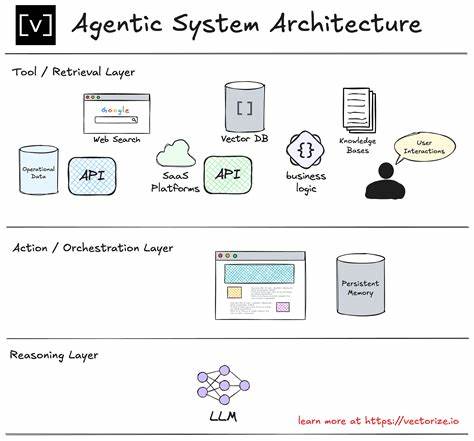
Die rasante Entwicklung von Künstlicher Intelligenz und insbesondere Large Language Models (LLMs) eröffnet neue Möglichkeiten, komplexe Aufgaben durch agentische Systeme zu automatisieren. Agentische Systeme sind Anwendungen, die auf der Fähigkeit von KI-Modellen basieren, eigenständig Aufgaben zu lösen, Entscheidungen zu treffen und auf menschliche Anforderungen zu reagieren. Der Aufbau solcher Systeme ist jedoch alles andere als trivial. Er erfordert einen klar strukturierten Entwicklungsprozess, bei dem die Evaluation der Anwendung in jeder Phase eine zentrale Rolle einnimmt. Dieser Ansatz wird als Evaluation Driven Development (EDD) bezeichnet und verspricht, die Qualität und Zuverlässigkeit agentischer Systeme signifikant zu verbessern.
Der Ausgangspunkt eines jeden Projekts im Bereich agentischer Systeme ist die präzise Definition des zu lösenden Problems. Nur wer sich darüber im Klaren ist, ob das Ziel tatsächlich mit KI oder traditioneller Software besser erreicht wird, kann Ressourcen effizient einsetzen. Die Abgrenzung der Problemstellung sowie das Verständnis der Zielgruppe und potenzieller Randfälle sind grundlegend. Ein weiterer wichtiger Aspekt ist die Festlegung der Grenzen akzeptablen Verhaltens des Systems, besonders im Hinblick auf ethische und sicherheitsrelevante Kriterien. Für diese Phase sind unterschiedliche Rollen involviert, allen voran AI-Produktmanager, Fachexperten und KI-Ingenieure, die gemeinsam eine fundierte Basis für den weiteren Entwicklungsprozess schaffen.
Viele Projekte scheitern nicht an technischen Aspekten, sondern daran, dass sie das falsche Problem adressieren. Deshalb gilt es, diese Phase besonders ernst zu nehmen. Im Anschluss erfolgt der Bau eines Prototyps. Dieser Schritt dient weniger der Perfektion als dem Lernen. Mithilfe von Notebooks oder No-Code-Tools können schnell erste Modelle auf kleineren Datensätzen ins Leben gerufen werden, um die technische Machbarkeit zu prüfen.
Diese Phase gilt als eine Art Risikominderung, da sie aufzeigt, ob die Idee langfristig umsetzbar ist. Hierbei wird viel experimentiert, beispielsweise mit verschiedenen Prompting-Strategien oder externen Tools wie Sprach-zu-Text-Plattformen. Auch wenn in dieser Phase keine optimale Performance erzielt wird, ist eine sorgfältige Dokumentation essenziell, um Fehlerquellen zu identifizieren und zu vermeiden. Die Zusammenarbeit zwischen AI-Produktmanagern und KI-Ingenieuren ist hierbei besonders wichtig, da durch den engen Austausch ein iterativer Prozess entsteht, der die Grundlage für die spätere Skalierung bildet. Ein entscheidender Faktor im gesamten Prozess ist die Definition von Leistungskennzahlen, die das Projekt aus geschäftlicher Sicht messbar machen.
