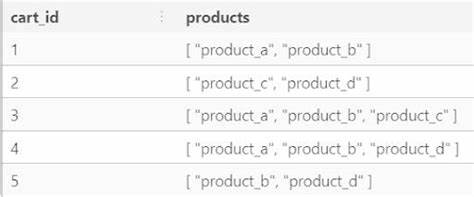
PostgreSQL ist eine der beliebtesten Open-Source-Datenbanken der Welt und bietet zahlreiche Funktionen, die Entwicklern Flexibilität und Leistungsfähigkeit garantieren sollen. Doch wie bei vielen hochkomplexen Systemen lauern auch hier einige Fallstricke, die sich erst bei realem Einsatz offenbaren – insbesondere bei der Nutzung von Arrays in Datenbankschemata. In letzter Zeit wurde immer wieder diskutiert, wie sich die Speicherung großer Datenmengen in Array-Feldern vom Typ bytea[] auf die Performance und den Speicherverbrauch auswirkt. Das Verständnis der zugrunde liegenden Mechanismen ist für Datenbankentwickler und Systemarchitekten essenziell, um kostspielige Fehler im Betrieb zu vermeiden. Bei klassischen relationalen Datenbanken geht es vor allem darum, Daten möglichst normalisiert zu speichern, also sie in vielen kleinen Tabellen mit klaren Beziehungen abzubilden.
Manchmal werden aus Gründen der Bequemlichkeit oder Performance Arrays verwendet, um mehrere Werte in einem Feld zusammenzufassen. Diese scheinbar praktische Lösung kann bei bytea-Arrays – also Arrays von Binärdaten – allerdings zu erheblichen Problemen führen. Der Grund liegt im internen Umgang von PostgreSQL mit solchen Feldern und der Art und Weise, wie Updates in der Datenbank umgesetzt werden. Unser Ausgangspunkt ist eine reale Nutzungssituation: Ein Team implementierte eine Anwendung für Spracherkennung und Übersetzung, bei der Audiodaten in der Datenbank abgelegt werden sollten. Sie entschieden sich, einzelne Upload-Segmente als bytea[]-Array in einer Spalte zu speichern, um die Übertragung und Speicherung in kleinen Stücken zu verwalten.
Anfangs schien dieser Ansatz sinnvoll und einfacher – doch das Ergebnis zeigte sich als Albtraum: Eine einzelne Datenbankzeile wuchs auf mehr als 1,2 GiB an und die gesamte Datenbank benötigte über 27 GiB – für nur wenige solcher Datensätze. Die Ursachenforschung offenbarte die eigentliche Falle: Das Anfügen neuer bytea-Blöcke an ein Array erfolgt durch das Erstellen eines komplett neuen Arrays. PostgreSQL kann bestehende Arrays nicht in-place modifizieren, sondern legt jedes Mal eine neue Version des gesamten Arrays an. Dabei werden nicht nur die neuen Daten gespeichert, sondern das komplette bisherige Array immer wieder kopiert. Dies führt nicht nur zu massivem Speicherverbrauch, sondern auch zu einer stark zunehmenden Anzahl an sogenannten „dead tuples“ – alten, nicht mehr genutzten Versionen, die dank PostgreSQLs Multiversion Concurrency Control (MVCC) nicht sofort gelöscht werden.
Die Folge sind enorme Mengen an Müll, der erst durch den VACUUM-Prozess aufgeräumt wird. Die Konsequenz zeigt sich in einer quadratischen Wachstumsdynamik des Speicherverbrauchs: Mit jeder weiteren Anpassung wächst die Datenmenge nicht linear, sondern überproportional, da jede Änderung eine neue Komplettkopie erzeugt. Tests mit unterschiedlich großen bytea-Stücken bestätigten dieses Verhalten eindrucksvoll. Somit wurde klar, dass die scheinbar einfache Array-Anhängung eine versteckte Bedrohung für jeden PostgreSQL-Anwender mit großen Binärdaten im Array darstellt. Das Bewusstsein für die Funktionsweise von PostgreSQL ist wichtig: Jede Änderung an einer Datenreihe erzeugt eine neue Version und markiert die alte als veraltet.
Der automatische Aufräumprozess namens VACUUM sorgt dafür, dass ungenutzte Datenfragmente früherer Versionen entfernt werden, aber das passiert nicht sofort und vollautomatisch. Bei häufigen, großen Updates an einem einzelnen Feld, wie hier bytea[] Arrays, kann die Datenbank schnell mit totem Ballast überladen werden, was sich in exzessiver Festplattenbelegung und Performance-Einbußen niederschlägt. Das Team probierte zunächst VACUUM und sogar VACUUM FULL aus, um die Datenbank von überflüssigem Ballast zu befreien. Während VACUUM Full definitiv den Speicher drastisch reduzieren konnte, zeigte sich, dass das Warten auf diesen Prozess keine langfristige Lösung für die grundlegende Problematik ist. Denn ohne Designänderung erneuert sich der Speicherverbrauch bei jeder neuen Anhängung erneut.
