Die kausale Inferenz ist ein zentraler Bestandteil moderner Forschung, der es uns ermöglicht, Ursache-Wirkungs-Beziehungen in komplexen Systemen zu verstehen. Anders als bei rein korrelativen Analysen steht bei der kausalen Inferenz die Frage im Mittelpunkt, wie ein bestimmtes Ereignis oder eine Handlung tatsächlich einen Effekt auf ein Resultat hat. Dabei spielt es eine enorme Rolle, Verzerrungen zu erkennen und zu kontrollieren, um valide und belastbare Aussagen treffen zu können. Der Umgang mit Kausalität ist in vielen Fachgebieten wie der Medizin, den Sozialwissenschaften, der Ökonometrie und zunehmend auch in der Technologie-Branche von großer Bedeutung, insbesondere wenn es um Entscheidungsfindungen basierend auf Daten geht. Dabei geht es nicht nur darum, festzustellen, ob ein Zusammenhang besteht, sondern vor allem darum zu verstehen, ob und wie eine Intervention den Ausgang verändert.
Dieser Fokus auf das „Warum“ bildet das Herzstück der kausalen Inferenz und verlangt nach Methoden, die über herkömmliche statistische Modelle hinausgehen. Ein innovativer und zugänglicher Ansatz zur kausalen Inferenz ist im Buch "Causal Inference for the Brave and True" zu finden. Es verbindet die theoretischen Grundlagen mit praktischen Anwendungen und macht die komplexen Konzepte durch Python-Programmierung greifbar. Die Kombination aus rigoroser Wissenschaft und humorvoller, verständlicher Darstellung macht es sowohl für Einsteiger als auch für Fortgeschrittene zu einer wertvollen Ressource. Das Buch gliedert sich in zwei Hauptteile, die sich in ihrer Ausrichtung unterscheiden, aber aufeinander aufbauen.
Der erste Teil widmet sich den klassischen Methoden der Kausalinferenz. Hier lernen Leser, wie randomisierte Experimente gestaltet werden, wie man Bias erkennt und eliminiert und wie grafische Modelle dabei helfen, kausale Zusammenhänge besser zu verstehen. Besonders hervorzuheben ist die Behandlung linearer Regression als Werkzeug zur Schätzung von Effekten und das Eingehen auf typische Probleme wie Konfundierung oder Nicht-Einhaltung von Behandlungsbedingungen. Methoden wie Instrumentvariablen, Matching-Verfahren, Propensity Scores, Differenzen-in-Differenzen oder Regression Discontinuity Design werden ausführlich erläutert. Diese Werkzeuge bilden das Fundament, mit dem kausale Fragen robust und methodisch sauber beantwortet werden können.
Der zweite Teil des Buches richtet den Blick auf moderne Entwicklungen und Anwendungen im Bereich der kausalen Inferenz, die vor allem in der Technologie- und Datenindustrie relevant sind. Hier stehen personalisierte und heterogene Behandlungseffekte im Fokus, das heißt, wie sich Effekte auf unterschiedliche Individuen oder Gruppen unterschiedlich auswirken können. Die Herausforderung besteht darin, nicht nur einen durchschnittlichen Effekt zu bestimmen, sondern die Varianz der Effekte zu modellieren und dadurch präzisere und individualisierte Vorhersagen zu ermöglichen. Dabei kommen fortgeschrittene maschinelle Lernverfahren zum Einsatz, etwa Debiased Machine Learning, Meta-Learners oder orthogonalisierte Schätzverfahren. Die große Herausforderung in diesem Bereich ist das Zusammenspiel von nichtlinearer Effektheterogenität und komplexen Datenstrukturen.
Gleichzeitig setzt dieses Gebiet auf experimentelle und empirische Forschung, die ständig weiterentwickelt wird, sodass die Methoden noch nicht vollständig ausgereift sind, aber enormes Potenzial besitzen. Neben den technischen Inhalten verbindet „Causal Inference for the Brave and True“ die ökonometrische Tradition mit praktischen Beispielen, Referenzen und einer klaren didaktischen Linie. Das Buch ehrt Pioniere wie Joshua Angrist oder Alberto Abadie und schlägt eine Brücke von klassischer Ökonometrie zu modernen datengetriebenen Analyseverfahren. Die Verfügbarkeit komplett in Python ermöglicht einen niederschwelligen Einstieg für Fachleute, die über statistisches Wissen verfügen, aber weniger Erfahrung im Programmieren haben. Dabei wird das Open-Source-Prinzip verfolgt, um die Inhalte für möglichst viele Menschen global frei zugänglich zu machen und eine Community aufzubauen, die gemeinsam das Wissen vorantreibt.
