob in virtuellen Assistenten, Hörgeräten, Telekonferenzsystemen oder forensischen Analysen – die zielgerichtete Sprachseparation, auch bekannt als Target Speaker Extraction (TSE), erleichtert das Verstehen und die Verarbeitung einzelner Stimmen in komplexen akustischen Umgebungen erheblich. Bisher galten diskriminative Verfahren als der Standard in diesem Bereich, doch mit der Einführung generativer Methoden eröffnen sich neue Perspektiven für Leistungsfähigkeit und Flexibilität. FlowTSE stellt in diesem Kontext eine vielversprechende, innovative Technik dar, die auf Flow Matching basiert und einige der bisherigen Herausforderungen im TSE-Umfeld adressiert. Im Zentrum der Zielsprecherextraktion steht das Ziel, aus einem akustischen Gemisch die Stimme einer Referenzperson zu isolieren.
Üblicherweise erfolgt dies durch die Bereitstellung eines Beispielsegments der «Zielstimme», das als Orientierung dient. Traditionelle diskriminative Methoden trainieren Modelle anhand von Annotierungen, um Stimmen voneinander zu trennen, doch diese Verfahren stoßen oft an ihre Grenzen, wenn es um Variabilität, Robustheit gegenüber Störgeräuschen oder Phasengenauigkeit geht. Generative Ansätze verfolgen hingegen das Ziel, die zugrundeliegende Wahrscheinlichkeitsverteilung der Zielstimme zu modellieren und dadurch ein realistischeres Extraktionsresultat zu erzielen. FlowTSE nutzt die Methode des conditional flow matching, die ursprünglich aus der jüngeren Entwicklung der generativen Modellierung stammt. Diese Methode benötigt keine komplizierten Vortrainings oder aufwändige Zwischenschritte und reduziert somit den Rechenaufwand sowie die Komplexität des Gesamtsystems.
Das zugrundeliegende Modell erhält als Eingaben Mel-Spektrogramme des Mischungssignals und der Referenzstimme. Dadurch ist es möglich, sehr akkurat die zeitlich-frequenzielle Struktur der Zielstimme zu erfassen und diese vom Gesamtmix zu separieren. Was FlowTSE besonders macht, ist nicht nur seine Effektivität bei der Sprachseparation, sondern auch die neuartige Herangehensweise zur Phasenschätzung. In vielen Anwendungen ist die Rekonstruktion der Phase bei der Sprachwiedergabe entscheidend, um natürliche und verständliche Signale zu erhalten. Übliche Spektralverarbeitungsverfahren konzentrieren sich oft auf die Amplitudeninformation und vernachlässigen Phaseninformationen oder verwenden approximative Methoden.
FlowTSE bietet hierzu einen speziellen Vocoder, der auf der komplexen Kurzzeit-Fourier-Transformation (STFT) des gemischten Signals basiert und so eine realitätsnahe und verbesserte Phasenschätzung ermöglicht. Dies resultiert in einer qualitativ hochwertigen Sprachsynthese, die gerade in Mehrsprecherszenarien hörbar überzeugt. Das Potenzial von FlowTSE zeigt sich auch in den durchgeführten Evaluierungen auf gängigen Benchmark-Datensätzen für die Zielsprecherextraktion. Die Ergebnisse zeigen, dass FlowTSE mit bestehenden, etablierten Methoden mühelos Schritt hält und in vielen Fällen sogar eine überlegene Extraktionsqualität bietet. Dabei gelingt dies trotz der schlankeren Modellarchitektur und der reduzierten Anforderungen an Vortrainingsphasen.
Gerade durch die Kombination von generativer Modellierung und Flow Matching wird eine neue Balance zwischen Effizienz und Effektivität erreicht. Darüber hinaus eröffnet FlowTSE spannende Perspektiven für zukünftige Entwicklungen in der Signalverarbeitung und im Bereich der adaptiven Spracherkennung. Insbesondere die Verbindung von Flow-basierten generativen Modellen mit klassischen Signalverarbeitungstechniken zeigt, dass sich moderne Machine-Learning-Methoden gewinnbringend mit traditionellen Verfahren koppeln lassen, um Herausforderungen wie Mehrfachsprecherszenarien, starke Hintergrundgeräusche oder variierende akustische Bedingungen zu meistern. Ein weiterer Vorteil der FlowTSE-Methode besteht in ihrer Flexibilität hinsichtlich der Referenzsignalart. Das System ist darauf ausgelegt, mit unterschiedlichen Formen von Sprecher-Beispielen zu arbeiten, was den Einsatz in vielfältigen Anwendungsbereichen erleichtert.
Beispielsweise könnten kurze Sprachsamples aus Telefonaten, Hörbüchern oder Sprachmemos als Referenz dienen, um anschließend in Echtzeit die Stimme des entsprechenden Sprechers auch in komplexen Mischungen zielgenau zu isolieren. Ein möglicher Kritikpunkt an generativen Verfahren besteht oft in der erforderlichen Rechenleistung und der daraus resultierenden Latenz bei Echtzeitanwendungen. FlowTSE entgegnet dem durch sein schlankes Design und die Vermeidung komplexer vortrainierter Komponenten. Dies macht FlowTSE nicht nur für Forschungszwecke interessant, sondern bringt es auch in Reichweite praktischer Einsatzszenarien. Die Entwicklung von FlowTSE wirft auch neue Fragen in puncto Datengrundlage und Training auf.
Die Erhebung repräsentativer Sprachmischungen mit entsprechenden Referenzstimmen ist essenziell, um eine robuste Leistungsfähigkeit zu gewährleisten. Gleichwohl zeigen erste Studien, dass das Modell auch bei Stabilität gegenüber verschiedenen Sprechercharakteristika und akustischen Bedingungen vielversprechend abschneidet. Hier könnten künftige Forschungsarbeiten die Datenvielfalt weiter verbessern und das Modell auf neue Szenarien anpassen. Zusammenfassend lässt sich sagen, dass FlowTSE eine bedeutende Weiterentwicklung im Bereich der zielgerichteten Sprachseparation markiert. Die Kombination von Flow Matching mit einem innovativen, auf dem STFT-komplexen Vocoder basierenden Ansatz erleichtert nicht nur die präzise Extraktion des Zielsprechers, sondern verbessert auch die Klangqualität und die Phasengenauigkeit der rekonstruierten Sprache.
Dank seiner Einfachheit und Effizienz stellt FlowTSE eine attraktive Lösung für viele Anwendungen dar, die auf klare Sprachtrennung angewiesen sind. Die Zukunft der Zielsprecherextraktion wird ganz sicher durch solche bahnbrechenden Methoden geprägt werden, die Machine Learning auf eine intelligente und ressourcenschonende Weise mit bewährten Signalverarbeitungstechniken verknüpfen. FlowTSE ist ein Beispiel dafür, wie Forschung und Innovation Hand in Hand gehen, um praktische Herausforderungen in der Audiotechnologie zu meistern und neue Möglichkeiten in der Sprachverarbeitung zu eröffnen.