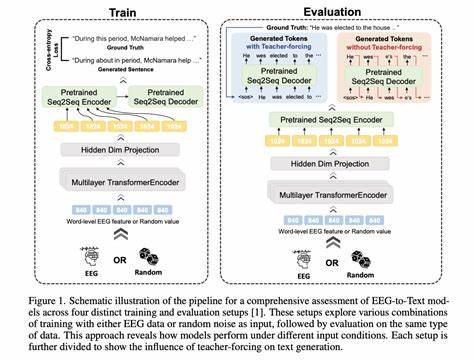
Die rasante Entwicklung im Bereich der Gehirn-Computer-Schnittstellen hat in den letzten Jahren enorme Fortschritte gemacht, insbesondere bei der dekodierenden Übersetzung von Gehirnsignalen in verständliche Sprache. Die Elektroenzephalografie (EEG), als eine nicht-invasive Methode zur Erfassung elektrischer Aktivität im Gehirn, stellt eine vielversprechende Grundlage für die Generierung von Texten dar, die direkt aus neuronalen Signalen abgeleitet werden können. Die EEG-zu-Text Generierung hat das Potenzial, Menschen mit Kommunikationsbehinderungen neue Wege zu eröffnen und die Forschung in den Neurowissenschaften und der Künstlichen Intelligenz maßgeblich voranzutreiben. Dennoch stehen Wissenschaftler vor der Herausforderung, die generierten Texte nicht nur syntaktisch korrekt, sondern vor allem semantisch treu zur ursprünglichen neuronalen Aktivität zu gestalten. Dies erfordert innovative Methodologien, die über reine Mustererkennung hinausgehen und die Bedeutung der Gehirnsignale wirklich erfassen und reflektieren.
Im Zentrum dieser neuen Herangehensweise steht das Konzept der semantisch glaubhaften EEG-zu-Text Generierung, das darauf abzielt, Halluzinationen oder frei erfundene Inhalte der Sprachmodelle zu minimieren und stattdessen die Kernbedeutung der vom Gehirn aktivierten Inhalte wiederzugeben. Ein Vorreiter in diesem Bereich ist das Generative Language Inspection Model, kurz GLIM, das auf dem neuesten Stand der Technik basiert und die EEG-Daten dazu nutzt, verständliche, interpretierbare und semantisch treffende Texte zu erzeugen. GLIM legt den Fokus auf das Lernen informativer EEG-Repräsentationen und balanciert die Informationsdiskrepanz zwischen den begrenzten EEG-Daten und der komplexen Semantik von Sprache aus. Dieses Modell verzichtet auf das traditionelle Vorgehen, bei dem versucht wird, den exakten Wortlaut der Gedanken oder Stimuli zu rekonstruieren, und setzt stattdessen auf semantische Zusammenfassung. Dies reduziert das Risiko, dass das System reine Halluzinationen produziert oder unzutreffende Sätze generiert, die den wahren Gehalt der Gehirnaktivität nicht widerspiegeln.
Die Bedeutung eines solchen Modells wird besonders deutlich im Umgang mit heterogenen und kleinen Datensätzen, wie sie in der medizinischen Forschung oder bei seltenen Sprachen und Dialekten häufig vorkommen. Durch die Verbesserung der semantischen Verankerung erhöhen sich die Verlässlichkeit und Skalierbarkeit der EEG-zu-Text Systeme erheblich, was auch die Grundlage für zukünftig umfassendere und robustere Anwendungen bildet. Ein bedeutendes Testfeld für GLIM ist das öffentlich verfügbare ZuCo-Datenset, das EEG-Aufzeichnungen während verschiedener Lese- und Sprachverstehensaufgaben enthält. Die Anwendung des Modells auf diese Datensätze zeigt, dass es gelingt, flüssige und inhaltlich stimmige Sätze zu generieren, die eng mit den EEG-Daten korrespondieren. Darüber hinaus eröffnet GLIM neue Evaluationsansätze, die nicht nur auf textuellen Ähnlichkeitsmaßen basieren, sondern tiefere Verbindungen zwischen EEG und Sprache überprüfen.
Insbesondere die EEG-Text-Retrieval-Methodik ermöglicht es, zu messen, wie gut der erzeugte Text mit den ursprünglichen Gehirnsignalen übereinstimmt, während das Zero-Shot-Semantic-Classification-Verfahren in Bereichen wie Sentiment-Analyse, semantischer Relation und Themenklassifikation zeigt, dass die erzeugten Texte substanzielle semantische Inhalte transportieren. Diese vielschichtigen Evaluationsprotokolle sind ein Schlüssel zur Absicherung der Glaubwürdigkeit und zur Minimierung von Verzerrungen bei generativen Modellen in der Gehirn-Decodierung. Der Fortschritt bei der semantisch treuen EEG-zu-Text Generierung hat weitreichende praktische Implikationen. In der Medizin könnte es Betroffenen mit Aphasie oder motorischen Einschränkungen ermöglichen, Gedanken schneller und effizienter in Text umzusetzen und dadurch die Kommunikation erheblich verbessern. In der Neurowissenschaft bietet diese Technologie neue Werkzeuge zur Erforschung der neuronalen Repräsentation von Sprache, Gedanken und Emotionen.
In der KI-Forschung wiederum steht die Verbesserung interpretierbarer Modelle im Vordergrund, die nicht nur Outputs erzeugen, sondern deren Entscheidungen und Inhalte auch nachvollziehbar sind. Die Integration von EEG-Daten in generative Sprachmodelle wirft jedoch auch ethische Fragestellungen auf. Der Schutz der Privatsphäre neuraler Daten sowie die Vermeidung von Fehlinterpretationen oder Missbrauch von Gehirnprodukten erfordern klare Richtlinien und ethische Standards. Das Verständnis und die Entwicklung semantisch verankerter EEG-zu-Text-Technologien sind somit auch eine gesellschaftliche Herausforderung, die Sensibilität und Verantwortungsbewusstsein verlangt. Zusammenfassend markiert die semantisch treue EEG-zu-Text Generierung einen Meilenstein in der Interaktion zwischen Mensch und Maschine, indem sie Brücken zwischen neuronalen Prozessen und natürlicher Sprache schlägt.
Mit Modellen wie GLIM werden nicht nur die Grenzen der maschinellen Interpretation von Gehirnsignalen verschoben, sondern auch der Weg geebnet für neue Kommunikationstechnologien, die individuell, präzise und sinnstiftend sind. Die Weiterentwicklung und breite Anwendung dieser Verfahren können langfristig die Lebensqualität vieler Menschen verbessern und das Verständnis über das menschliche Gehirn deutlich erweitern. Die Zukunft der EEG-basierten Textgenerierung sieht daher vielversprechend aus, getragen von interdisziplinärer Forschung und dem unermüdlichen Streben nach einer nahtlosen Verbindung von Geist und Sprache.








