In der heutigen Zeit, in der Cyberangriffe und Sicherheitsvorfälle immer komplexer werden, ist der Umgang mit Sicherheitsprotokollen eine zentrale Herausforderung für Unternehmen. Sicherheitsinformationen stammen aus unterschiedlichsten Quellen – von Firewalls über Cloud-Plattformen bis hin zu Web Application Firewalls (WAF) und Netzwerk-Flow-Logs. Die schiere Menge und Vielfalt der Daten macht es erforderlich, diese effizient zu verarbeiten und auszuwerten. Genau hier setzen maßgeschneiderte Pipelines für das ETL von Sicherheitsprotokollen an, die es ermöglichen, Daten prozessual bestmöglich aufzubereiten und für die Analyse vorzubereiten. ETL steht für Extract, Transform, Load und beschreibt den Prozess, bei dem Rohdaten zunächst extrahiert, dann transformiert und bereinigt sowie letztlich in ein Zielsystem geladen werden.
Für Security-Logs bedeutet das, dass die oftmals chaotischen und heterogenen Rohdaten aus verschiedenen Systemen in ein einheitliches, sauberes Format gebracht werden, angereichert mit relevanten Kontextinformationen und anschließend zur Detektion und Analyse bereitgestellt werden. Ohne eine leistungsfähige Pipeline, die flexibel angepasst werden kann, erfüllen viele Security-Systeme nicht ihre volle Wirkung, weil sie entweder mit zu vielen irrelevanten Daten überlastet sind oder wichtige Hinweise übersehen. Die Herausforderung besteht darin, die unterschiedlichen Anforderungen von Sicherheitsabteilungen zu bedienen. Firewall-Logs müssen beispielsweise anders verarbeitet werden als WAF-Logs oder Netzwerkflussdaten. Unternehmen wünschen sich oft, dass sie spezifische Felder filtern oder transformieren können, bevor diese in nachfolgenden Schritten weiterverarbeitet werden.
Ein Beispiel hierfür ist, nur Logs von bestimmten Containern in einer Cloud-Infrastruktur herauszufiltern oder interne Netzwerkflüsse zu ignorieren, um den Datenmüll zu reduzieren. Ohne flexible Pipelines, in denen Filter, Anreicherung und Erkennungsregeln genau in der richtigen Reihenfolge platziert werden können, bleibt diese Feinsteuerung oft unmöglich. Eine besonders große Herausforderung stellen Netzwerkflussdaten (Flow Logs) dar. Diese Logs sind enorm umfangreich, denn sie zeichnen Verbindungen zwischen IPs kontinuierlich auf. Gleichzeitig enthalten sie wertvolle Hinweise darauf, ob sich unerwünschte oder unerwartete Verbindungen im Netzwerk etablieren.
Die klassische Pipeline-Reihenfolge sieht meist zuerst eine Transformation und Anreicherung der Logs vor, anschließend eine Filterung, danach erfolgt die Detektion und am Ende die Speicherung. Doch gerade bei Flow Logs ist dieses Vorgehen problematisch, da zum Beispiel Netzbereiche oder Autonomous System Names allein wenig über die Relevanz der Verbindungen aussagen. Ein intelligenterer Ansatz ist, zuerst spezifische Detektionsregeln anzuwenden, um potenziell verdächtige IP-Adressen wie Tor Exit Nodes oder bekannte bösartige IPs zu identifizieren, und erst danach die Filter zum Datenreduzieren anzuwenden. Dadurch wird sichergestellt, dass relevante Ereignisse nicht versehentlich aussortiert werden. Die Möglichkeit, Pipelines per Drag-and-Drop zusammenzustellen, ist ein großer Fortschritt bei der Benutzerfreundlichkeit.
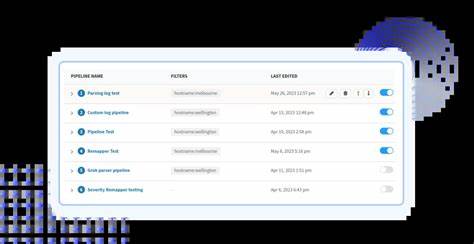
Sicherheitsanalysten können so schnell und ohne großen Programmieraufwand individuelle Log-Verarbeitungsprozesse erstellen. Dabei kann die Reihenfolge der einzelnen Schritte wie Filtern, Anreichern oder Detektieren beliebig angepasst werden, um die besten Ergebnisse zu erzielen. Ebenfalls wichtig ist die Einrichtung sogenannter „Topics“ innerhalb der Pipeline-Umgebung. Ein Topic definiert Bedingungen, unter denen Logs einem bestimmten Pipeline-Prozess zugewiesen werden. So lassen sich etwa nur AWS Flow Logs in eine speziell darauf abgestimmte Pipeline leiten, während andere Logs separat verarbeitet werden.
