Der Kryptowährungsmarkt gilt als einer der volatilsten und dynamischsten Finanzmärkte weltweit. Die immense Anzahl an Kryptowährungen und die hohe Handelsaktivität verleihen diesem Markt eine Komplexität, die sowohl Chancen als auch Risiken birgt. Um diese Komplexität besser zu verstehen, ist die Analyse von Volatilitätsmustern ein entscheidender Ansatz. Sie ermöglicht es, Verhaltenstrends zu erkennen, extreme Marktbewegungen zu identifizieren und Kryptowährungen anhand ihrer spezifischen Risikoprofile zu klassifizieren. Ein wegweisendes Projekt, das diese Herausforderungen adressiert, ist die umfassende Untersuchung von Volatilitätsclustern für mehr als 1000 Kryptowährungspaare auf Basis von minutengenauen Handelsdaten.
Dieses Projekt kombiniert Big-Data-Technologien, fortschrittliche Statistik und maschinelles Lernen, um die vielfältigen Facetten des Handelsverhaltens und der Marktbewegungen zu beleuchten. Volatilität ist in der Finanzwelt ein zentraler Begriff und beschreibt die Schwankungsintensität eines Vermögenswertes. Insbesondere bei Kryptowährungen ist dieses Maß besonders ausgeprägt. Viele Trader und Investoren verstehen die Volatilität als zweischneidiges Schwert, das erhebliche Gewinnchancen, aber auch hohe Risiken mit sich bringt. Das Ziel der Analyse besteht darin, diese Volatilitätsmuster zu erkennen und zu gruppieren, um dadurch die zugrundeliegenden Dynamiken des Marktes besser greifbar zu machen.
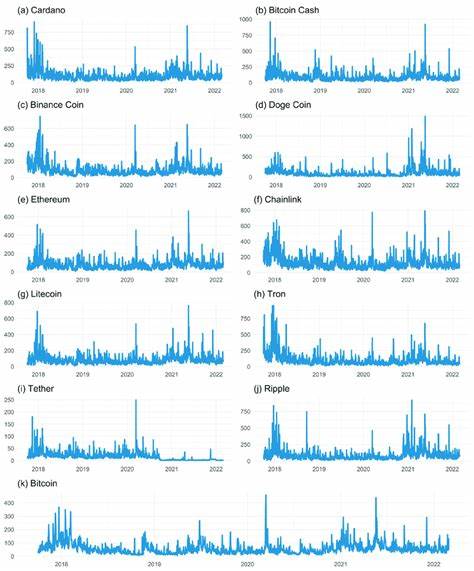
Das erwähnte Projekt sammelt aufwendige minutengenaue Handelsdaten von über 1000 Kryptowährungspaaren. Diese Detailtiefe ist selten und erlaubt es, temporäre Phänomene, sprunghafte Bewegungen sowie Verhaltensweisen in verschiedenen Handelsperioden zu untersuchen. Die Daten stammen aus öffentlich zugänglichen Quellen wie der Binance-Plattform, wobei die enorme Datenmenge eine effiziente Datenverarbeitung und Cleaning-Methoden erfordert. Im ersten Schritt werden die Rohdaten extrahiert, bereinigt und in ein analysierbares Format überführt. Parquet-Dateien, die komprimiert vorliegen, werden entpackt und verarbeitet.
Die Herausforderung besteht darin, aus den vielen Datenfragmenten ein kohärentes Bild zu schaffen, ohne wichtige Informationen zu verlieren oder Verzerrungen einzuführen. Eine saubere Datenbasis bildet die Voraussetzung für alle weiteren Analysen. Im Anschluss folgt die Feature-Engineering-Phase. Hier werden aus den Rohdaten verschiedene Kennzahlen berechnet, die die Volatilität und das Handelsverhalten repräsentieren. Zu den wichtigsten Features gehören Volatilität selbst, Sprunghäufigkeit, statistische Kennzahlen wie Schiefe (Skewness) und Wölbung (Kurtosis) sowie dynamische Handelsvolumenmessungen.
Diese Merkmale erfassen nicht nur die Intensität, sondern auch die Verteilung und Art der Bewegungen. Unter anderem wird so ersichtlich, wie stark die Kurse in kurzen Zeiträumen ausschlagen und ob es ungewöhnliche „Extremereignisse“ gibt, die auf Marktturbulenzen hindeuten. Eine besonders wichtige Kennzahl ist die Labelung von „extremen Coins“, was bedeutet, dass bestimmte Kryptowährungen aufgrund ihrer statistischen Eigenschaften als besonders volatil oder riskant eingestuft werden. Diese Kategorisierung hilft dabei, jene Kryptowährungen zu identifizieren, die sich deutlich von der Masse abheben, sei es aufgrund von besonders hoher Volatilität oder ungewöhnlichen Verhaltensmustern. Da die erhobenen Merkmale eine hohe Dimensionalität besitzen, wird eine Dimensionsreduktion mittels Principal Component Analysis (PCA) durchgeführt.
