Im digitalen Zeitalter sind Observability-Systeme unverzichtbar, um die Gesundheit und Leistung komplexer IT-Infrastrukturen im Blick zu behalten. Logs, Metriken und Traces bilden dabei das Rückgrat der Überwachung von Cloud-nativen Anwendungen und Microservices. Die wachsende Datenmenge durch diese Systeme stellt Unternehmen jedoch vor große Herausforderungen – sowohl in Bezug auf die Kosten als auch auf die Handhabung und Integration der Telemetriedaten. Traditionelle SaaS-Observability-Plattformen wie Datadog, New Relic oder Splunk sind zwar weit verbreitet, können bei großem Datenvolumen aber schnell astronomische Kosten verursachen und fragmentieren die Daten in isolierte Silos. Eine immer populärer werdende Alternative ist der Aufbau einer eigenen Observability-Plattform auf Basis eines Data Lakes, meist unter Verwendung von Amazon S3 und Apache Iceberg.
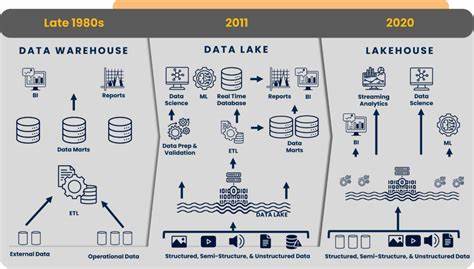
Dieser Ansatz bietet nicht nur erhebliche Kosteneinsparungen, sondern auch maximale Flexibilität und Datenkontrolle. Der grundlegende Vorteil eines Data Lakes gegenüber separaten spezialisierten Tools liegt in der zentralen Speicherung aller Telemetriedaten in einem offenen und skalierbaren System. In der Praxis bedeutet das, dass Logs, Metriken und Traces nicht mehr auf mehrere Systeme verteilt, sondern vereint in einem hochverfügbaren Speichersystem gelagert werden. AWS S3 fungiert als günstiger, langlebiger und nahezu unbegrenzt skalierbarer Speicher, während Apache Iceberg die Datenverwaltung regelt. Iceberg ist ein Open-Source-Tabelleformat, das transaktionale Integrität, Schema-Evolution und leistungsstarke Abfrage-Optimierungen bietet – Funktionen, die klassische Data Lakes oft fehlen.
Im Gegensatz zu SaaS-Plattformen, die meist pro Gigabyte für Speicherung, Ingestion und Analyse bezahlen, nutzt eine selbstgebaute Data-Lake-Observability-Lösung meist ein Pay-as-you-go-Modell für Speicher und On-Demand-Queries, was bei hohen Datenvolumina zu erheblichen Kosteneinsparungen führen kann. Die Speicherung eines Terabyte an Telemetriedaten auf S3 kostet ungefähr 23 US-Dollar pro Monat, während SaaS-Anbieter oft Preise haben, die in die Tausende oder Millionen Dollar im Jahr gehen können. Zusätzlich ist das Elisabeth des Datenaufbewahrungszeitraums bei einer Data-Lake-Lösung deutlich flexibler, was Langzeitanalysen und Compliance-Anforderungen stark entgegenkommt. Das Zusammenspiel von OpenTelemetry für die Datenerfassung, S3 als Data Lake Speicher und Apache Iceberg als Verwaltungsschicht stellt einen modernen Baukasten dar, der nicht nur eine offene Architektur ohne Vendor Lock-in gewährleistet, sondern auch die Nutzung vielfältiger Analyse- und Machine-Learning-Technologien ermöglicht. Die nahtlose Integration von Iceberg mit gängigen Datenverarbeitungs-Engines wie Trino, Presto, Apache Spark oder Amazon Athena erlaubt es, Telemetriedaten in Echtzeit oder für historische Analysen ohne zusätzlichen Aufwand abzufragen.
Überdies unterstützt Iceberg erweiterte Funktionen wie Zeitreisen, mit denen vergangene Datenversionen analysiert werden können – ein Muss für Root-Cause-Analysen und Post-Mortem-Untersuchungen. Ein weiterer entscheidender Vorteil ist die volle Datenhoheit. Unternehmen können ihre Observability-Daten sicher in ihrer eigenen AWS-Umgebung speichern und behalten so vollständige Kontrolle über Zugriff, Sicherheit und Compliance. Dies ist besonders wichtig in regulierten Branchen mit strengen Datenschutzanforderungen oder bei besonderen Sicherheitsbedenken. Die Risiken und Unsicherheiten, deren Daten bei SaaS-Anbietern liegen, entfallen.
Zudem bietet eine eigene Plattform die Freiheit, maßgeschneiderte Analyse-Ansätze umzusetzen und beispielsweise Business-Kontext mit technischen Metriken zu verknüpfen. Die Architektur einer solchen Plattform beginnt bei der Erfassung aller relevanten Telemetriedaten aus Anwendungen, Microservices und Host-Systemen. OpenTelemetry Collector und vergleichbare Tools bilden die Grundlage, um Logs, Metriken und Traces in eine einheitliche Pipeline zu speisen. Die Streaming-Daten können über Dienste wie Kafka, AWS Kinesis Data Firehose oder Fluent Bit transportiert und in S3 abgelegt werden. Anschließend sorgt ein Data-Processing-Framework, zum Beispiel Apache Flink oder AWS Glue, für die Umwandlung und Organisation in Iceberg-Tabellen.