Die Bedeutung kausaler Inferenz geht weit über akademische Fragestellungen hinaus. In der Wirtschaft ermöglichen bessere kausale Modelle effektivere Marketingkampagnen, optimierte Produktentwicklungen und fundierte Geschäftsentscheidungen. In der Medizin unterstützen sie die Bewertung von Therapien und Gesundheitsinterventionen. In der öffentlichen Verwaltung können politische Maßnahmen durch robuste kausale Analysen auf ihre Wirksamkeit und Effizienz untersucht und bewertet werden. Das Verständnis und die Anwendung kausaler Konzepte sind somit Schlüsselqualifikationen in der datengetriebenen Welt von heute.
Die zentrale Herausforderung bei kausalen Studien ist stets die Kontrolle von Bias oder Verzerrung. Ob durch nicht beobachtete Störfaktoren, Nicht-Einhaltung experimenteller Bedingungen oder zeitliche Veränderungen – jede Störung kann die Interpretation der Ergebnisse grundlegend verändern. Daher spielen fortgeschrittene Methoden eine entscheidende Rolle, um diese Fallen zu erkennen und zu umgehen. Gleichwohl ist auch die Fähigkeit zur kritischen Reflexion unerlässlich, denn nicht jede Kausalfrage lässt sich mit klassischen oder modernen Verfahren gleichermaßen scharf beantworten. Ein tieferes Verständnis von Ursache und Wirkung fordert neben mathematischem Know-how auch ein Gespür für die inhaltlichen Zusammenhänge.
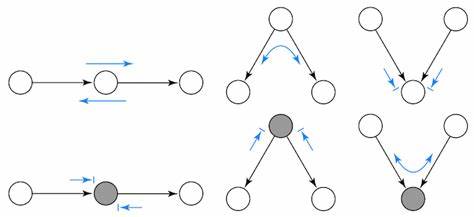
Die grafische Modellierung kausaler Zusammenhänge ist hierbei ein besonders hilfreiches Werkzeug. Sie macht Abhängigkeiten sichtbar und erleichtert den Einsatz passender Schätzverfahren, indem sie zeigt, welche Variablen gemessen oder kontrolliert werden müssen. Diese Visualisierung ist nicht nur für Theoretiker von Bedeutung, sondern auch für Praktiker, die komplexe Datensätze interpretieren. Ein weiterer faszinierender Aspekt der kausalen Inferenz liegt in der Gegenüberstellung von durchschnittlichen und heterogenen Behandlungseffekten. Durchschnittswerte geben zwar einen Überblick, können aber wichtige Details verschleiern.
Insbesondere in der personalisierten Medizin oder beim Targeting von Werbekampagnen können individuelle Unterschiede den Unterschied zwischen Erfolg und Misserfolg bedeuten. Moderne Ansätze bemühen sich daher, diese Heterogenität zu erfassen und präzise modellieren zu können. Insgesamt eröffnet das Thema kausale Inferenz eine Welt, in der Zahlen lebendig werden und aus Daten greifbare Erkenntnisse entstehen, die Handlungsempfehlungen unterlegen. Sie ist eine Brücke von Daten zu Wissen und von Wissen zu Entscheidungen. Wer sich in dieser Disziplin weiterbildet, legt nicht nur ein solides statistisches Fundament, sondern erwirbt auch Fähigkeiten, mit denen er die Herausforderungen der Datenanalyse von morgen meistern kann.
In einer Zeit, in der Daten in rasantem Tempo wachsen und immer mehr Entscheidungen datenbasiert getroffen werden, gewinnt die Fähigkeit, wirklich kausale Zusammenhänge zu erkennen, einen immer höheren Stellenwert. So wird aus Statistik eine Wissenschaft der Ursachen – mutig, präzise und praxisnah.








