In der heutigen schnelllebigen Welt der Künstlichen Intelligenz (KI) sind große Sprachmodelle (LLMs) zu einem entscheidenden Werkzeug für verschiedenste Anwendungen geworden. Ob bei der Beantwortung komplexer Fragen, dem Verfassen von Texten oder bei der Automatisierung von Prozessen – die Fähigkeit, relevante Informationen flexibel und nachhaltig zu verwalten, hat sich als Schlüsselfaktor für den Erfolg von KI-Agenten herausgestellt. Genau an dieser Stelle setzt die Letta Leaderboard an, ein innovatives Benchmarking-Framework, das sich speziell auf die agentische Gedächtnisverwaltung von LLMs konzentriert. Während viele bestehende Benchmarks vornehmlich allgemeine Frage-Antwort- oder Programmieraufgaben bewerten, rückt Letta den Fokus auf die Grundlagen, die für den Betrieb langfristig aktiver und lernfähiger KI-Agenten notwendig sind. Agentische Gedächtnisverwaltung: Ein neuer Standard für smarte KI-Agenten Agentisches Gedächtnis beschreibt die Fähigkeit von KI-Agenten, ihr Gedächtnis selbstständig zu kontrollieren, also aktiv zu schreiben, zu lesen und zu aktualisieren – und zwar über mehrere Sitzungen hinweg und mit Unterstützung externer Datenquellen.
Diese Eigenschaft wurde erstmals durch Ansätze wie MemGPT etabliert und zeigt große Vorteile, denn sie ermöglicht es KI-Agenten, den Kontext über die begrenzte Fenstergröße von Sprachmodellen hinaus zu erweitern. Dabei werden Informationen in sogenannten "Memory Blocks" abgelegt, die entweder im unmittelbaren Kontext des Modells oder in einem archivierten Speicher verwaltet werden. Agentische Gedächtnisverwaltung macht es also möglich, dass Agenten auf wichtige Erfahrungen und Daten zugreifen, diese aktualisieren und für personalisierte sowie komplexe Aufgaben nutzen können. Letta als Framework und Benchmark-Plattform unterstützt Entwickler dabei, die Gedächtnisfunktionen ihrer KI-Agenten zu optimieren und die Performance verschiedener Modelle systematisch zu vergleichen. Gerade bei langfristigen oder komplexen Anwendungen, etwa in der Forschung, im Kundenservice oder bei digitalen Assistenten, entscheidet die Qualität der Gedächtnisverwaltung oft über Erfolg oder Misserfolg.
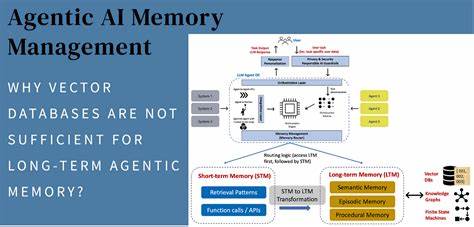
Aufbau und Funktionsweise der Letta Leaderboard Die Letta Leaderboard misst die Gedächtnisfähigkeiten von KI-Agenten anhand dreier zentraler Funktionen: Lesen, Schreiben und Aktualisieren von Speicherinhalten. Dabei arbeitet das System mit einer zweistufigen Speichermodellierung. Das Kern-Gedächtnis („Core Memory“) befindet sich direkt im Kontextfenster des LLMs und beinhaltet strukturierte Memory Blocks. Das Archiv-Gedächtnis („Archival Memory“) stellt eine externe Datenbank dar, auf die über gezielte Suchanfragen zugegriffen wird, wenn Informationen nicht im unmittelbaren Kontext verfügbar sind. Um die Gedächtnisfähigkeiten realistisch zu bewerten, nutzt Letta eigens generierte synthetische Fakten und zugehörige Fragen.
Diese Informationen sind fiktiv, wodurch Agenten ohne Nutzung des Gedächtnisses nicht in der Lage sind, korrekte Antworten zu geben. Die Evaluierung erfolgt mithilfe eines Prompt-basierten Scoring-Systems unter Verwendung von GPT-4.1, das die Antworten der Agenten gegen die vorgegebenen richtigen Lösungen bewertet und Fehler durch unnötige Gedächtnisoperationen bestraft. Die Lesekompetenz steht dabei im Mittelpunkt. Im Core Memory Benchmark werden Fakten in den Kernspeicher geladen und die Agenten getestet, ob sie diese direkt und effizient abrufen können, ohne auf andere Datenquellen zurückzugreifen.