Die entscheidende Erkenntnis war, dass der Ansatz, große Binärdaten innerhalb eines Arrays in einer einzigen Zeile zu speichern, grundsätzlich ungeeignet ist. Stattdessen sollte der Datenbankentwurf auf Normalisierung ausgelegt sein. Anstatt ein langes bytea[]-Feld fortlaufend zu ergänzen, ist es deutlich effizienter, jede hochgeladene Datenstück als eigene Zeile in einer separaten Tabelle zu speichern. Dies erlaubt es PostgreSQL, mit kleineren, einzelnen Zeilen zu arbeiten, die lediglich eingefügt werden, statt bei Updates große Datenmengen neu zu speichern. Die neue Struktur stellt jeder Datei eine eigene ID zur Verfügung und verwaltet die einzelnen Upload-Stücke mit einem Reihenindex, sodass die Daten später in der richtigen Reihenfolge zusammengesetzt werden können.
Diese Normalisierung reduziert nicht nur den Speicherverbrauch signifikant, sondern verbessert auch die Speed beim Schreiben und Lesen, da Inserts grundsätzlich eine Stärke von PostgreSQL sind. Zusätzlich zeigt der Fall, wie wichtig Produktionsmonitoring ist. Alerts über erhöhten CPU-Verbrauch, I/O-Verzögerungen und Disk-Latenzen können frühzeitig auf kritische Probleme hinweisen und verhindern so einen Serverausfall oder Datenverlust. Hier bewies sich die Wahl eines Tools mit SMS-Benachrichtigungen als Gold wert. Vom Engineering lernen wir außerdem, dass Überwachung und Fehleranalyse nur erfolgreich sind, wenn man Infrastruktur, Anwendungscode und Datenbankkonfiguration als zusammenhängendes Ganzes betrachtet.
Fehlende Analytik kann hier durch qualitatives Feedback ergänzt werden – dennoch dürfen grundlegende Monitoring-Tools nicht fehlen. Aus Entwicklersicht war ein interessanter Nebenaspekt die Fehlfunktion eines UI-Frameworks. Ein Bug in SwiftUI sorgte dafür, dass Aufnahmen nicht korrekt gestoppt wurden, wenn die Benutzer mehrere Berührungen gleichzeitig durchführten. Dies führte dazu, dass mehrere Stunden unkomprimierte Audiodaten ungeplant gespeichert wurden. Diese Erkenntnis unterstreicht, wie wichtig umfassendes Testen und das Verständnis von tiefgehenden UI-Verhalten ist.
Rückblickend bietet der Fall eine wertvolle Warnung für alle, die PostgreSQL Arrays für große Binärdatenspeicherungen nutzen wollen: Arrays sind in PostgreSQL nicht für häufige, inkrementelle Änderungen an großen Datenfeldern ausgelegt. Mit jedem Update wird der gesamte Array-Inhalt neu gespeichert und erzeugt erhebliche Mengen an veralteten Datensätzen bis zur nächsten VACUUM-Phase. Die Umstellung auf ein normalisiertes Schema, bei dem neue Daten als separate Zeilen eingefügt werden, ist der Weg aus der Falle. Diese Methode ist nicht nur ressourcenschonender, sondern entspricht auch den internen Stärken und Erwartungen von PostgreSQL. Außerdem macht sie das Datenmanagement flexibler und reduziert das Risiko technischer Schulden, die durch ineffiziente Speicherung entstehen.
Zusammenfassend zeigt die Erfahrung mit bytea[] in PostgreSQL exemplarisch, wie wichtig ein durchdachtes Datenbankdesign für Performance und Stabilität in produktiven Systemen ist. Entwickler sollten sich nicht allein auf die Dokumentation oder Beispiele verlassen, sondern dringend reale Tests durchführen und auch die Architektur der Datenbank selbst kritisch hinterfragen. Ein simples, vermeintlich elegantes Feature wie Arrays kann bei bestimmten Nutzungsmustern zu einem echten Performance-Killer werden. Letztendlich lehrt uns der Fall, dass in PostgreSQL – trotz seiner Leistungsfähigkeit – die traditionellen Prinzipien der relationalen Datenmodellierung weiterhin gelten. Der direkte Rückgriff auf relationale Normalisierung und die Nutzung von Inserts statt Updates bei großen Datenmengen sind entscheidende Faktoren für Skalierbarkeit und Effizienz.




![C64 Bass Guitar – Cool to Be Square Wave? [video]](/images/F3C844A1-B342-4FDE-B454-81E015FA82DC)


