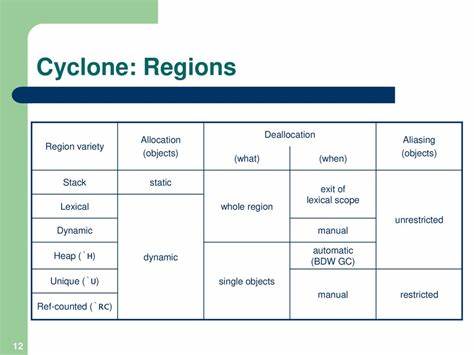
Die rasante Entwicklung großer Sprachmodelle, bekannt als Large Language Models (LLMs), hat die Technologiewelt in den letzten Jahren revolutioniert. Während diese KI-gestützten Werkzeuge zunehmend in der Softwareentwicklung Einzug halten, stellt sich für viele Entwickler die Frage, welche Auswirkungen sie konkret auf ihre Arbeitsweise und ihre bevorzugten Programmiersprachen haben. Insbesondere die Elixir-Community, die für ihre funktionale Programmierung, Skalierbarkeit und Fehlertoleranz bekannt ist, steht an einem Scheideweg. Handelt es sich bei LLMs um einen unverhofften Gewinn, der neue Möglichkeiten eröffnet, oder um eine potenzielle Gefahr, die etablierte Praktiken und die Bedeutung der Sprache infrage stellt? Diese Frage verdient eine sorgfältige Betrachtung, um den Status quo und die Zukunft von Elixir im Kontext der KI-getriebenen Entwicklung zu verstehen. Elixir hat sich als eine der besten universellen Programmiersprachen etabliert, besonders geeignet für hochverfügbare, parallele und verteilte Systeme.
Entwickler schätzen seine robuste Infrastruktur basierend auf der Erlang Virtual Machine und die Fähigkeit, Fehlertoleranz durch Supervisorbäume wirksam zu implementieren. Doch trotz dieser Stärken droht Elixir ins Abseits zu geraten, wenn die Mehrzahl der Entwickler künftig aufgrund von LLM-Empfehlungen eher zu Mainstream-Technologien wie Node.js oder Python greifen. Ein häufig diskutiertes Szenario ist das sogenannte „Vibe Coding“, bei dem Entwickler mehr oder weniger blind den Vorschlägen von KI-Assistenten wie ChatGPT oder Claude folgen. Dabei stützen sich diese LLMs oft auf populäre, breit nutzbare Frameworks und Ökosysteme, die leichter in ihre Trainingsdaten eingebunden sind.
Dies führt zu einem gewissen Konformitätsdruck im Entwicklerumfeld. Auf den ersten Blick könnte dies als Bedrohung für Elixir interpretiert werden, da viele neuere Entwickler aufgrund einer vermeintlich unkomplizierten KI-Hilfe sich eher für Technologien entscheiden, die von KI-Tools besser unterstützt werden und somit vermeintlich schneller Ergebnisse liefern. Allerdings zeigt die bisherige Entwicklung von LLMs auch, dass diese besonders dann ihre Stärken ausspielen, wenn sie als Übersetzer oder Synthesizer von bereits bekanntem Wissen agieren. Komplexe, spezialisierte Anforderungen verlangen jedoch oft eine tiefere Expertise und sind nicht ausschließlich mit standardisierten KI-Antworten zu bewältigen. Genau hier ist Elixir im Vorteil.
Die Sprache wurde konzipiert, um bei komplexen Anwendungsfällen verlässlich zu performen. Dies ist ein „Wall-Hitting“-Effekt, der Entwickler dazu zwingt, sich mehr mit den Grundlagen auseinanderzusetzen, anstatt sich blind auf automatisierte Vorschläge zu verlassen. Anstatt die Elixir-Community zu verdrängen, könnte die KI vielmehr Entwicklungen anstoßen, die dazu führen, dass LLMs in der Lage sind, gezielt Elixir als passende Lösung für anspruchsvolle Probleme vorzuschlagen. Damit das gelingt, ist notwendig, dass die Elixir-Community aktiv in die Weiterentwicklung und Integration von LLMs investiert. Nur so kann sichergestellt werden, dass die KI-Modelle Elixir nicht nur verstehen, sondern auch effektiv zu dessen Verbreitung beitragen.
Ein innovativer Ansatz dabei ist beispielsweise die Einbindung von speziellen Protokollen und Servern wie Tidewave, die es ermöglichen, einem LLM den direkten Zugang zum laufenden Anwendungskontext zu bieten. Statt sich auf veraltete oder generische Dokumentationen zu verlassen, kann das Modell so reale Zustände einer Anwendung auslesen, Code-Snippets ausführen oder Datenbankabfragen in Echtzeit tätigen. Dies erhöht die Qualität der automatisch generierten Antworten und macht die Zusammenarbeit zwischen Entwickler und KI-Tool deutlich produktiver. Außerdem eröffnet die Kombination von Elixir mit LLMs spannende Perspektiven weit über die reine Codegenerierung hinaus. Elixir’s Philosophie von Fehlertoleranz und verteilten Systemen harmoniert hervorragend mit den Anforderungen moderner KI-basierter Anwendungen.
Persistent Conversation Systems, bei denen der Kontext über längere Dialoge hinweg gehalten wird, oder AI-Agenten-Architekturen lassen sich durch Elixirs OTP-Prinzipien besonders effizient umsetzen. Die Fähigkeit, verschiedene Prozesse zu koordinieren und unvorhergesehene Fehler kontrolliert zu behandeln, macht Elixir zu einem vielversprechenden Werkzeug für die Entwicklung robuster KI-Systeme. Wichtig ist jedoch, dass LLMs nicht als allwissende Orakel betrachtet werden dürfen. Häufig entstehen durch automatisierte Antworten sogenannte „Halluzinationen“, also fehlerhafte oder unlogische Ergebnisse, die auf mangelndem Kontext beruhen. Entwickler müssen lernen, KI-gestützte Empfehlungen kritisch zu bewerten und durch eigene Recherche oder gezielte Kontext-Einbettung zu validieren.
Ein potenzieller Gamechanger kann hier die Community sein: Durch das Konzept, für spezifische Elixir-Bibliotheken eigene „usage-rules.md“-Dateien zu schaffen, lassen sich wichtige Nutzungshinweise klar und knapp zusammenfassen. Diese könnten direkt von LLMs verarbeitet werden, um idiomatisch korrekten und an den jeweiligen Coding-Standards ausgerichteten Code zu generieren. Ein solcher gemeinschaftlich erarbeiteter Standard würde dabei helfen, die Qualität der KI-Assistenz auf eine neue Ebene zu heben. Darüber hinaus bieten sich für die Elixir-Community Möglichkeiten, spezielle Evaluations-Datensätze zu entwickeln.
Benchmarking von LLMs anhand realer Elixir-Szenarien wie GenServer-Supervision, LiveView-Interaktionen oder Ecto-Datenbankabfragen kann dazu beitragen, Modelle gezielt zu trainieren und zu vergleichen. Gerade Elixirs Laufzeitumgebung bietet sich an, um umfangreiche Performance-Tests und Fehlerfallprüfungen automatisiert durchzuführen. Solche Initiativen könnten nicht nur die Qualität der KI-Modelle für Elixir steigern, sondern auch deren Reputation professionell fördern. Die Frage, ob LLMs als Windfall oder Deathblow für Elixir zu sehen sind, lässt sich nicht pauschal beantworten. Vielmehr handelt es sich um eine Chance zur Transformation und Innovation.