Boltzmann Machines gehören zu den ältesten generativen Modellen innerhalb der Künstlichen Intelligenz und wurden bereits in den 1980er Jahren eingeführt. Sie sind besonders bekannt für ihre Fähigkeit, Muster in Daten ohne explizite Vorgaben zu erlernen, was sie zu einem wichtigen Werkzeug für das unüberwachte Lernen macht. Dieses Verfahren unterscheidet sich grundlegend von überwachten Lernmethoden, da Boltzmann Machines eigenständig verborgene Strukturen in Daten erkennen und daraus neue, statistisch ähnliche Daten generieren können – ein Kernanliegen generativer KI. Eine Boltzmann Machine ist eine spezielle Form eines neuronalen Netzes, das seine Funktionsweise aus physikalischen Konzepten der Energie ableitet. Das Netzwerk besteht aus einer Vielzahl von Neuronen, die jeweils nur zwei Zustände annehmen können: an (aktiviert) oder aus (deaktiviert).
Diese Neuronen sind miteinander verbunden, und die Stärke dieser Verbindungen wird durch sogenannte Gewichte definiert, welche positive oder negative Werte annehmen können. Im Netzwerk existieren sowohl sichtbare als auch versteckte Neuronen. Sichtbare Neuronen repräsentieren direkt beobachtbare Daten oder Eingabedaten, während versteckte Neuronen dazu dienen, unbekannte oder latente Muster im Trainingsmaterial zu erfassen. Ein wichtiger Unterschied besteht darin, wie die Verbindungen zwischen den Neuronen organisiert sind. Generelle Boltzmann Machines erlauben Verbindungen nicht nur zwischen sichtbaren und versteckten Neuronen, sondern auch innerhalb derselben Schicht.
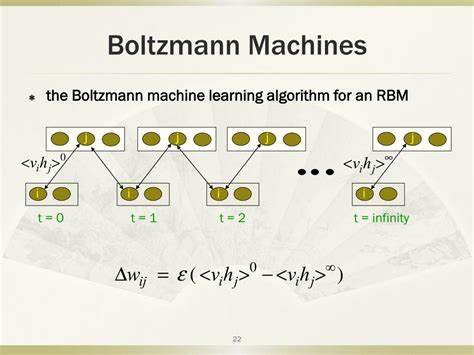
Aufgrund dieser umfangreichen Verschaltung ist das Training solcher Maschinen enorm komplex und aufwändig, da Berechnungen mit exponentieller Komplexität erforderlich sind. Um dem entgegenzuwirken, wurde die Architektur der Restricted Boltzmann Machine (RBM) entwickelt. Hier sind die Verbindungen strikt auf die zwischen sichtbaren und versteckten Neuronen beschränkt, was sowohl die Berechnung erheblich vereinfacht als auch den Trainingsprozess beschleunigt und stabilisiert. Das Funktionsprinzip einer Boltzmann Machine basiert auf einem Energie-Konzept, das aus der statistischen Physik stammt. Jede mögliche Konfiguration der Neuronen – also welche aktiviert und welche deaktiviert sind – besitzt eine bestimmte Energie, definiert durch die Gewichtungen der Verbindungen und die Biases der einzelnen Neuronen.
Das Ziel des Trainings ist es, die Gewichte so anzupassen, dass Datenbeispiele aus der Trainingsmenge mit möglichst niedriger Energie repräsentiert werden. Formal ausgedrückt wird eine Energiefunktion genutzt, die aus einer Summe von gewichteten Produkten der sichtbaren und versteckten Einheiten sowie deren individuellen Biases besteht. Die Boltzmann Machine lernt also eine Wahrscheinlichkeitsverteilung über die Daten, die proportional zur Exponentialfunktion der negativen Energiewerte ist. Der Trainingsprozess der RBM ist dabei besonders elegant und erfolgt mittels eines Algorithmus namens Contrastive Divergence. Dieser Algorithmus ermöglicht es, die Gewichte und Biases iterativ so zu verändern, dass die Energie der gelernten Trainingsmuster gesenkt wird.
Im Kern erfolgt das Lernen in zwei Phasen: In der sogenannten positiven Phase wird die sichtbare Schicht mit echten Trainingsdaten fixiert (geclampte sichtbare Einheiten) und daraus die versteckten Einheiten aktiviert. In der negativen Phase hingegen werden versteckte und sichtbare Einheiten mehrfach abwechselnd mittels Gibbs Sampling neu berechnet, um eine Rekonstruktion der Daten und damit eine Modellverteilung zu erzeugen. Durch den Vergleich der Aktivierungen in der positiven versus der negativen Phase können Anpassungen an den Gewichten bestimmt werden, die die generierte Datenverteilung immer besser an die Trainingsdaten annähern. Ein Grundverständnis der mathematischen Grundlagen hilft, die Funktionsweise der Contrastive Divergence noch besser zu durchdringen. Die zugrundeliegende Theorie basiert auf einer Energie-Funktion E(v,h), die sowohl die sichtbaren Neuronen v als auch die versteckten Neuronen h berücksichtigt.
