In den letzten Jahren hat sich die Fähigkeit neuronaler Netzwerke, natürliche Sprache zu modellieren und zu generieren, enorm weiterentwickelt. Diese Fortschritte eröffnen zahlreiche Anwendungen in der offenen Textgenerierung, wie das automatische Verfassen von Geschichten, Dialogsysteme oder kreative Aufgaben. Trotz dieser Entwicklungen sind herkömmliche Likelihood-Maximierungsverfahren wie Greedy Search oder Beam Search für offene und unvorhersehbare Textlängen häufig ungeeignet. Sie führen oft zu repetitiven, wenig überzeugenden und inhaltlich begrenzten Ausgaben, die der Vielfalt und Kreativität menschlicher Sprache nicht gerecht werden. Hier setzt Tail Free Sampling (TFS) an – ein neuartiger Sampling-Ansatz, der auf der Idee der „Replaceability“ von Wörtern basiert und dadurch eine bessere Balance zwischen Qualität und Diversität beim Textgenerieren schafft.
Seit dem ursprünglichen Beitrag von Trenton Bricken im Jahr 2019 ist Tail Free Sampling eine vielversprechende Alternative zu klassischen Sampling-Verfahren wie Top-K und Nucleus Sampling. Während diese traditionellen Methoden darauf abzielen, die Menge der Wörter, aus der für jede Position im Text generiert wird, zu beschränken – um besteht ein Gleichgewicht zwischen zu wenig und zu viel Unsicherheit –, geht TFS einen Schritt weiter. Statt sich nur auf Wahrscheinlichkeitsmassen oder eine feste Anzahl der wahrscheinlichsten Wörter zu konzentrieren, bewertet Tail Free Sampling die sogenannte zweite Ableitung der Wortwahrscheinlichkeiten. Diese gibt Auskunft darüber, an welchem Punkt die Wahrscheinlichkeitskurve in eine Art Plateau übergeht, was als „Tail“ der Verteilung interpretiert wird. Wörter hinter diesem Punkt gelten als nicht mehr „replaceable“ bzw.
austauschbar und werden aus dem Sampling herausgefiltert. Die Herausforderung der offenen Textgenerierung liegt darin, sinnvolle und vielfältige Wörter auszuwählen, die zum bisherigen Kontext passen. In kurzen, eng begrenzten Satzkontexten wie "Der Hund sitzt auf der ___" ist die Auswahl an sinnvollen Ergänzungen klein und konzentriert sich auf wenige, hochwahrscheinliche Wörter wie „Matte“. In anderen Kontexten etwa „Ich esse gerne ___“ kann die Bandbreite an möglichen Wörtern extrem groß sein. Ein starres Verfahren wie Top-K-Sampling mit fixe K wert überschießt in einigen Kontexten oder greift zu kurz in anderen.
Nucleus Sampling versucht dieses Problem durch ein dynamisches Anpassen des Wortschatzes, indem es eine Wahrscheinlichkeitsmasse (etwa 90 %) abdeckt, behält jedoch keine explizite Form der Ableitungen oder Kurvensteigungen der Wahrscheinlichkeitsverteilung im Blick. Tail Free Sampling hingegen nutzt die Form der Wahrscheinlichkeitsverteilung selbst als Signal: Durch die Analyse der zweiten Ableitung erkennt die Methode den Wendepunkt, an dem die Auswahl an „ersetzbaren“ Wörtern endet. Dieses Vorgehen ermöglicht es, situationsgerecht zwischen sehr wenigen sinnvollen Token und einer breiteren, diverseren Auswahl abzuwägen. So kann TFS in manchem Kontext gerade einmal ein Dutzend hochwahrscheinliche Tokens zulassen, in anderen hingegen deutlich mehr. Der Hyperparameter z in TFS definiert eine Schwelle für die kumulative Verteilung der zweiten Ableitung, um den Tail zuverlässig zu identifizieren.
