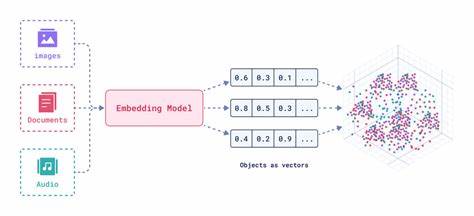
Maschinelles Lernen hat in den letzten Jahren zahlreiche Fortschritte gemacht und dabei vor allem mit textgenerierenden Modellen wie GPT, Gemini oder Claude Aufmerksamkeit erregt. Doch eine andere, weniger beachtete Technologie hat das Potenzial, die Arbeitsweise technischer Redakteure nachhaltig zu verändern: Embeddings. Diese Methode, Texte in numerische Vektoren zu übersetzen, eröffnet völlig neue Möglichkeiten der Informationsverknüpfung, Analyse und Verarbeitung – auf einer Dimension, die zuvor für Menschen unerreichbar war. Embeddings sind keine völlig neue Erfindung, doch ihre breite Verfügbarkeit und Zugänglichkeit sind erst in den letzten Jahren zu einem echten Game-Changer für technische Redakteure geworden. Im Kern erlauben Embeddings, die semantische Bedeutung von Texten in Form von Zahlenarrays – sogenannten Vektoren – abzubilden.
Dabei ist bemerkenswert, dass unabhängig von der Länge des Eingangstextes immer Vektoren gleicher Größe ausgegeben werden, was den Vergleich und die Ordnung unterschiedlicher Texte auf mathematisch saubere Weise ermöglicht. Dieses Prinzip eröffnet eine völlig neue Art der Dokumentenstrategie. Technische Dokumentationen bestehen oft aus zahlreichen, komplex verschachtelten Seiten, die für Leser schwer zu durchdringen sind. Mit Embeddings jedoch lassen sich verwandte Dokumente oder Abschnitte automatisch identifizieren, verlinken und sogar inhaltlich zusammenfassen. So können Empfehlungssysteme entstehen, die den Nutzer gezielt und effizient zu relevanten Inhalten führen – ähnlich wie bei einer hochwertigen Navigation, nur viel intelligenter und dynamischer.
Die Praxis zeigt, dass solche Systeme bereits heute bei ausgewählten Dokumentationsseiten gute Ergebnisse erzielen. Zum Beispiel kann für jede einzelne Seite ein Embedding generiert werden. Anschließend werden alle Seitenvektoren miteinander verglichen – sind zwei Vektoren einander semantisch ähnlich, so sind ihre Inhalte vermutlich eng verwandt. Dadurch kann ein automatisches Empfehlungsnetzwerk entstehen, bei dem Leser auf weiterführende Dokumente hingewiesen werden, die auf herkömmliche Weise schwer zu finden wären. Technisch gesehen basiert das Generieren von Embeddings auf neuronalen Netzwerken, insbesondere auf sogenannten Transformermodellen.
Diese Modelle lernen anhand großer Textmengen, Worte und Sätze in einem hochdimensionalen Raum zu verorten – ein Raum mit hunderten oder sogar tausenden Dimensionen. Diese Mehrdimensionalität ist für den Menschen schwer vorstellbar, jedoch ermöglicht sie den Computern eine äußerst feine Granularität bei der Erfassung von Bedeutungen, Zusammenhängen und Ähnlichkeiten. Eine berühmte Illustration aus der Forschung zeigt, wie analogienartige Operationen in diesem Vektorraum funktionieren können: Wenn man vom Vektor „König“ den Vektor „Mann“ subtrahiert und den Vektor „Frau“ addiert, erhält man annähernd den Vektor „Königin“. Solche Phänomene verdeutlichen, dass Embeddings nicht nur Worte, sondern auch komplexe semantische Relationen abbilden können. Für technische Redakteure bedeutet das konkret, dass sie ihre Dokumente nicht nur übersichtlich strukturieren, sondern auch mit semantischen Metadaten anreichern können, ohne selbst tief in die Mathematik der Vektoroperationen einzutauchen.