Dabei werden Daten partitioniert, komprimiert und mit Metadaten versehen, um die Effizienz bei Abfragen zu steigern. Für die Analyse bieten sich vielseitige Werkzeuge an. SQL-basierte Engines wie Amazon Athena oder Trino erlauben interaktive Abfragen mit geringer Latenz, ideal für Dashboards, Monitoring und Troubleshooting. Für komplexere Berechnungen und Machine-Learning-Anwendungen kommen Apache Spark oder andere Big-Data-Frameworks zum Einsatz. Visualisierungstools wie Grafana oder Amazon QuickSight greifen direkt über die SQL-Schnittstellen auf die Daten zu und können individuelle Dashboards und Alerts bereitstellen.
Diese Modularität stärkt die Flexibilität und ermöglicht es Teams, die Lösungen exakt auf ihre Anforderungen zuzuschneiden. Obwohl dieser Ansatz viele Vorteile bietet, sollte man sich der Herausforderungen bewusst sein. Der Aufbau und Betrieb einer eigenen Observability-Plattform erfordert technisches Know-how und den Aufwand, eine robuste Architektur zu gestalten und zu warten. Zudem müssen Schnittstellen und Benutzeroberflächen entwickelt oder integriert werden, da nicht alle Funktionen eines SaaS-Pakets von Haus aus gegeben sind. Trotzdem wird dieser Mehraufwand durch den signifikanten Kostenvorteil, die Kontrolle über kritische Daten und die Zukunftssicherheit ausgeglichen.
Ein weiterer Aspekt ist die Performance. SaaS-Plattformen sind häufig auf hohe Geschwindigkeit bei Abfragen optimiert, was bei einer Data-Lake-Architektur durch spätere Datenverarbeitung und Latenz beim Zugriff auf Speichersysteme etwas eingeschränkt sein kann. Um dem zu begegnen, kombinierten einige Unternehmen ihren Data Lake mit spezialisierten OLAP-Engines wie Apache Pinot für Echtzeit-Daten oder nutzen Caching-Mechanismen für aktuelle Daten. So gelingt eine Balance zwischen Kosteneffizienz, Flexibilität und Geschwindigkeit. Aus strategischer Sicht ist die Entwicklung einer eigenen Observability-Plattform mit Data Lake-Technologien ein Zukunftsmodell.
Es transformiert Telemetrie von einer Kostensenkungsnotwendigkeit zu einem wertvollen Daten-Asset. Die entstehende Plattform wird zum Fundament für weiterführende Anwendungsfälle jenseits von Monitoring, wie Sicherheitsanalysen, Business Intelligence oder KI-gestützte Anomalieerkennung. Die offene Architektur und die breite Community hinter Apache Iceberg und OpenTelemetry sichern Innovation und Weiterentwicklung. Für Entscheidungsträger bietet der Ansatz ein schlüssiges Gesamtpaket. Die potenziellen Einsparungen bei den Betriebskosten können sich schnell amortisieren, während das Unternehmen gleichzeitig durch den Verzicht auf Anbieterabhängigkeiten und die Möglichkeit zur eigenen Datenanalyse an Agilität gewinnt.
Zudem ermöglicht die längere Datenaufbewahrung umfangreichere historische Einblicke und eine bessere Einhaltung von Compliance-Vorgaben. Die technische Umsetzung beginnt mit einer sorgfältigen Planung der Datenarchitektur, Einbindung der Telemetriequellen und Auswahl des passenden Datenverarbeitungs- und Analyse-Stacks. Die Integration der verschiedenen Komponenten wie OpenTelemetry Collector, Kafka, AWS S3, Apache Iceberg und Abfrage-Engines erfordert ein abgestimmtes Zusammenspiel, das durch Automatisierung und Monitoring unterstützt wird. Die Nutzung von Cloud-Services bietet dabei Skalierbarkeit und Ausfallsicherheit. Zusammenfassend lässt sich sagen, dass eine selbstentwickelte Observability-Plattform mit Data Lake-Architektur ein mächtiges Instrument für Unternehmen ist, die große Mengen von Telemetriedaten effizient, kostengünstig und flexibel verwalten möchten.
Indem sie auf offene Standards und Technologien wie AWS S3 und Apache Iceberg setzen, entkommen sie teuren SaaS-Modellen und gewinnen gleichzeitig leistungsfähige Analysefähigkeiten. Die eigene Plattform ist der Schlüssel zu vollständiger Datenkontrolle, langfristiger Speicherung und innovativen Analyseverfahren – Grundvoraussetzungen für einen zukunftssicheren IT-Betrieb und eine datengetriebene Unternehmenskultur.