Diese flexible Zuweisung sorgt dafür, dass jedes Log genau passend zum Quellsystem und Einsatzzweck behandelt wird. Der Nutzen maßgeschneiderter Pipelines ist vor allem in der Kosten- und Effizienzersparnis sichtbar. Beispielsweise konnten Unternehmen durch gezieltes Filtern der Flow Logs den Datenaufwand von über 40 Megabyte pro Stunde auf unter 5 Megabyte pro Stunde reduzieren, ohne wertvolle Sicherheitsinformationen zu verlieren. Dies wirkt sich direkt auf Speicher- und Analysekosten aus, was für viele Unternehmen ein entscheidender Wettbewerbsvorteil ist. Gleichzeitig erhöht sich die Trefferqualität der Detektionsmechanismen, da irrelevante Daten vorher sorgfältig aussortiert sind.
Ein weiteres Highlight ist die umfassende Nachvollziehbarkeit innerhalb der Pipelines. Jeder verarbeitete Log trägt Informationen darüber, welche Pipeline und welches Topic es durchlaufen hat. Das steigert die Transparenz und erleichtert die Fehlersuche beziehungsweise die Optimierung der Pipeline-Prozesse. Unternehmen behalten so stets den Überblick darüber, wie ihre Daten verarbeitet wurden, was in sicherheitskritischen Umgebungen ein nicht zu unterschätzender Vorteil ist. Die Zukunft der Pipelines für das ETLing von Sicherheitsprotokollen ist spannend.
Mittelfristig wird geplant, die Funktionalitäten noch stärker auf verschiedene Zielsysteme auszudehnen. Multi-Writing Ansätze ermöglichen es, Logs gleichzeitig in unterschiedliche Speicherumgebungen oder Hot-Cold-Architekturen zu schreiben, um sowohl schnelle Suche als auch kosteneffiziente Langzeitspeicherung zu ermöglichen. Darüber hinaus wird mit der Integration von „Pipelines as Code“ ein weiterer Schritt getan, bei dem Pipelines mittels Code-Versionierung und Automatisierung direkt in Entwicklungsprozesse eingebunden werden können. Das erlaubt Security-Teams eine noch höhere Automatisierung und Nachvollziehbarkeit bei der Verwaltung ihrer Datenströme. Die Automatisierung wird zudem durch den Einsatz von AI-gestützten Agents ergänzt, die bereits bei der Erzeugung und Analyse von Sicherheitsprotokollen wegweisend sind.
Diese native AI-Technologie hilft Sicherheitsanalysten, Log-Daten schneller zu untersuchen, indem sie etwa repetitive Aufgaben übernimmt und Analysezeiten drastisch reduziert. Durch die Kombination aus flexiblem Pipeline-Management und intelligenter KI-Unterstützung entsteht eine zukunftssichere Plattform für moderne Security Operations Centers (SOCs). Ein maßgeschneidertes Pipeline-System bietet Unternehmen somit die Möglichkeit, ihre Sicherheitsdaten nicht nur in großer Menge, sondern auch mit hoher Qualität zu verwalten. Sie können differenzierte Regeln für einzelne Log-Typen festlegen und so sicherstellen, dass keine wichtige Information untergeht und unnötige Datenlast verringert wird. Dadurch wird sowohl die Erkennung von komplexen Bedrohungen verbessert als auch die Gesamtkosten gesenkt.
Die Freiheit, eigene Pipelines zu erstellen und anzupassen, hilft Unternehmen, auf Veränderungen im Bedrohungsumfeld schnell zu reagieren und zudem regulatorische Anforderungen besser zu erfüllen. Das stetige Wachstum an Datenmengen und die Zunahme anspruchsvoller Angriffe machen individuelle ETL-Pipelines zu einem unverzichtbaren Werkzeug in der Cyber-Sicherheitswelt. Unternehmen, die frühzeitig auf solche Lösungen setzen, profitieren von einer deutlich effizienteren Nutzung ihrer Ressourcen, einer höheren Sicherheit und der Fähigkeit, schnell und gezielt auf Vorfälle zu reagieren. Die flexible Verarbeitung von Sicherheitsprotokollen stellt somit eine strategische Investition in die Zukunft der IT-Sicherheit dar. Zusammenfassend lässt sich sagen, dass maßgeschneiderte Pipelines für das ETLing von Sicherheitsprotokollen die Art und Weise revolutionieren, wie Unternehmen ihre Sicherheitsdaten sammeln, aufbereiten und analysieren.
Sie bieten maximale Kontrolle, maßgeschneiderte Verarbeitungsschritte, Transparenz und wertvolle Kosteneinsparungen. Gleichzeitig ebnen sie den Weg für die Integration moderner Technologien wie künstlicher Intelligenz und DevOps-Praktiken. Für Security-Teams jeder Größe sind diese Pipelines ein entscheidender Baustein auf dem Weg zu einem effektiven und zukunftssicheren Sicherheitsmanagement.



![Episode 1: Decoding Pentest Findings: Accept or Reject? [video]](/images/F3156A21-EE7A-4DFB-8957-2B89DA1D5156)