Die rasante Entwicklung der Künstlichen Intelligenz sorgt für eine stetig wachsende Nachfrage nach leistungsfähigen und skalierbaren Inferenzlösungen. Während vor einigen Jahren die schiere Komplexität und Größe von KI-Modellen die Hauptschwierigkeit darstellten, nimmt heute eine neue Herausforderung zu: die dynamischen und oft unvorhersehbaren Anforderungen moderner KI-Anwendungen, insbesondere von agentenbasierten Workflows und reasoning-orientierten Modellen. Diese führen zu einem exponentiellen Anstieg der Rechenlast und stellen die bisherigen Infrastrukturlösungen vor erhebliche Probleme. Hier setzt LLM-d an – eine innovative Opensource-Technologie, die die nächste Generation der KI-Inferenz prägt. LLM-d ermöglicht eine hochgradig effiziente, skalierbare und flexible Ausführung von großen Sprachmodellen (LLMs), welche die Nutzererfahrung und Betriebskosten signifikant verbessert.
Im Kern ist LLM-d eine Weiterentwicklung des Inferenz-Engines vLLM, das sich bereits als ressourcenschonender und schneller Ansatz für das Ausführen großer Sprachmodelle etabliert hat. Die Kombination von Googles Erfahrung in der sicheren und großmaßstäblichen Bereitstellung von KI-Diensten mit modernster Open-Source-Technologie schafft eine Plattform, die universell und einfach einsetzbar ist. Die Besonderheit von LLM-d liegt in seiner Kubernetes-nativen Architektur. Kubernetes hat sich inzwischen als De-facto-Standard zur Orchestrierung von Container-basierten Workloads durchgesetzt und bietet Unternehmen die Möglichkeit, KI-Inferenzprozesse mit höchster Flexibilität und Zuverlässigkeit zu betreiben. Mit LLM-d können Unternehmen von dieser Kubernetes-Infrastruktur profitieren und hochkomplexe KI-Modelle effektiv und individuell an ihre Bedürfnisse anpassen.
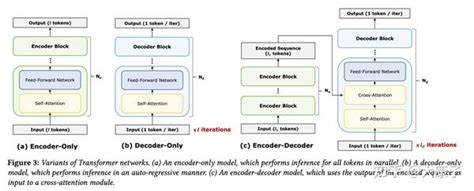
Ein wichtiges Merkmal von LLM-d ist der intelligente, vLLM-bewusste Inferenz-Scheduler. Anders als traditionelle Rundlaufverfahren zur Lastverteilung, die Anfragen rein zufällig auf verfügbare Ressourcen verteilen, berücksichtigt dieser Scheduler den Zustand der einzelnen Inferenzinstanzen und leitet Anfragen gezielt an Instanzen mit sogenannten Prefix-Cache-Treffern und geringer Auslastung weiter. Diese Maßnahme reduziert nicht nur die Latenzzeit, sondern verringert auch den Hardwarebedarf, da Ressourcen effizienter genutzt werden. Für Unternehmen bedeutet das erhebliche Einsparpotenziale bei gleichzeitiger Verbesserung der Performance. Ein weiterer Meilenstein in der Architektur von LLM-d ist die Unterstützung von disaggregiertem Serving.
Große Sprachmodelle durchlaufen bei der Inferenz mehrere Phasen, unter anderem das Prefill (Vorbefüllung) und die Dekodierung. Durch eine getrennte Verarbeitung dieser Phasen auf unabhängigen Instanzen können höhere Durchsatzraten realisiert und Latenzzeiten reduziert werden. Diese innovative Trennung sorgt für eine bessere Skalierbarkeit und ermöglicht eine flexible Ressourcenzuteilung, die sich besonders bei schwankenden Anfragelasten bezahlt macht. Darüber hinaus bietet LLM-d eine mehrstufige Key-Value-Cache-Architektur (KV-Cache), die Zwischenergebnisse, also sogenannte Präfixe, während der Inferenz effizient speichert. Dieser mehrschichtige Cache arbeitet über verschiedene Speicher-Tiers hinweg und optimiert dadurch die Antwortzeiten nachhaltig, während gleichzeitig die Speicherkosten minimiert werden.
Dies ist gerade bei umfangreichen Modellen und langen Anfragen ein entscheidender Vorteil. Die Flexibilität von LLM-d zeigt sich auch in der Unterstützung verschiedener Frameworks und Hardwareplattformen. Aktuell läuft LLM-d mit PyTorch, im Laufe des Jahres wird die Unterstützung für JAX folgen, sodass Entwickler bei ihrer Wahl des AI-Frameworks nicht eingeschränkt sind. Zudem unterstützt LLM-d sowohl GPU- als auch TPU-Beschleuniger, was den Einsatz in unterschiedlichsten Cloud- und On-Premise-Szenarien erlaubt. Diese Vielseitigkeit macht LLM-d zu einem bedeutenden Baustein auf dem Weg zur Cloud-basierten und hybriden KI-Infrastruktur.
