Im Zeitalter der Digitalisierung und datengetriebener Entscheidungen spielen Data Engineers eine zentrale Rolle, um wertvolle Erkenntnisse aus großen Datenmengen zu gewinnen. Doch trotz der immer besser werdenden Technologien und Tools berichten viele Experten und Praktiker aus der Realität, dass explorative datenbezogene Aufgaben oft mit erheblichen Frustrationen und Herausforderungen verbunden sind. Diese Tätigkeiten sind meist der erste Schritt, um Datensätze auf ihre Qualität, Struktur und ihre Bedeutung hin zu untersuchen, bevor aufwendigere Analysen oder Modelle darauf aufbauen können. Ein genauer Blick auf die Erfahrungsberichte von Data Engineers bringt verschiedene Schmerzpunkte ans Licht, die gleichermaßen technischer, organisatorischer und menschlicher Natur sind. Ein besonders häufig erwähnter Aspekt ist der Umgang mit organisatorischen Barrieren, die sich in sogenannten „Org Silos“ manifestieren.
Diese Silos trennen oft Teams oder Abteilungen voneinander, was den Zugang zu notwendigen Daten erschwert oder sogar blockiert. Data Engineers berichten davon, wie Sicherheitsvorschriften und Berechtigungen die Arbeit erheblich verzögern können. Da Produktionsdaten in der Regel sensibel sind, geben Teams ihre direkten Zugriffsrechte nur äußerst ungern frei, was verständlicherweise dem Datenschutz und der IT-Sicherheit dient. Die logisch folgende Alternative – der Zugriff über APIs – erweist sich ebenfalls oft als unbefriedigend. Viele Schnittstellen sind dafür ausgelegt, einzelne Datensätze abzufragen und arbeiten mit vergleichsweise langsamer Geschwindigkeit, sodass ein bulkartiger Datenzugriff, der für explorative Aufgaben oft nötig ist, erschwert wird.
Die Folge sind lange Wartezeiten, ineffiziente Prozesse und manchmal sogar Zwist zwischen den Teams. Neben diesen organisatorischen Herausforderungen kommt die oft beklagte „Arbeit über die Arbeit“ hinzu. Dies beschreibt die mühsame, sich wiederholende Tätigkeit, Informationen zwischen diversen Kommunikations- und Kollaborationstools wie Slack, Jira, Notion und anderen Plattformen hin- und herkopieren zu müssen. Data Engineers empfinden diesen ständigen Medienbruch als nervenaufreibend und ineffizient, da er viel Zeit und Energie kostet, die besser in die eigentliche Datenanalyse investiert werden könnte. Die fragmentierte Wissensvermittlung führt zudem häufig zu Missverständnissen und Informationsverlust, was den Fortschritt bei explorativen Forschungsaufgaben zusätzlich bremst.
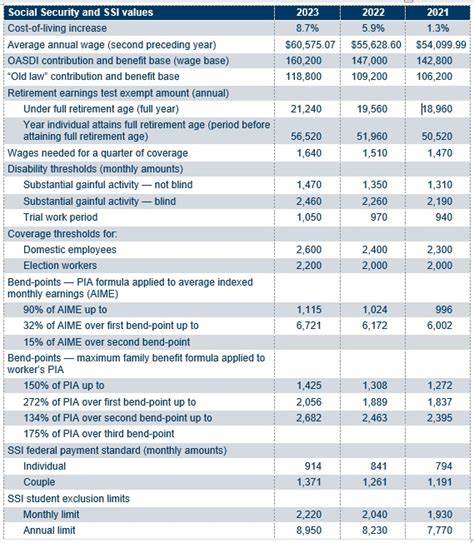
Ein zentraler technischer Stolperstein ist der oftmals langwierige und komplexe Prozess des Datenreinigens. Rohdaten sind selten vollständig korrekt oder konsistent und enthalten vielfältige Fehler, Inkonsistenzen oder fehlende Werte, die vor einer Analyse bereinigt werden müssen. Besonders wenn Daten aus unterschiedlichen Quellen, Ländern oder Systemen zusammengeführt werden, kann die „menschliche Komponente“ zu enormen Problemen führen. So berichten Praktiker von absurd vielen Schreibfehlern, verschiedensten Formaten, falschen oder fehlenden Informationen, besonders bei geographischen Daten wie Ländernamen oder Adressen. Die Folge ist, dass ein erheblicher Teil der Aufgabe darin besteht, Daten so zu korrigieren, dass sie überhaupt sinnvoll verarbeitet werden können.