Diese Funktion wird genutzt, um eine Wahrscheinlichkeit für jede Konfiguration im Netzwerk zu definieren, wobei die Normalisierung über die sogenannte Partition-Funktion Z erfolgt. Ziel ist es, die Parameter – Gewichte und Biases – so zu optimieren, dass die Wahrscheinlichkeit der Trainingsdaten maximiert wird. Die Ableitung der Log-Likelihood der Daten nach den Gewichten führt zu einer Lernregel, die auf dem Unterschied der Erwartungswerte von Neuronenkombinationen basierend auf echten Daten bzw. vom Modell generierten Daten basiert. Um diese Erwartungen zu approximieren, werden Monte-Carlo Methoden wie Gibbs Sampling eingesetzt, welche schrittweise neue Zustände der Neuronen erzeugen.
In der Praxis bedeutet dies, dass das RBM nach mehreren Trainingsdurchläufen immer besser darin wird, Muster zu erkennen und in der Lage ist, diese nachzubilden und neue, ähnliche Datenpunkte zu generieren. Dies eröffnet spannende Anwendungen im Bereich der generativen KI. Beispiele daraus sind das Erzeugen von Bildern, Texten oder anderen Datenformaten, die statistisch zum Trainingsmaterial passen, aber dennoch neu und originell sind. Besonders interessant ist eine Tiny Restricted Boltzmann Machine, die direkt im Browser läuft. Diese kompakte Version ist nicht nur ein eindrucksvolles Demonstrationswerkzeug für die zugrundeliegenden Konzepte, sondern zeigt auch die Leistungsfähigkeit moderner Webtechnologien und JavaScript-basierter Berechnungen.
Ein solches Miniaturmodell erlaubt es Anwendern, interaktiv den Trainingsprozess Schritt für Schritt nachzuvollziehen, Änderungen an den Parametern vorzunehmen und die Energiewerte in Echtzeit zu beobachten. Die visuelle Darstellung der neuronalen Netzwerke, in der einzelne Neuronen sowie ihre Verbindungen hervorgehoben werden können, veranschaulicht eindrucksvoll die Dynamik beim Lernen und Generieren. Die Möglichkeiten einer im Browser ausführbaren RBM sind zudem weit über reine Demonstrationen hinausgehend. Sie bieten einen einfachen und zugänglichen Zugang für Entwickler, Forscher und Bildungseinrichtungen, die sich spielerisch mit den Grundlagen der KI vertraut machen möchten. Die unkomplizierte Handhabung ohne Installation, die Visualisierung der Trainingsprozedur und die sofortige Rückmeldung durch Simulationen machen diese Form besonders attraktiv.
Dies fördert das Verständnis komplexer Modelle und ermöglicht experimentelle Anpassungen, die in einem vollwertigen Entwicklungsumfeld oft viel Zeit und Rechenleistung benötigen. Neben dem expliziten Training mit bekannten Daten können Boltzmann Machines auch für Aufgaben eingesetzt werden, in denen Mustererkennung und unsupervised Feature Learning entscheidend sind. So können sie beispielsweise eingesetzt werden, um vorverarbeitete Merkmale aus Rohdaten herauszufiltern, die dann als Grundlage für weitere, komplexere Modelle dienen. In solchen hierarchischen Lernsystemen fungieren Boltzmann Machines als Bausteine, welche die Daten auf höhere Abstraktionsebenen heben. Die Technologie ist zwar nicht mehr ganz so modern wie einige der derzeit populären tiefen neuronalen Netze, dennoch bietet der mechanistische Hintergrund von Boltzmann Machines ein fundamentales Verständnis der Art und Weise, wie neuronale Netze Energie-Bilanzen nutzen, um die Komplexität realer Daten zu modellieren.
Darüber hinaus hat die Kombination von einfacheren Modellen wie der RBM mit tiefen Netzen in sogenannten Deep Belief Networks zu bedeutenden Fortschritten in der KI geführt. Zusammenfassend eröffnet die Tiny Restricted Boltzmann Machine im Browser einen spielerischen, aber tiefgründigen Zugang zu einem der ältesten und dennoch bedeutsamsten generativen Modelle der Künstlichen Intelligenz. Wer sich mit unüberwachtem Lernen und generativer Modellierung auseinandersetzt, findet hier eine spannende Möglichkeit, die komplexen mathematischen Konzepte visuell und interaktiv zu erleben. Die Kombination aus anschaulicher Visualisierung, effektiver Trainingsmethode und einfacher Zugänglichkeit durch Webtechnologien macht Tiny Boltzmann Machines zu einem wertvollen Werkzeug sowohl für Anfänger als auch für fortgeschrittene Anwender im Bereich der KI.