Die Entwicklung und der Betrieb verteilter Systeme stellen Unternehmen vor immer größere Herausforderungen, insbesondere wenn es um die schnelle Identifikation und Behebung von Problemen geht. OpenTelemetry hat sich als führender Standard im Bereich der Observability etabliert und bietet ein umfassendes Framework zur Instrumentierung von Anwendungen mit Metriken, Traces und Logs. Die OpenTelemetry Demo-Anwendung ist ein Microservice-basiertes E-Commerce-Projekt, das neben umfangreicher Dokumentation auch verschiedene Problem-Szenarien integriert. Diese Szenarien simulieren realistische Fehlerbildnisse wie hohe Latenzzeiten, Ausfälle und Netzwerkprobleme und dienen als wertvolle Testumgebung für Entwickler und Operatoren. Die zentrale Frage ist, ob Künstliche Intelligenz (KI) in der Lage ist, diese simulierten Probleme automatisch und effizient zu diagnostizieren und somit den Debugging-Prozess signifikant zu beschleunigen.
Relvy AI Labs hat sich genau dieser Fragestellung gewidmet und eine KI-gestützte Debugging-Lösung entwickelt, die auf Basis der OpenTelemetry Demo-Anwendung getestet wird. Die KI erhält Zugriff auf Observability-Daten in Form von Metriken, Traces und Logs, aus denen sie eigenständig Ursachenzusammenhänge identifiziert und handlungsorientierte Hinweise bereitstellt. Dabei agiert das System ähnlich wie ein erfahrener On-Call-Ingenieur, der systematisch Daten analysiert, Hypothesen überprüft und Rückfragen stellt. Im Gegensatz zu herkömmlichen Tools, die nur Rohdaten liefern, kombiniert die KI verschiedene spezialisierte Agenten, die auf bestimmte Datenmodalitäten spezialisiert sind. Beispielsweise gibt es Agenten, die Dashboard-Metriken analysieren und zeitliche Anomalien erkennen, andere durchforsten Logdateien nach Fehlerhinweisen, und weitere bearbeiten Traces, um Verzögerungen in einzelnen Microservice-Kommunikationen zu identifizieren.
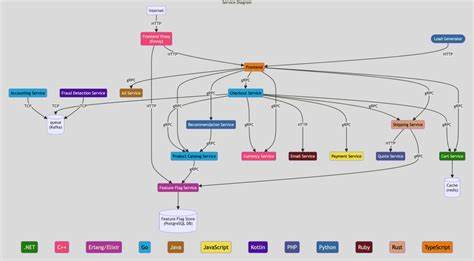
Ein übergeordneter Planungs-Agent orchestriert diese Aktivitäten, plant nach Analyseergebnissen die nächsten Schritte und koordiniert die Ergebniszusammenfassung für den Anwender. Ein besonders aufschlussreiches Szenario ist die Diagnose von Leistungsproblemen bei den Recommendation-Endpunkten der Demo-Anwendung. Die KI beginnt dabei mit einer gezielten Analyse der Latenzmetriken über das RED-Metrik-Dashboard, in dem „Avg Duration by Service“ wichtige Einblicke liefert. Danach werden exemplarische Traces analysiert, um Verzögerungen in spezifischen Service-Aufrufen wie dem Produktkatalog oder dem Feature-Flag-Service zu identifizieren. Die Logdateien der Recommendation-Services werden parallel durchforstet, um Warnungen und Fehler zu erkennen, die auf Timeouts oder Abhängigkeitsprobleme hindeuten könnten.
Schließlich überprüft die KI Ressourcenmetriken wie CPU- und Speichernutzung, um Engpässe oder Überlastungen als Ursachen auszuschließen. Die dabei erzielte Trefferquote ist beeindruckend: In etwa 74 Prozent der simulierten Problemfälle kann die KI den eigentlichen Fehler korrekt lokalisieren und mit relevanten Hinweisen unterfüttern. Dies zeigt die hohe Reife der Methode und verdeutlicht, dass KI-basierte Observability-Werkzeuge bereits heute eine wertvolle Unterstützung im Incident-Management darstellen können. Die KI arbeitet iterativ und erkennt, wenn zusätzliche Informationen benötigt werden. So ist sie in der Lage, Folgefragen von Ingenieuren zu beantworten, etwa ob bestimmte Produkt-IDs betroffen sind, welche Fehlermeldungen konkret auftreten oder wie sich der Fehlertrend über die Zeit entwickelt.
Diese dialogorientierte Interaktion trägt dazu bei, den Fehlerfindungsprozess nicht nur zu beschleunigen, sondern auch für verschiedene Erfahrungsstufen zugänglich zu machen. Insbesondere für komplexe Microservice-Landschaften, wie sie in der OpenTelemetry Demo-Anwendung mit 15 Services und 12 verschiedenen Programmiersprachen vorhanden sind, ist dieser Ansatz sehr vielversprechend. Ein wesentlicher Erfolgsfaktor für die Effektivität der KI liegt in der zugrundeliegenden Datenqualität und der Integration verschiedener Observability-Datenquellen. Durch periodische explorative Abfragen aktualisiert die KI ihr Verständnis über die verfügbaren Dashboards, Metriken und Logs kontinuierlich. Dadurch kann sie sich dynamisch auf neue Problemkontexte einstellen und die relevantesten Daten präzise herausfiltern.
Diese Adaptivität ist entscheidend, da Produktionsumgebungen sich ständig verändern und die Fehlerszenarien oft sehr vielschichtig sind. Die Entwicklung einer solchen KI-Debugging-Plattform stellt jedoch auch Herausforderungen dar. Beispielsweise lässt sich nicht jeder Fehlerfall automatisiert identifizieren, insbesondere wenn komplexe Abhängigkeitsketten oder externe Faktoren eine Rolle spielen. Zudem sind manche Ursachen nur indirekt in Observability-Daten sichtbar, was den Interpretationsspielraum einschränkt. Trotz dieser Limitationen übertrifft die aktuelle Implementierung viele traditionelle Monitoring-Methoden und bietet einen klaren Mehrwert.
Relvy plant, die Demo-Anwendung langfristig weiterzuentwickeln, indem kontinuierlich neue Fehler-Szenarien eingespielt werden. Dadurch entsteht eine lebendige Testumgebung, mit deren Hilfe die KI kontinuierlich verbessert und ihre Diagnostikfähigkeiten erweitert werden können. Zudem könnte dies als Grundlage für einen öffentlichen Benchmark dienen, der eine vergleichende Bewertung unterschiedlicher KI-Debugginglösungen ermöglicht. Für Unternehmen, die in hochkomplexen und verteilten Umgebungen operieren, heißt das: Künstliche Intelligenz wird zunehmend zu einem unverzichtbaren Helfer im On-Call-Alltag. Die KI entlastet Teams, reduziert die Zeit für die Fehlersuche und erhöht gleichzeitig die Präzision bei der Ursachenanalyse.