Moderne Anbieter stellen APIs und SDKs bereit, die das Embedding von Texten erleichtern. Entwickler und Redakteure können so unkompliziert eigene Systeme zur Inhaltsanalyse, Suche oder Empfehlung implementieren. Ein wichtiger Faktor bei der Auswahl eines Embedding-Modells ist die Größe des akzeptierten Texteingangs. Manche Modelle können nur kurze Textabschnitte verarbeiten, was in der Praxis die Anwendung einschränkt. Andere Modelle, wie etwa das „voyage-3“ Modell von Voyage AI, erlauben die Verarbeitung von deutlich längeren Texten, was insbesondere für technische Dokumente mit hohem Umfang von Vorteil ist.
Es empfiehlt sich, die individuellen Anforderungen mit den Möglichkeiten der jeweiligen Modelle in Einklang zu bringen. Neben der technischen Infrastruktur spielen auch ökonomische und ökologische Aspekte eine Rolle. Die Kosten für das Generieren von Embeddings sind im Vergleich zu komplexen Textgenerierungen gering, was die Technologie für viele Unternehmen zugänglich macht. Hinsichtlich des Energieverbrauchs sind embeddings weniger ressourcenintensiv als das Training großer Sprachmodelle, jedoch entsteht beim Training dieser Modelle natürlich ein gewisser CO2-Fußabdruck. Die Wissenschaft arbeitet kontinuierlich an nachhaltigerer KI und deren effizienterer Nutzung.
Die Einsatzgebiete von Embeddings innerhalb der technischen Dokumentation sind vielfältig und reichen von verbesserten Suchfunktionen bis hin zu automatischer Inhaltsvernetzung und Qualitätskontrolle. Beispielsweise können Embeddings fehlende Verweise zwischen Dokumenten identifizieren oder semantische Duplikate aufdecken. Die Integration solcher automatischer Verfahren entlastet Redakteure, erlaubt fokussiertes Arbeiten und verhindert redundante Inhalte in komplexen Dokumentensammlungen. Eine besonders interessante Perspektive ist die Bereitstellung von Embeddings als offene Daten innerhalb von Organisationen oder auch öffentlich zugänglich über APIs. Dies könnte den Aufbau ganzer Ökosysteme fördern, in denen verschiedene Werkzeuge und Systeme semantisch auf die gleiche Dokumentationsbasis zugreifen, wodurch innovative Anwendungen und verbesserte Nutzererfahrungen möglich werden.
Der Übergang von traditionellen textbasierten Such- und Navigationsmechanismen hin zu embeddings-gestützten semantischen Systemen markiert einen Paradigmenwechsel. Er legt die Grundlage für eine neue Qualität der Informationsrecherche, die weniger von Schlüsselwörtern als von Bedeutung und Kontext geleitet wird. Dies erhöht die Relevanz der Suchergebnisse und spart den Nutzern Zeit und Frustration. Es lohnt sich daher für Organisationen, die technischen Dokumentationsbereich ernst nehmen, die Embeddings-Technologie zumindest experimentell zu erkunden. Die Hürde ist vergleichsweise niedrig, zudem existieren zahlreiche frei zugängliche Modelle und offizielle Schnittstellen.
Wer frühzeitig auf diesen Zug aufspringt, kann sich Wettbewerbsvorteile sichern und die eigene Dokumentationsarbeit auf ein neues Level heben. Abschließend lässt sich sagen, dass Embeddings für die technische Dokumentation mehr sind als nur ein weiteres Tool. Sie sind ein intelligenter Hebel, mit dem sich die schier unüberschaubaren Informationsmengen systematisch in Beziehung setzen lassen. Sie bringen die Chance, Dokumentationen nicht nur besser zugänglich zu machen, sondern sie auch dynamischer, lernfähiger und damit zukunftsfähiger zu gestalten. Auch wenn die mehrdimensionalen Vektorräume und die mathematischen Grundlagen zunächst abstrakt erscheinen, sind Embeddings letztlich ein praktisches und handhabbares Mittel.
Sie bieten eine tiefergehende semantische Ebene für den Umgang mit Text, die sich jeder technische Redakteur zunutze machen kann – ganz ohne eine Ausbildung in Mathematik oder Programmierung. Die Zukunft der technischen Dokumentation ist also nicht einfach nur automatisch generierter Text. Sie ist vielmehr die intelligent vernetzte, semantisch verankerte und nutzerzentrierte Dokumentation, in der Embeddings eine zentrale Rolle spielen werden. Wer diese Entwicklung jetzt mitgestaltet, stellt sicher, dass technische Informationen auch morgen noch schnell, präzise und verständlich gefunden werden.



![The process of making a camera lens [video]](/images/1727AF49-A253-4E9F-BB08-B164997D2CD1)