Diese Technik fasst die wichtigsten Varianzkomponenten in wenigen Dimensionen zusammen, wodurch komplexe Beziehungen leichter visualisiert und interpretiert werden können. In zweidimensionalen PCA-Scatterplots werden somit die Cluster deutlich sichtbar. Die anschließende Clusteranalyse erfolgt mit dem KMeans-Algorithmus, der die Kryptowährungen basierend auf den Features in homogene Gruppen einteilt. Die Wahl der optimalen Clusteranzahl wird durch die Analyse des Silhouette Scores optimiert. Diese Metrik misst, wie gut sich die einzelnen Objekte innerhalb eines Clusters zugeordnet fühlen und wie klar die Cluster voneinander abgegrenzt sind.
Auf diese Weise verhindert die Analyse die Über- oder Untersegmentierung und sorgt für aussagekräftige Clustergruppen. Die Visualisierung spielt im gesamten Prozess eine tragende Rolle. Radar-Diagramme geben Aufschluss über die Durchschnittswerte der verschiedenen Features pro Cluster, ermögliche den Vergleich der Verhaltensmuster. Boxplots bieten Einblicke in die Verteilung der Messwerte, während Barplots die Anzahl der extremen Coins in den jeweiligen Clustern darstellen. Neben statischen Visualisierungen demonstriert das Projekt auch die Nutzung von Spark für Big-Data-Verarbeitung im verteilten Umfeld und die Durchführung von Bash-Befehlen zur Automatisierung und Datenvorbereitung innerhalb eines Docker-Containers.
Die Einbindung von Docker stellt sicher, dass die gesamte Pipeline reproduzierbar und unabhängig von lokalen Umgebungen ausgeführt werden kann. Die Kombination dieser Methoden ergibt ein leistungsstarkes Instrumentarium für die Analyse komplexer Marktverhalten. Durch die Clusterung lassen sich langfristige Trends und sogenannte „Volatilitätsgruppen“ entdecken. Beispielsweise können Coins identifiziert werden, die tendenziell ruhiger handeln und für risikoärmere Strategien geeignet sind, während andere Kryptowährungen besonders unruhig und sprunghaft sind und als Spekulationsobjekte fungieren. Die Bedeutung dieser Forschung liegt nicht nur in der akademischen Analyse, sondern hat auch praktische Anwendungen.
Hedgefonds, institutionelle Investoren und algorithmische Trader gewinnen durch das Verständnis von Volatilitätsclustern einen Wettbewerbsvorteil. Sie können ihre Strategien an die Eigenschaften der jeweiligen Cluster anpassen, um Risiken besser zu managen oder gezielter auf Volatilitätsausbrüche zu reagieren. Zudem helfen die Erkenntnisse, Marktmechanismen transparenter zu machen und versteckte Zusammenhänge zu erkennen. Ein weiterer wichtiger Aspekt ist die Lehre aus der Datenverarbeitung großer Mengen an Hochfrequenzdaten. Das Projekt zeigt beispielhaft, wie moderne Technologien wie Apache Spark und Containerisierung dazu beitragen können, die Herausforderungen großer Datenmengen zu meistern.
Durch die Nutzung von Spark RDDs und DataFrames wird die Performance signifikant verbessert, während durch Docker eine einfache Reproduzierbarkeit und Skalierbarkeit ermöglicht wird. Abschließend lässt sich sagen, dass die Analyse der Volatilitätscluster im Kryptowährungsmarkt einen wertvollen Beitrag zum besseren Verständnis der Marktmechanik darstellt. Sie liefert ein Werkzeugset, mit dem komplexe Datenmengen strukturiert und interpretiert werden können. Damit öffnet sich eine Tür zu tieferer Marktkenntnis und innovativen Anwendungsfeldern in der Finanztechnologie. Die modernen Methoden vereinen Big Data, Statistik und Maschinenlernen so, dass aussagekräftige und praxisrelevante Ergebnisse entstehen, die sowohl die Forschung als auch die Praxis im Bereich der Kryptowährungen bereichern.
Die Zukunft gehört jenen, die Volatilitätsmuster frühzeitig erkennen und für fundierte Entscheidungen nutzen können.