Dieser Test spiegelt die Fähigkeit wider, Informationen, die sich im vorhandenen Kontext befinden, schnell zu verarbeiten und anzuwenden. Im Gegensatz dazu prüft der Archival Memory Read Benchmark das Verständnis des Agenten, wann es nötig ist, außerhalb des unmittelbaren Kontextes Informationen zu suchen. Dieser Aspekt ist besonders relevant für langzeitaktive Agenten, die ohne umfassendes Vorwissen auskommen müssen und nur über externe Gedächtnisquellen korrekte Rückschlüsse ziehen können. Neben dem Lesen spielt auch das Schreiben eine große Rolle. Im Memory Write Benchmark simuliert Letta, wie Agenten wichtige Fakten aus Dialogen extrahieren und eigenständig speichern, um sie später abrufen zu können.
Dieses Wissen bleibt sogar über das Löschen der ursprünglichen Chat-Historie erhalten und demonstriert, wie Agenten ihr Gedächtnis selbständig zu verwalten wissen. Das Memory Update Benchmark schließlich testet die Flexibilität von Agenten, indem widersprüchliche Fakten eingeführt werden, die eine Aktualisierung des bestehenden Gedächtnisinhalts erfordern. Nur wer seinen Speicher korrekt überschreibt oder anpasst, kann fehlerfreie Antworten liefern und beweist damit ein präzises Gedächtnismanagement. Ergebnisse und Implikationen für Entwickler Die bisherigen Ergebnisse der Letta Leaderboard zeigen, dass leistungsstarke Modelle wie Anthropic Claude Sonnet 4 mit Extended Thinking Budget und OpenAI GPT 4.1 die besten Leistungen in allen Speicherbewertungen erzielen.
Insbesondere punkten diese Modelle durch eine konsistente und effiziente Nutzung beider Speicherarten – sie wissen, wann sie direkt aus dem Kerngedächtnis lesen und wann sie die archivierte Suche aktivieren müssen. Aber auch kostengünstigere Alternativen wie Google Gemini 2.5 Flash und OpenAI GPT 4o-mini überzeugen durch solide Gedächtnisleistung zu einem Bruchteil der Kosten und sind daher für den breiten Einsatz in ressourcenbegrenzten Szenarien gut geeignet. Eine interessante Beobachtung betrifft Modelle, die auf archiviertes Gedächtnis spezialisiert sind, etwa Claude Haiku 3-5. Diese neigen dazu, häufig unnötige Gedächtnisoperationen auszuführen, was im Core Memory Benchmark zu Abzügen führt.
Solche Verhaltensmuster liefern wichtige Hinweise für Entwickler, die auf eine effiziente Nutzung von Speicherressourcen achten müssen. Modellwahl und Feinabstimmung sollten deshalb immer im Kontext des konkreten Anwendungsfalls erfolgen. Zukunftsausblick und Community-Engagement Die Letta Leaderboard lebt von kontinuierlicher Aktualisierung und Erweiterung. Neue Modelle, fortschrittlichere Langzeitaufgaben sowie zusätzliche Funktionen wie externe Toolaufrufe und Speicher-Reorganisation während Inaktivitätsphasen („Sleep-Time Compute“) sollen die Benchmark immer praxisnäher gestalten. Die Offenheit des Frameworks ermutigt die Community, eigene Tests beizutragen und die Plattform für spezielle Anwendungsfälle anzupassen.
Damit ebnet Letta den Weg für eine neue Generation von intelligenten, lernfähigen KI-Agenten, die sich durch eine ausgefeilte Gedächtnisverwaltung auszeichnen. Diese Agenten sind zukünftig in der Lage, komplexe Aufgaben mit hoher Genauigkeit über längere Zeiträume zu bewältigen und sich dynamisch an veränderte Umstände anzupassen. Fazit Mit dem Letta Leaderboard wurde ein Meilenstein für die Evaluierung der agentischen Gedächtnisverwaltung großer Sprachmodelle geschaffen. Es stellt die Bedürfnisse von Entwicklern in den Mittelpunkt, die langfristig robuste und intelligente KI-Agenten bauen möchten, und liefert dabei klare Empfehlungen für die Auswahl geeigneter Modelle. Leistungsfähige Gedächtnisfunktionen über das reine Textgenerieren hinaus sichern nachhaltige KI-Anwendungen, die über einzelne Interaktionen hinaus Denken, Lernen und Erinnern können.
Durch seine innovative Kombination aus Core- und Archivgedächtnis sowie realistischen Testszenarien bietet Letta eine einzigartige Plattform zur Verbesserung und Vergleichbarkeit von LLM-basierten Agenten. Die stete Weiterentwicklung und Einbindung der Community machen es zu einem unverzichtbaren Werkzeug für jeden, der die Zukunft der KI-Agenten mitgestalten möchte.








