Das Verfassen von Postmortems – also ausführlichen Nachberichten zu Vorfällen in IT-Systemen – stellt für viele Unternehmen eine zentrale Säule dar, um aus Fehlern zu lernen und künftige Zwischenfälle zu vermeiden. Doch der Prozess ist oft zeitaufwendig und ermüdend, nicht zuletzt weil die beteiligten Mitarbeitenden meist schon zum nächsten dringenden Problem weitergegangen sind, wenn der Bericht entstehen soll. Vor diesem Hintergrund hat Datadog eine innovative Lösung entwickelt, die Large Language Models (LLMs) nutzt, um die Erstellung dieser Berichte deutlich zu erleichtern. Ziel ist es, den Aufwand für die Verfasser zu verringern, ohne den menschlichen Lern- und Entdeckungsprozess zu ersetzen. Gleichzeitig wurden Kosten, Qualität und Sicherheit in Einklang gebracht, was eine enorme Herausforderung darstellt.
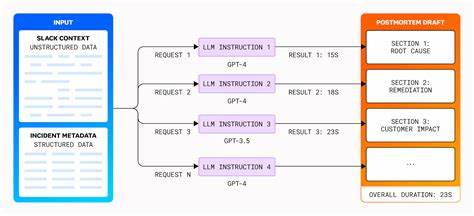
In diesem Beitrag wird die Herangehensweise, die Herausforderungen, die Lösungswege sowie die zukünftigen Perspektiven im Umgang mit LLMs für Postmortems erläutert. Die Grundlage für das Projekt bildete die Kombination von strukturierten Metadaten aus Datadogs Incident Management System mit unstrukturierten Diskussionen aus Slack-Kanälen. Dieses hybride Datenfundament ermöglicht es, relevante Informationen umfassend zusammenzuführen und anschliessend an ein Ensemble von LLMs weiterzugeben, die daraufhin erste Entwürfe für Postmortem-Berichte generieren. Diese Entwürfe dienen als Ausgangspunkt, den menschliche Autoren weiter verfeinern und anpassen. Ein wesentliches Learning war, dass die einfache Anwendung von LLMs, wie sie bei interaktiven Dialogsystemen häufig vorkommt, für diesen produktionsnahen Anwendungsfall nicht ausreicht.
Die nicht-deterministische Natur von LLMs führt zu Problemen wie inkonsistenter Formatierung, Wiederholungen und gelegentlichen Halluzinationen – also der Erzeugung von falschen oder erfundenen Inhalten, die realistisch klingen. Gerade bei Postmortems, in denen Fakten unverhandelbar sind, stellte dies eine große Herausforderung dar. Neben der inhaltlichen Qualität waren auch Kosten und Geschwindigkeit zentrale Faktoren. So sind leistungsstärkere Modelle wie GPT-4 zwar genauer, verursachen jedoch deutlich höhere Kosten und benötigen mehr Rechenzeit. Im Gegensatz dazu bietet GPT-3.
5 ein kostengünstigeres und schnelleres, aber weniger präzises Ergebnis. Datadog entwickelte eine hybride Modellstrategie, bei der verschiedene Modelle je nach Postmortem-Abschnitt eingesetzt werden. Dadurch lässt sich die hohe Qualität dort gewährleisten, wo sie am wichtigsten ist, ohne das Budget unnötig zu belasten. Die Balance zwischen den strukturierten und unstrukturierten Daten ist für die Qualität der Inhalte entscheidend. Insbesondere die manuell ausgefüllten Felder wie „Customer Impact“ im Incident Management garantieren eine hohe Genauigkeit, können jedoch schnell veralten.
Dagegen analysieren LLMs live-Kommunikation aus Slack und können dynamisch aktuelle Erkenntnisse ableiten. Durch die Kombination beider Datenquellen entsteht ein umfassenderes Bild des Vorfalls. Ein weiterer kritischer Punkt war das Thema Vertrauen und Datenschutz. Gerade bei der Analyse technischer Vorfälle enthalten die Daten oft sensible Informationen und Betriebsgeheimnisse. Um ein unbefugtes Übermitteln solcher Daten an die LLMs zu verhindern, wurde eine strenge Pipeline implementiert, die Secrets automatisch erkennt und durch Platzhalter ersetzt.