Es reicht dabei nicht, technische Metriken wie Genauigkeit oder Antwortzeiten zu betrachten, sondern es muss ein Zusammenhang zu Geschäftszielen hergestellt werden. So kann ein übergeordnetes Ziel sein, die Nutzerzufriedenheit zu steigern oder Arbeitsabläufe effizienter zu gestalten. Darauf aufbauend werden Eingangsmetriken festgelegt, die direkt beeinflussbar sind und zur Erreichung des Ziels beitragen – etwa die durchschnittliche Bearbeitungszeit eines Support-Tickets. Eine klare Kommunikation mit den Stakeholdern gewährleistet, dass alle Seiten dieselben Erwartungen haben und der Geschäftswert des Systems stets im Griff bleibt. Schwierigkeiten ergeben sich oft bei der Festlegung und Anwendung von Evaluationsregeln.
Die Beurteilung von LLM-Ausgaben ist bekanntlich komplex, da menschliche Werte wie Kohärenz, Faktentreue oder Sicherheitsaspekte oft schwer quantifizierbar sind. Deshalb ist es ratsam, Evaluationdatensätze zu erstellen, die Eingangsdaten mit erwarteten Ergebnissen verbinden. Besonders wichtig ist auch die Definition von unerwünschten Antworten, etwa toxische Inhalte oder Halluzinationen, da diese das Vertrauen in das System untergraben können. Für jeden Knoten im System, in dem mehrere LLM-Aufrufe verknüpft sind, müssen solche Evaluationen vorliegen, um Schwachstellen frühzeitig zu identifizieren. Die Entwicklung eines Proof of Concept (PoC) ist eine weitere kritische Stufe, die häufig missverstanden wird.
Ziel ist es nicht, sofort eine voll funktionsfähige Oberfläche zu schaffen, sondern das System so schnell wie möglich echten Anwendern zugänglich zu machen, um echtes Nutzerfeedback einzuholen. Ein PoC kann dabei durchaus einfach gehalten sein, etwa in Form einer Tabelle mit Ein- und Ausgabedaten. Dieses frühe Feedback enthüllt oft unbekannte Herausforderungen und verändert die Sichtweise auf das Produkt. Der schnelle Rollout eines solchen Prototyps ist ein Indikator für einen effizienten Entwicklungsprozess und für den Erfolg des Projekts von großer Bedeutung. Parallel zur Entwicklung muss das System umfassend instrumentiert werden, um die nötige Transparenz zu schaffen.
Dabei ist es essenziell, alle Interaktionen zwischen Nutzern und dem System detailliert zu protokollieren. Dazu gehören Anfragen, Antworten der Modelle, Verarbeitungszeiten sowie Versionsinformationen zu verwendeten Prompts und Modellen. Außerdem sollten multimodale Datentypen wie Dokumente oder Audiodateien mit erfasst werden. Nutzerfeedback sollte stets mit den jeweiligen Abläufen verknüpft werden, um Ursachen von Fehlern präzise nachzuvollziehen. Diese Instrumentierung ist ein Grundpfeiler von Evaluation Driven Development und stellt sicher, dass die Analyse der Systemleistung auf aussagekräftigen Daten beruht.
Die Integration einer Observability-Plattform optimiert die Auswertung dieser umfangreichen Datenmengen. Solche Plattformen ermöglichen eine effiziente Visualisierung und Analyse sowie die Verwaltung von Evaluationsregeln und Prompt-Versionen. Da umfangreiche Trace-Daten schnell unüberschaubar und teuer werden können, kommen intelligente Sampling-Methoden zum Einsatz, um nur relevante Daten langfristig zu speichern. Die nahtlose Einbindung durch SDKs erleichtert die Integration in bestehende Systeme und stellt sicher, dass wichtige Informationen für die kontinuierliche Entwicklung jederzeit verfügbar sind. Basierend auf den erhobenen Daten finden automatisierte Evaluationen statt, die Schwächen und Fehler in den Systemantworten identifizieren.
