Die Entwicklung eines Hypervisors stellt eine komplexe technische Herausforderung dar, die tiefe Kenntnisse von Architektur, Betriebssystemen und Hardwarevirtualisierung erfordert. Im Rahmen der aktuellen Trajektorie moderner CPU-Designs wächst die Bedeutung offener Befehlssatzarchitekturen wie RISC-V stetig. Die Implementierung eines Hypervisors für RISC-V, basierend auf der H-Erweiterung (Hardware Virtualization Extension), öffnet spannende Optionen für eine flexible, effiziente und zeitgemäße Virtualisierung von Gastbetriebssystemen wie Linux. Dieser Beitrag begleitet Sie auf einer Reise durch die Konzepte und praktischen Schritte zur Schaffung eines RISC-V Hypervisors, der auf einem innovativen Betriebssystem namens Starina ausgeführt wird. Die RISC-V Architektur ist bekannt für ihren modularen Aufbau und Offenheit, was die Entwicklung neuer Funktionen erleichtert.
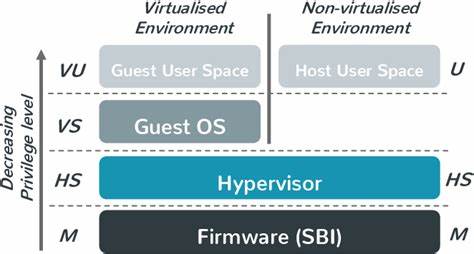
Die Einführung der H-Erweiterung bringt dedizierte CPU-Modi und Control and Status Registers (CSRs) mit sich, die hardwaregestützte Virtualisierung ermöglichen. Im Gegensatz zu klassischen Virtualisierungstechniken bietet die H-Erweiterung ähnlich wie Intel VT-x die Möglichkeit, sowohl für Host als auch Gäste separate Kernel- und Benutzermodi bereitzustellen. Dies unterstützt eine effiziente Parallelität von Betriebssystemen, wobei Gastinstanzen für den Host quasi als normale Prozesse erscheinen. Die Ähnlichkeit zur erfolgreichen VT-x-Architektur kennzeichnet einen intelligenten Entwurf, der die Entwicklung neuer Hypervisoren auf RISC-V erleichtert. Eine der größten Herausforderungen bei der Hypervisor-Entwicklung ist die Testbarkeit und Debuggbarkeit der eigenen Arbeit.
Auf herkömmlichen Systemen wie Linux kommen KVM-basierte Lösungen zum Einsatz, doch bei einem entirely neuen System wie Starina ist der Weg zunächst steinig. Hier erweist sich die Rolle von QEMU als entscheidend. QEMU kann dank seiner Emulationsfähigkeit der RISC-V H-Erweiterung das Hardware-Virtualisierungs-Feature simulieren, was Entwickler befähigt, den Hypervisor unter macOS oder anderen Host-Betriebssystemen zu testen. Durch den Parameter -cpu rv64,h=true lässt sich die H-Erweiterung in der CPU-Emulation aktivieren, so dass alle Virtualisierungsbefehle und CSRs nachvollziehbar getestet werden können. Diese Möglichkeit hat für Entwickler eine enorme Bedeutung, weil sie das attachen von Debuggern wie GDB ermöglicht, um tiefgehende Einsichten in das Verhalten von Hypervisor und Gastbetriebssystem zu erlangen.
Der Einstieg in die klassische Virtualisierung erfolgt mit dem Wechsel in den Gastmodus, im RISC-V Kontext als VS-Modus bezeichnet. Die Initialisierung erfolgt dabei über das korrekte Setzen bestimmter CSR-Register, wie hstatus.SPV, bevor ein sret-Befehl ausgeführt wird. Die erfolgreiche Umschaltung in die Gastumgebung wird durch erste Fehler, etwa eine Guest-Page-Fault-Exception, bereits signalisiert – schließlich bedeutet ein solcher Fehler, dass die CPU tatsächlich in den Gastmodus gewechselt ist und reguläre Speicherzugriffe im Gast überprüft werden. Dieser Moment ist ein wichtiger Meilenstein, der signalisiert, dass die Hardwarevirtualisierung auf Low-Level-Ebene korrekt arbeitet.
Um ein Programm innerhalb des Gasts auszuführen, ist die Vorbereitung der Speicherabbildung entscheidend. Anders als bei traditioneller Speicherverwaltung muss die virtuelle Maschinenseite zum Gast-physikalischen Speicher gemappt werden. Die RISC-V Architektur erweitert hierbei die klassischen Paging-Modi mit sogenannten Sv39x4, Sv48x4 und Sv57x4 Varianten. Diese sind weitgehend kompatibel mit Sv39, Sv48 und Sv57, erfordern jedoch das gesetzte U-Bit für Kernel-Seiten. Dieser Detailpunkt ist für die Funktionsfähigkeit unerlässlich und illustriert die Feinheiten, mit denen moderne Virtualisierungstechnologien umgehen müssen.
