Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren zahlreiche Fachgebiete revolutioniert. Insbesondere im Bereich der Chemie eröffnen diese Modelle teils überraschende Möglichkeiten, indem sie fundiertes Wissen verarbeiten, interpretieren und anwenden können. Gleichzeitig steht die Frage im Raum, wie diese künstlichen Intelligenzen im Vergleich zu menschlichen Experten abschneiden. Können LLMs das angehäufte Wissen und die Schlussfolgerungsfähigkeiten erfahrener Chemiker ersetzen oder zumindest ergänzen? Im Zentrum dieser Debatte steht das Verständnis der chemischen Kompetenzen von Sprachmodellen, ihre Stärken und Schwächen sowie die Auswirkungen auf Forschung, Lehre und Industrie.Große Sprachmodelle basieren auf maschinellem Lernen, speziell dem sogenannten Deep Learning.
Sie wurden darauf trainiert, Texte zu verstehen, zu generieren und komplexe Aufgaben zu lösen – häufig auch solche, für die sie nicht gezielt programmiert wurden. Im Chemiebereich sind solche Modelle in der Lage, chemische Formeln zu interpretieren, Reaktionsmechanismen zu beschreiben oder komplexe Fragestellungen zu beantworten. Doch wie gut ist die chemische Kompetenz dieser Sprachmodelle im Vergleich zu menschlichen Chemikern? Forschungsergebnisse zeigen, dass einige der fortschrittlichsten Modelle in standardisierten Tests teilweise die Leistungen von Experten übertreffen. Dennoch gibt es wichtige Einschränkungen und Herausforderungen, die nicht übersehen werden dürfen.Das Projekt ChemBench hat speziell eine umfangreiche Benchmarking-Plattform geschaffen, auf der mehr als 2700 Fragen aus verschiedenen Bereichen der Chemie gestellt und sowohl von LLMs als auch von menschlichen Chemikern beantwortet wurden.
Dabei zeigte sich, dass Spitzenmodelle wie das vom Unternehmen o1-preview entwickelte System durchschnittlich bessere Ergebnisse erzielten als die besten menschlichen Probanden dieses Tests. Dieser Erfolg zeugt von der beeindruckenden Lernfähigkeit und Breite der Wissensdaten, auf die die LLMs zugreifen können. Allerdings fällt auf, dass diese Modelle in bestimmten Aufgaben, besonders solchen, die tiefgreifende chemische Schlussfolgerungen oder Interpretationen von Strukturen erfordern, Schwierigkeiten haben. Beispielsweise bei der Vorhersage von Signalen in der Kernspinresonanzspektroskopie erzielten die Modelle eine deutlich niedrigere Trefferquote als Experten.Diese Unterschiede kann man teilweise durch die Art des Trainingsdatensatzes erklären.
LLMs wurden hauptsächlich an großen Textmengen aus wissenschaftlichen Artikeln, Büchern und Datenbanken trainiert. In einigen Fällen fehlt es jedoch an direktem Zugriff auf spezialisierte chemische Datenbanken, die etwa Sicherheitsinformationen, Toxizitätsdaten oder strukturbezogene Eigenschaften enthalten. Dies begrenzt teilweise das faktische Wissen der Modelle und erklärt, warum sie insbesondere bei sicherheitsrelevanten Fragen noch nicht zuverlässig sind. Menschliche Chemiker können hingegen auf solche Datenbanken direkt zugreifen und ihre Erfahrung in die Beurteilung einfließen lassen.Die Fähigkeit von LLMs, chemisches Wissen mit logischem Denken zu verknüpfen, ist ein weiterer kritischer Punkt.
Viele chemische Fragestellungen erfordern mehrstufige Schlussfolgerungen, die über reine Faktenkenntnis hinausgehen, etwa das Erkennen von Isomerenzahlen oder das Bewerten von Reaktivitäten unter komplexen Bedingungen. Während LLMs bei reinen Wissensfragen oft gut abschneiden, fällt es ihnen schwer, solche komplexen Überlegungen zu automatisieren. Dies ist teilweise auf die Funktionsweise zurückzuführen: LLMs generieren Antworten auf Basis von Wahrscheinlichkeiten und Ähnlichkeiten zu gelernten Textmustern, nicht durch echtes deduktives oder induktives Denken. Dieser Unterschied zur menschlichen Expertise, die auf Verstehen und Intuition beruht, zeigt sich in der teilweise fehlenden chemischen Intuition der Modelle.Ein weiterer interessanter Aspekt betrifft die Einschätzung der eigenen Antworten.