Erst nach der KI-Verarbeitung werden diese durch die echten Inhalte ersetzt. Zudem wird klar kommuniziert, dass die erzeugten Entwürfe lediglich Hilfestellungen sind und die menschlichen Autoren weiterhin die Kontrolle über den Endbericht behalten müssen. Dies trägt dazu bei, die für den Lernprozess wichtige Reflexion nicht zu untergraben. Um die Qualität der generierten Entwürfe systematisch zu bewerten, setzte Datadog auf eine Kombination aus qualitativen Befragungen und quantitativen Metriken. Autoren früherer Berichte wurden befragt, wie genau, verständlich und vollständig die KI-Ergebnisse im Vergleich zu menschlich verfassten Berichten sind.
Die Ergebnisse zeigten, dass die KI besonders gut darin ist, exakte Fakten aus Log-Daten abzubilden, während Menschen den Kontext technisch komplexer Zusammenhänge und die Ableitung von Folgeaktivitäten besser erfassen. Metriken wie ROUGE oder BLEU wurden ebenfalls getestet, lieferten jedoch nur eingeschränkte Einblicke, da sie die inhaltliche Tiefe und Korrektheit nicht vollständig abbilden können. Die technische Umsetzung ermöglichte durch parallele Verarbeitung einzelner Postmortem-Abschnitte eine drastische Reduzierung der Generierungszeit von über 12 Minuten auf unter eine Minute. Allerdings mussten Nachbearbeitungsschritte implementiert werden, um Überschneidungen und redundante Inhalte zu filtern. Die Verfeinerung beinhaltete die Umwandlung von Fließtexten in strukturierte Bullet-Points, was die Lesbarkeit erhöhte.
Darüber hinaus wurde getestet, den Kontext durch ergänzende interne Dokumentationen wie Wiki-Einträge oder Systembeschreibungen zu erweitern. Dieser Schritt verspricht eine tiefere Analyse und bessere Ursachenforschung in zukünftigen Versionen. Ein separates, nebengleiches Projekt erarbeitete zudem kurze Zusammenfassungen von Vorfällen, die das Onboarding neuer Teammitglieder in laufende Diskussionen beschleunigen. Die Visualisierung und klare Kennzeichnung von KI-generiertem Text im User Interface förderte das Vertrauen der Nutzer. Sie konnten so auf einen Blick erkennen, welche Abschnitte vom System vorgeschlagen wurden und welche menschlichen Ursprungs sind.
Außerdem ermöglicht die offene Darstellung der Anweisungen an die LLMs eine flexible Anpassung an die eigenen Bedürfnisse und eine stetige Weiterentwicklung der Vorlagen. Zusammengefasst lässt sich festhalten, dass der Einsatz von LLMs in der Postmortem-Erstellung das Potenzial hat, umfassende Berichte effizienter zu erstellen und die Arbeitsbelastung der Mitarbeitenden zu reduzieren, ohne die Qualität und das Lernen zu beeinträchtigen. Die sorgfältige Balance aus menschlicher Kontrolle, technologischer Unterstützung und Datenschutz ist hierbei entscheidend. Außerdem zeigt das Projekt exemplarisch, dass der professionelle Umgang mit LLMs besondere interdisziplinäre Kompetenzen erfordert, die Softwareentwicklung, Datenwissenschaft und technisches Schreiben vereinen. Für die Zukunft plant Datadog, die Funktionen weiter auszubauen, indem etwa weitere Datenquellen ergänzt und assistierende Features direkt im Bearbeitungsprozess integriert werden.
Auch die individuelle Anpassung der Postmortem-Vorlagen an unterschiedliche Anwendungsfälle steht auf der Agenda. Langfristig könnten sogar KI-generierte Varianten für spezielle Kundengruppen oder öffentliche Veröffentlichungen entstehen, was die Flexibilität und den Nutzen der Technologie unterstreicht. Das Projekt von Datadog liefert spannende Einblicke in die praktische Anwendung moderner KI-Technologien zum Nutzen von Unternehmen und setzt Maßstäbe für Qualität, Sicherheit und Kosteneffizienz in einem sensiblen, aber wesentlichen Bereich der IT-Betriebsführung.








