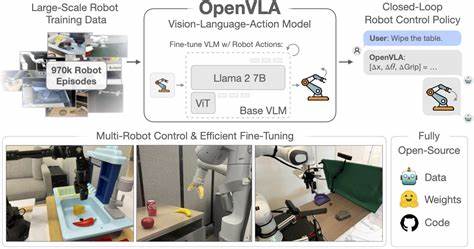
Die rasante Entwicklung im Bereich der künstlichen Intelligenz (KI) ermöglicht heutzutage beeindruckende Fortschritte bei der Kombination von Bildern, Sprache und Handlungsausführung. Vision-Language-Action (VLA) Modelle stellen dabei eine zukunftsweisende Technologie dar, welche die Interpretation von visuellen Szenen, das Verstehen von beschreibender Sprache und die anschließende Durchführung von Aktionen durch Maschinen miteinander verbindet. Der neu eingeführte Ansatz des interaktiven Post-Trainings markiert einen bedeutenden Fortschritt in dieser Domäne. Er optimiert VLA-Modelle durch den Einsatz von Reinforcement Learning (RL) und minimiert dabei den Bedarf an umfangreichen Experten-Daten, wodurch eine enorme Effizienzsteigerung und Flexibilität erreicht wird.Traditionelle Trainingsmethoden für VLA-Modelle basieren in der Regel auf umfangreichen Offline-Datensätzen, die von menschlichen Experten annotiert wurden.
Dieser Ansatz ist nicht nur kostenintensiv, sondern auch begrenzt in seiner Anwendbarkeit auf neue Aufgaben und Umgebungen, da jegliche Abweichung von den ursprünglichen Trainingsdaten den Erfolg des Modells deutlich beeinträchtigen kann. Die Möglichkeit, ein VLA-Modell interaktiv nachzutrainieren, eröffnet somit neue Perspektiven für anpassungsfähige und nachhaltige KI-Systeme.Das Konzept des interaktiven Post-Trainings, insbesondere das vom Forschungsprojekt RIPT-VLA, basiert auf einem schlanken, flexiblen Reinforcement-Learning-basierten Ansatz, der auf spärlichem Feedback in Form von binären Erfolgsmeldungen aufbaut. Diese Methode verzichtet auf komplexe, kontinuierliche Belohnungssignale und setzt stattdessen auf einfache Erfolg/Nichterfolg-Rückmeldungen, die durch Interaktion mit der Umgebung gesammelt werden. Hierdurch wird nicht nur die Datenabhängigkeit auf ein Minimum reduziert, sondern auch die Robustheit gegenüber unterschiedlichen Anwendungsszenarien und unvorhergesehenen Aufgaben gesteigert.
Ein herausragendes Merkmal von RIPT-VLA ist seine Fähigkeit, mit minimaler Demonstrationsdatenmenge präzise und zuverlässige Aktionsstrategien zu erlernen. In Experimenten konnte gezeigt werden, dass bereits eine einzige Demonstration ausreicht, um ein zuvor kaum funktionierendes Fine-Tuning-Modell auf eine beeindruckende Erfolgsrate von bis zu 97 Prozent innerhalb von wenigen Trainingsdurchläufen zu bringen. Dies stellt einen Paradigmenwechsel dar, da bisherige Ansätze einen erheblich höheren Demonstrationsaufwand erforderten, um akzeptable Leistungen zu erzielen.Die Anwendung dieser innovativen Trainingsmethode verbessert nicht nur die Leistung leichter VLA-Modelle, sondern auch sehr große Modelle im Bereich der multimodalen KI-Systeme. So konnte beispielsweise das leichtere QueST-Modell um über zwanzig Prozent in der Erfolgsrate verbessert werden, während das große OpenVLA-OFT Modell mit sieben Milliarden Parametern eine nahezu perfekte Erfolgsrate von 97,5 Prozent erreichte.
Diese Ergebnisse unterstreichen die Skalierbarkeit und Anpassungsfähigkeit des interaktiven Post-Trainingsansatzes.Neben der Effizienz zeichnet sich RIPT-VLA ferner durch seine Stabilität und Generalisierungsfähigkeit aus. Die Algorithmen nutzen fortgeschrittene Techniken wie dynamisches Rollout-Sampling und eine Leave-One-Out-Advantage-Schätzung zur Politikoptimierung, was zu stabilen Lernverläufen und einer verbesserten Fähigkeit führt, Wissen auf verschiedene Aufgaben und Umgebungen zu übertragen. Dies ist gerade für Anwendungen in der Robotik von großer Bedeutung, wo sich die Bedingungen schnell verändern können und eine adaptive Handlungskompetenz essenziell ist.Praktisch gesehen bedeutet interaktives Post-Training eine erhebliche Vereinfachung bei der Implementierung und Weiterentwicklung von KI-Systemen, die mit visuellen und sprachlichen Daten arbeiten.
Roboter, die in Haushalten, Fabriken oder im medizinischen Umfeld eingesetzt werden, können künftig einfacher und schneller an spezifische Anforderungen angepasst werden, ohne dass umfangreiche neue Trainingsdatensätze erzeugt werden müssen. Dies kann die Verbreitung von intelligenten Assistenzsystemen erheblich beschleunigen und die Kosten für Forschung und Entwicklung deutlich senken.Die Forschung rund um das RIPT-VLA Konzept ist wegweisend für die Zukunft multimodaler KI und zeigt, wie Synergien zwischen verschiedenen Lernparadigmen – insbesondere Reinforcement Learning und vortrainierten Modellen – intelligent genutzt werden können, um die Limitierungen klassischer Methoden zu überwinden. Es steht zu erwarten, dass ähnliche Ansätze in der nahen Zukunft auch in anderen Bereichen Anwendung finden werden, wie beispielsweise in der autonomen Fahrzeugsteuerung, interaktiven virtuellen Agenten oder in der erweiterten Realität (Augmented Reality).Zusammenfassend lässt sich sagen, dass das interaktive Post-Training von VLA-Modellen eine neue Ära der Flexibilität, Effizienz und Leistungsfähigkeit in der Kombination von visionären und sprachbasierten Handlungssystemen einläutet.
Diese Methode ermöglicht es, mit minimalem Aufwand und Daten möglichst schnelle Anpassungen und Optimierungen vorzunehmen, womit der Weg für vielfältige praktische Anwendungen geebnet wird. Die Forschungsergebnisse motivieren dazu, das Zusammenspiel von visuellen, sprachlichen und aktiven Elementen im KI-Bereich weiter zu erkunden und zu nutzen, um noch intelligentere und anpassungsfähigere Systeme zu entwickeln. Damit tragen sie wesentlich zur Weiterentwicklung der künstlichen Intelligenz bei und eröffnen spannende Perspektiven für die Zukunft der Mensch-Maschine-Interaktion.