Menschliche Wissensarbeiter können in der Regel die Zuverlässigkeit ihrer Aussagen einschätzen und Unsicherheiten kommunizieren. LLMs hingegen zeigen oft übertriebenes Vertrauen, selbst wenn ihre Antwort falsch oder irreführend ist. Die sogenanntes „Overconfidence“-Problem stellt eine erhebliche Herausforderung für die praktische Anwendung dar, gerade in sicherheitskritischen Bereichen oder bei komplexer Entscheidungsfindung. Ansätze zur Kalibrierung der Vertrauenswerte werden derzeit erforscht, bleiben aber in vielen Systemen noch unzureichend.Betrachtet man die Chancen, die sich durch den Einsatz von LLMs in der Chemie eröffnen, ist jedoch das Potenzial enorm.
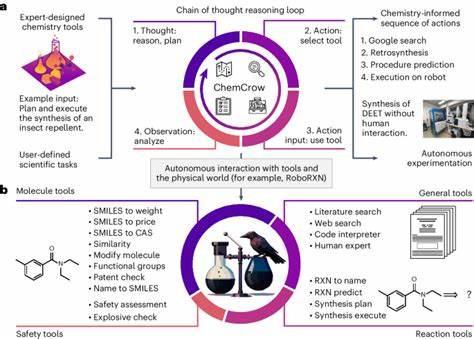
Große Sprachmodelle können Forschern neue Einblicke verschaffen, indem sie eine unvorstellbare Masse an Literatur, Experimentaldaten und chemischen Informationen konsolidieren. Sie können als digitale Assistenten – sogenannte Chemie-Copiloten – agieren, die Vorschläge für neue Synthesen machen, Reaktionsbedingungen optimieren oder Sicherheitshinweise bereithalten. Auch im Bildungsbereich könnten LLMs dazu beitragen, Lehrende und Studierende zu unterstützen, indem sie komplexe Sachverhalte verständlich erklären und individuell auf Fragen eingehen.Um dieses Potenzial bestmöglich zu nutzen, ist jedoch eine enge Zusammenarbeit zwischen Chemikerinnen und Chemikern sowie KI-Entwicklerinnen und -Entwicklern notwendig. Nur so lassen sich Modelle verbessern, die sowohl tiefergehendes, spezialisiertes Fachwissen als auch robuste Schlussfolgerungsmechanismen aufweisen.
Derzeitige Forschungsarbeiten zielen darauf ab, LLMs mit externen spezialisierten Datenbanken oder digitalen Tools zu kombinieren, etwa durch Retrieval-Augmented Generation oder Tool-Augmentation, um Wissenslücken zu schließen und sicherheitskritische Themen besser abzudecken.Die Herausforderungen bei der Integration von LLMs in die chemische Praxis sind jedoch nicht nur technischer Natur. Auch ethische und sicherheitspolitische Fragen spielen eine wichtige Rolle. So besteht das Risiko, dass der Zugang zu leistungsfähigen Modellen auch für die Entwicklung schädlicher Substanzen genutzt wird – ein Aspekt, der in der Gemeinschaft verstärkt diskutiert wird. Der Umgang mit falsch verstandenen oder fehlinterpretierten Antworten durch nicht-fachkundige Nutzer will ebenso bedacht sein.
Hier sind klare Regularien, Transparenz und verantwortungsbewusste Anwendung gefragt.Schließlich steht die Art und Weise der chemischen Ausbildung vor einem Wandel. Während traditionelle Prüfungen auf das Lernen von Fakten und einfache Aufgaben ausgelegt sind, machen die Erfolge der LLMs deutlich, dass kritisches Denken, tieferes Verständnis und praktische Intuition künftig mehr denn je im Vordergrund stehen müssen. Einfache Wissensabfragen verlieren an Relevanz, da Maschinen diese zunehmend besser beherrschen. Die pädagogischen Systeme sollten sich daher an eine Zusammenarbeit von Mensch und Maschine anpassen, in der die Stärken beider optimal genutzt und Schwächen kompensiert werden.
Zusammenfassend lässt sich festhalten, dass große Sprachmodelle in der Chemie schon heute beachtliche Leistungen erzielen und in bestimmten Bereichen die Expertise einzelner Fachleute übertreffen. Dennoch sind sie keine vollwertigen Ersatzsysteme für menschliche Chemiker mit langjähriger Erfahrung und tiefem Verständnis. Vielmehr sind sie wertvolle Werkzeuge, die die Forschung und Lehre unterstützen können, wenn sie verantwortungsvoll eingesetzt und weiterentwickelt werden. Die weitere Erforschung von Benchmarks wie ChemBench und die Entwicklung hybrider Systeme mit Fachwissen und KI sind zentrale Schritte hin zu einer Zukunft, in der chemisches Wissen und maschinelles Lernen gemeinsam neue Horizonte eröffnen.