Dabei spielen menschliches Feedback und ausgefeilte Bewertungsmethoden eine wichtige Rolle. Besonders Fokus auf die Daten, bei denen die Evaluierung nicht zufriedenstellend ausfällt, ist entscheidend für die stetige Verbesserung des Agenten. Da manche Bewertungsverfahren, insbesondere solche mit KI als Richter, kostenintensiv sein können, ist eine gezielte Stichprobenziehung ratsam. Die Evolution des agentischen Systems erfolgt unter der Prämisse, dass nicht alle Fehler vollständig eliminiert werden können, aber durch das fortlaufende Ergänzen der Fehlerdatenbanken eine Verbesserung erzielt wird. Die Komplexität des Systems kann bei Bedarf schrittweise erhöht werden, angefangen bei einfachen Prompts über Retrieval-Augmented Generation (RAG) bis hin zu multi-agentischen Architekturen.
Dabei gilt jedoch die Faustregel, dass eine höhere Komplexität nur bei klaren Anforderungen sinnvoll ist. Effektives Prompt Engineering, Datenvorverarbeitung und Integration externer Tools bieten häufig schon erhebliche Verbesserungen. Die Zusammenarbeit mit Fachexperten ist in dieser Phase unverzichtbar, denn sie bringen wichtige Insights und können auch helfen, bessere Prompts zu entwickeln. Sobald Verbesserungen umgesetzt sind, ist ein schnelles Deployment neuer Versionen essenziell. Der zeitnahe Rollout ermöglicht es, Nutzererfahrungen zu optimieren und unerwartete Probleme frühzeitig zu beheben.
Gleichzeitig müssen strenge Tests sicherstellen, dass neue Releases nicht schlechter als ihre Vorgänger sind. Automatisierte Release-Tests und die Integration in Continuous Integration/Continuous Deployment (CI/CD) Pipelines leisten hierzu einen wichtigen Beitrag. Die kontinuierliche Entwicklung und Weiterentwicklung bilden den Kern des Evaluation Driven Developments. Der Zyklus aus Bauen, Tracen, Feedback Sammeln, Evaluieren und Verbessern wird stetig wiederholt und sorgt dafür, dass das System agil auf sich ändernde Anforderungen reagiert. Falls neue Funktionen hinzukommen, durchlaufen sie denselben Prozess mit Prototyping, Definieren von Metriken und Evaluationsregeln.
Dies ermöglicht Teams, unabhängig voneinander an unterschiedlichen Systemkomponenten zu arbeiten und den Entwicklungsablauf effizient zu gestalten. Ein weiterer Vorteil des Evaluation Driven Developments zeigt sich im Bereich Monitoring und Alerting. Durch die umfangreiche Instrumentierung stehen nahezu alle relevanten Daten für ein effektives Produktionsmonitoring zur Verfügung. Dabei können spezielle Kennzahlen wie die Zeit bis zum ersten Token (Time To First Token) oder inter-token Latenzen überwacht werden. Um Fehlalarme und Alarmmüdigkeit zu vermeiden, müssen Schwellenwerte sorgfältig definiert werden.
Ein gut abgestimmtes Monitoring sorgt für stabile Systemverfügbarkeit und unterstützt proaktives Eingreifen bei Problemen. Zusammengefasst stellt Evaluation Driven Development eine speziell auf agentische Systeme zugeschnittene Methode dar, die über traditionelle Softwareentwicklungsverfahren hinausgeht. Der Fokus auf umfassende Evaluation, transparente Nachvollziehbarkeit und iterative Weiterentwicklung sorgt dafür, dass KI-Agenten praktisch nutzbar, wirtschaftlich sinnvoll und sicher betrieben werden können. Frühzeitige Festlegung von Geschäftszielen, intensive Zusammenarbeit aller relevanten Experten und der Einsatz moderner Observability-Tools sind dabei Erfolgsfaktoren. Entwickler, die diese Prinzipien beherzigen, vermeiden häufige Stolpersteine und schaffen Produkte, die den hohen Anforderungen der heutigen KI-getriebenen Welt gerecht werden.
Die Zukunft agentischer Systeme wird maßgeblich von solchen Entwicklungsansätzen geprägt sein, die Effektivität und Vertrauen gleichermaßen in den Mittelpunkt stellen.