Dabei helfen zwar automatisierte Tools oder Validierungsmechanismen, doch angesichts der Datenmengen und der Vielfalt der Fehler ist dieser Schritt oft sehr ressourcenintensiv und frustrierend. Die Auswahl und der Umgang mit geeigneten Werkzeugen ist ein weiterer Punkt, der Unmut erzeugt. Viele Data Engineers fühlen sich in bestimmten Bereichen weiterhin stark an gängige Technologien wie SQL oder Python mit Pandas gebunden, obwohl diese für explorative Analysen nicht immer die optimalen Lösungen bieten. Auch das Visualisieren der Daten über gängige Plotting-Bibliotheken wird oft als suboptimal empfunden, da diese in der Usability oder Flexibilität nicht immer überzeugen. Hier zeichnen sich jedoch langsam Veränderungen ab, da neue Technologien und vor allem Ansätze mit künstlicher Intelligenz und großen Sprachmodellen das Potenzial haben, das Datenhandling in Zukunft effizienter und intuitiver zu gestalten.
Ein besonders interessanter Beitrag aus der Community hebt hervor, dass viele Ärgernisse weniger mit den Daten selbst zu tun haben, sondern mit der Art und Weise, wie Kommunikation und Aufgabenmanagement in Unternehmen organisiert sind. Der ständige Wechsel zwischen Chat, Ticketing-Systemen und Dokumenten führt zu Zeitverlust und Demotivation. Das Bewusstsein für diese „Fake Work“ genannte Verschwendung ist bei Gründern und Entwicklern präsent, die versuchen, Tools zu entwickeln, welche den Diskurs mit Aufgaben und Dokumentation nahtlos verbinden, um den Aufwand für Kontextwechsel zu minimieren. Darüber hinaus ist die Problematik nicht nur technischer oder organisatorischer Natur. Die Wahrnehmung von Data Engineering als eine Tätigkeit, die sich immer wieder mit bürokratischen Hindernissen konfrontiert sieht, spiegelt sich auch in der Haltung von Unternehmen wider.
Viele Organisationen konzentrieren sich auf Prozesse und Compliance, während die eigentlichen Ziele und Fragestellungen, die mit Daten angewendet werden sollen, oft nur eine untergeordnete Rolle spielen. Daraus resultiert eine Diskrepanz zwischen den Anforderungen der Datenfachleute und den Erwartungen von Stakeholdern, die zu ineffizienten Abläufen führen kann. Eine weitere Facette betrifft das Fehlen klar definierter Product Owner oder Verantwortlicher für Datenprodukte. Data Engineers müssen oft selbst die Anforderungen an explorative Datentätigkeiten ergründen, was zusätzlichen Aufwand verursacht und die Effektivität einschränkt. Da diese Rolle häufig nicht formal besetzt ist, besteht ein Kommunikations- und Verantwortlichkeitsvakuum, das ebenfalls die Arbeit erschwert.
Im Bereich der Datenvalidierung und -qualität werden Ansätze diskutiert, die bereits bei der Datenerfassung für mehr Prävention sorgen sollen. Beispielsweise ermöglichen systematische Vokabulare oder sogenannte Dictionaries, die gültige Werte für bestimmte Felder vorgeben, Fehler schon beim Dateninput zu erkennen und abzufangen. Einige innovative Systeme versuchen sogar, durch automatische Korrekturvorschläge fehlerhafte Eingaben zu berichtigen, was gerade bei der Masse an Daten ein vielversprechender Ansatz ist. Allerdings sind Korrekturen bei relationalen oder zusammengesetzten Daten, wo falsche Kombinationen von Werten vorliegen, noch eine große Herausforderung. Zusammengefasst zeigt sich, dass die Arbeit von Data Engineers bei explorativen Datenaufgaben sehr vielschichtig mit einer Reihe von Reibungspunkten verbunden ist.
Organisatorische Barrieren und Zugriffsregelungen schaffen grundlegende Hindernisse, die oft zuerst überwunden werden müssen. Der lange, oft monoton wirkende Prozess der Datenbereinigung und -validierung ist technisch und menschlich fordernd. Die Werkzeuge erfüllen nicht immer die Erwartungen, und ineffiziente Kommunikations- und Dokumentationsprozesse verschlingen wertvolle Zeit. Die Rolle der Datenverantwortlichen, klare Ziele und pragmatische organisatorische Unterstützung spielen eine entscheidende Rolle, um diese Herausforderungen zu mindern. Zukünftige Trends und technologische Fortschritte, insbesondere im Bereich der künstlichen Intelligenz und integrierten Plattformen, eröffnen Chancen, einige der genannten Probleme zu adressieren.
Gleichzeitig bleibt der menschliche Faktor – von der Datenqualität bis zu den internen Prozessen und Verantwortlichkeiten – eine zentrale Größe, ohne deren Berücksichtigung langfristige Verbesserungen schwer zu realisieren sind. Für Unternehmen, die ihre Datenarbeit effektiv gestalten wollen, ist daher ein ganzheitliches Verständnis der vielfältigen Probleme essenziell, um gezielt Lösungen zu entwickeln und produktive Arbeitsumgebungen für Data Engineers zu schaffen.