Ein konkretes Beispiel für die Wirksamkeit von LLM-d ist der Einsatz auf Google Cloud. Dort wurde LLM-d nahtlos mit der Google Kubernetes Engine (GKE), Vertex AI und Cloud TPUs integriert, was in ersten Tests zu einer Verdoppelung der Geschwindigkeit bei der Generierung des ersten Tokens in Anwendungsfällen wie der Codevervollständigung führte. Somit wird nicht nur die Nutzererfahrung deutlich verbessert, sondern auch die Betriebseffizienz erheblich gesteigert. Darüber hinaus gelangt mit der siebten Generation der Ironwood-TPUs eine speziell für das Training und Serving von „reasoning models“ konzipierte Hardwaregeneration auf den Markt. Sie ermöglicht die Kopplung von bis zu 9.
216 flüssigkeitsgekühlten TPU-Chips in einem einzigen Rechenknoten mit revolutionären Inter-Chip-Interconnects. Die Kombination von LLM-d mit dieser Hardware setzt neue Maßstäbe in puncto Skalierbarkeit und Performance und unterstreicht Googles Engagement, modernste Recheninfrastrukturen für KI-Anwendungen zugänglich zu machen. Die Kooperation und der offene Umgang mit der Community spielen bei LLM-d eine ebenso große Rolle wie die technische Innovation. Google Cloud ist Gründungsmitglied im LLM-d-Projekt und arbeitet unter anderem mit Red Hat, IBM Research, NVIDIA, CoreWeave sowie weiteren führenden Unternehmen wie AMD, Cisco, Hugging Face, Intel, Lambda und Mistral AI zusammen. Die gemeinsame Entwicklung fördert die Verbreitung des Tools, garantiert kontinuierliche Weiterentwicklung und sichert die Kompatibilität mit unterschiedlichen Systemen.
Für Anwender bedeutet das eine größere Sicherheit bei Investitionen in diese Technologien und umfangreiche Möglichkeiten der Mitgestaltung. Gefördert wird der Einstieg in diese Technologien durch Aktionen wie einen kostenlosen Startguthaben von 300 US-Dollar für neue Google Cloud-Kunden sowie der kostenfreien Nutzung vieler Services im Rahmen des „Always Free“-Programms. Somit können Unternehmen und Entwickler erstklassige KI-Systeme mit minimalem Risiko testen und schnell validieren. Die Zukunft der KI-Inferenz fordert flexible, effiziente und kostengünstige Lösungen, die gleichzeitig auf die steigenden Anforderungen komplexer Modelle reagieren können. LLM-d vereint innovative Konzepte von intelligente Scheduling-Algorithmen, zeitgemäßer Cache-Technologie, skalierbarem disaggregiertem Serving und breit gefächerter Framework- und Hardwareunterstützung in einem Kubernetes-nativen Stack.
Diese Kombination macht LLM-d zu einer Schlüsseltechnologie, mit der Unternehmen heute und morgen ihre KI-Modelle kosteneffizient und performant betreiben können. Im Kontext der fortschreitenden Entwicklung von Agenten-Workflows, die zunehmend reasoning-orientierte Fähigkeiten verlangen, ist LLM-d hervorragend aufgestellt, um diese neuen Anforderungen zu bedienen. Es stellt die Infrastruktur bereit, die es ermöglicht, komplexe Interaktionen mit Multi-Turn-Kontexten sowie heterogenen Workloads optimal zu verarbeiten, ohne dabei die Nutzererfahrung zu beeinträchtigen. Zusammenfassend lässt sich sagen, dass LLM-d einen bedeutenden Schritt in der Evolution der KI-Inferenz darstellt. Es verbindet die offene Zusammenarbeit der Community mit der Innovationskraft führender Cloud-Provider und Hardware-Hersteller.
So entsteht eine robuste, zukunftssichere Plattform, die Unternehmen weltweit bei der Realisierung ihrer KI-Visionen unterstützt. Durch seine flexible Architektur, Effizienz und Skalierbarkeit ist LLM-d bestens dafür gerüstet, die Entwicklung von KI-Anwendungen neben dem Prototyping auch im produktiven Betrieb auf ein neues Level zu heben und die davon ausgehenden gesellschaftlichen und wirtschaftlichen Chancen nachhaltig zu fördern.