Danach kann ein einfacher System-Call (ecall) im Gast erfolgreich ausgeführt werden, ein weiterer Beweis für funktionierende Speicherabbildung und Moduswechsel. Im nächsten Schritt ist es naheliegend, ein einfaches Programm im Gast auszuführen – etwa ein kleines „Hello World“, das über mehrere ecall-Interrupts Zeichen ausgibt. Durch die emulierte SBI (Supervisor Binary Interface) kann ein einfacher Zeichen-Output realisiert werden, indem Befehle für putchar geschickt werden. Interessanterweise löst das intentional eingefügte 'unimp' (undefinierter Befehl) einen Trap aus, was die Hypervisorseite zu einem kontrollierten Eingreifen veranlasst und somit eine wichtige Kontrollmöglichkeit darstellt. Die Erstellung dieses kleinen Gasts erfolgt mit gängigen Tools wie clang und llvm-objcopy, zeigt jedoch klar die neue Anpassungsfähigkeit und einfache Portierungsmöglichkeiten im RISC-V Umfeld.
Der bedeutendste Test für jeden Hypervisor ist jedoch das Booten eines komplexen Betriebssystems wie Linux. Das Linux-Kernel-Image für RISC-V wird mit spezifischen Konfigurationen kompiliert, die die Nutzung der RISC-V SBI und verschiedener Timer- und HVC-Optionen ermöglichen. Das schnelle Laden des Images in den Gast-Speicher und der anschließende Sprung auf den Eintragspunkt demonstrieren, wie eng der Hypervisor mit dem Betriebssystem zusammenarbeiten muss. Zu Beginn stürzt der Linux-Kernel jedoch häufig mit Fehlern wie Nullreferenzen ab, beispielsweise beim Zugriff auf Device Tree Datenstrukturen (dtb). Dieses Detail unterstreicht die Bedeutung der Hardwarebeschreibung im Virtualisierungsumfeld.
Das Device Tree Blob (DTB) ist gerade bei RISC-V essentiell, um dem Linux-Kernel mitzuteilen, welche Hardwarekomponenten zur Verfügung stehen. Die Verwendung von spezialisierten Rust-Crates wie vm-fdt erlaubt eine flexible Erstellung und Anpassung dieser Datenstruktur. Es werden Kerninformationen wie freie Speicherbereiche und CPU-Details benötigt, um Linux den Start auf der virtuell nachgebauten Hardwareumgebung zu ermöglichen. Etwas später zeigt sich, dass weitere Register, etwa hcounteren, korrekt initialisiert werden müssen, um Fehler bei Zeitmessungen wie dem Zugriff auf Befehlscounter und Timer-Counter zu vermeiden. Das richtige Setzen dieser Register verhindert virtuelle Instruktionsausnahmen und liefert eine funktionierende Grundlage für die Zeitsteuerung innerhalb des Gasts.
Der weitere Schritt, die Unterstützung des Timers, ist für die vollständige Funktionalität von Linux unabdingbar. Linux erwartet fortlaufende Timerinterrupts, um Aufgaben wie Scheduling und Systemaufrufe korrekt zu verarbeiten. RISC-V bietet hier verschiedene Herangehensweisen, beispielsweise das Setzen von Timern via SBI-Aufrufen oder die Nutzung der sstc-Erweiterung, die Hardwareinterrupts für Timer unabhängig vom Hypervisor ermöglicht. Für den Hypervisor liegt die Herausforderung darin, Timerinterrupts überzeugend zu simulieren und an den Gast weiterzuleiten. Die korrekte Konfiguration von Interruptdelegegierung (hideleg) gemäß den erweiterten RISC-V Interrupt-Architekturen ist dabei von zentraler Bedeutung.
Obwohl komplex und teils verwirrend, ist dieses Thema dank Ressourcen wie der Unified Database von RISC-V verständlich umsetzbar. Sobald Linux erfolgreich bootet, konzentriert sich die Entwicklung des Hypervisors auf die Bereitstellung von Geräten via MMIO (Memory-Mapped I/O). Diese Technik ermöglicht es, Geräte über bestimmte Speicheradressen zugänglich zu machen, doch diese Adressen sind im Gast nicht physisch durch Hardware gedeckt, sondern müssen vom Hypervisor emuliert werden. Dabei erkennt der Hypervisor Zugriffe auf nicht gemappte Adressen als MMIO und fängt sie ab. Er dekodiert dann die Instruktion, extrahiert Details zum Register und Zugriffstyp und führt den Vorgang virtuell aus.
Trotz des komplex erscheinenden Ablaufs ermöglicht RISC-V's klare CSRs, beispielsweise htinst und htval, die besonders effiziente Erkennung der Instruktionen. Es ist jedoch wichtig, auf Details wie das Verschieben der htval-Adresse um 2 Bits und das Vorhandensein komprimierter Instruktionen zu achten, um korrekte Emulation sicherzustellen. Die Anbindung eines Dateisystems ist der nächste Meilenstein für den Hypervisor. Während virtio-blk für Blockgeräte klassisch ist, fiel die Wahl auf virtio-fs. Dieses erlaubt eine direkte Anbindung von Nutzerdateisystemen an das Gast-Betriebssystem, mittels FUSE (Filesystem in Userspace).
Dadurch wird eine noch nahtlosere Integration möglich, indem vom Hypervisor bereitgestellte virtuelle Dateien in der Gast-Umgebung zugänglich werden. Virtio-fs stellt deshalb eine moderne und effiziente Lösung für die gemeinsame Nutzung von Dateien zwischen Host und Gast dar, die speziell in Umgebungen wie Starina von großem Vorteil ist. Die Dual-Debug-Fähigkeit stellt eine sehr nützliche Entwicklungsfunktion dar. Starina unterstützt eine Unikernel-ähnliche Betriebsart, in der Microkernel und Applikationen in einem einzigen ELF-Binary kombiniert werden. Dies erhöht die Performance und erleichtert das Debuggen.