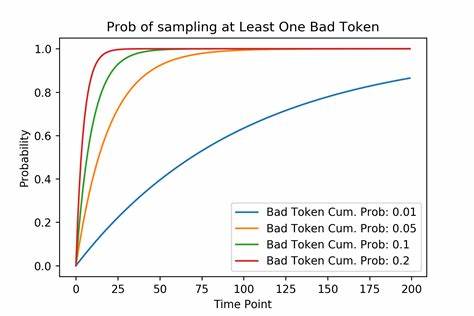
Praktische Erfahrungen zeigen, dass Werte von z zwischen 90 % und 99 % meist gute Ergebnisse liefern und robuster gegenüber unterschiedlichen Kontexten sind als vergleichbare Einstellungen bei Nucleus Sampling. Ein zentrales Problem, das bei offenen Textgenerierungsmethoden stets zu beachten ist, ist die Gefahr des „Derailments“, also des Abweichens des generierten Textes in irrelevante oder unsinnige Bereiche. Da ein Fehler früh im Textausgabeprozess jede weitere Wortauswahl beeinflusst, ist die konsequente Vermeidung schlechter Token essenziell. Dabei steigt die Wahrscheinlichkeit, mit zunehmender Textlänge einen Fehler zu ziehen, exponentiell an. Tail Free Sampling minimiert dieses Risiko, indem es extrem unwahrscheinliche und damit wenig sinnvolle Wörter rigoros ausschließt, aber dennoch genug Auswahlmöglichkeiten behält, um kreative und vielfältige Ergebnisse zu erzielen.
Die Validierung von TFS erfolgte über umfangreiche Experimente mit dem bekannten Sprachmodell GPT-2 (345 Mio. Parameter) und dem Reddit Writing Prompts Datensatz. In der Analyse wurden über 13.000 einzelne Sampling-Schritte betrachtet, bei denen sowohl Nucleus Sampling als auch Tail Free Sampling angewandt und verglichen wurden. Dabei zeigte sich, dass die beiden Methoden in gut 15 % der Fälle exakt die gleiche Schnittmenge an Tokens auswählten.
In nahezu der Hälfte aller Fälle hingegen war TFS strenger, also hielt sich bei der Auswahl enger an den Bottom Line für wahrscheinliche Wörter, während Nucleus Sampling in etwa 38 % der Fälle großzügiger in der Wahl war. Diese Unterschiede können sich stark auf die Güte und Kohärenz der generierten Texte auswirken. Als Beispiel konnte gezeigt werden, dass eine zu großzügige Auswahl die Gefahr erhöht, schlechte und wenig kontexttreue Wörter zu generieren, welche das generierte Werk letztlich „entgleisen“ lassen. Ein weiterer interessanter Befund findet sich in der Auswertung der Diversität der generierten Texte. Während strikt wahrscheinlichkeitsmaximierende Verfahren (wie Greedy Search) nur einige Worte stark bevorzugen und repetitive Muster erzeugen, liegt die Verteilung bei Tail Free Sampling sehr nah an der von menschlichen Texten beobachteten Vielfalt.
Im Vergleich zu Top-K mit einem festen K oder Nucleus Sampling generiert TFS eine ähnliche oder leicht höhere Diversität, was als Zeichen für natürlichere, lebendigere Sprache gewertet wird. Hinsichtlich Rechenaufwand ist das durch die Analyse der zweiten Ableitung komplexere Tail Free Sampling gut optimierbar und weist nur geringe Verzögerungen gegenüber Top-K und Nucleus Sampling auf. Auf GPUs oder im parallelen Betrieb sind diese Mehraufwände minimal und stellen keinen praktischen Nachteil dar. Top-K profitiert zwar von hardware-optimierten Algorithmen zur Selektion der wahrscheinlichsten Tokens, jedoch ist der Aufwand für die mathematischen Operationen hinter TFS in heutigen Arbeitsumgebungen problemlos handhabbar. Die bislang eröffnete größte Herausforderung beim Tail Free Sampling liegt in der empirischen Validierung seiner Vorteile.
Klassische Messgrößen oder menschliche Bewertungen zeigen nur schwer signifikante Unterschiede zu Nucleus Sampling oder Top-K, da beide Methoden bereits die Wahrscheinlichkeit verteilter Token beschränken und im Allgemeinen vergleichbar gute, qualitativ hohe Texte produzieren. Es sind vor allem jene niedrigen Wahrscheinlichkeiten am Rande der Verteilung, die den Qualitätsunterschied ausmachen, bei denen jedoch durch die geringe Häufigkeit genug Daten schwer zu erheben sind. Auch ist die Bewertung durch Menschen kosten- und zeitintensiv, da mehrere Juroren pro Text nötig sind, um verzerrte oder unsichere Urteile zu vermeiden. Ein innovativer Schritt in der Erforschung von Tail Free Sampling war die Durchführung von Crowdsourcing-Experimenten via Amazon Mechanical Turk, bei denen menschliche Bewertungen zur „Ersetzbarkeit“ einzelner Wörter im Kontext erhoben wurden. Evaluatoren wurden aufgefordert, für sieben ausgesuchte Wörter, unter anderem das Originalwort und mehrere Token aus verschiedenen Wahrscheinlichkeitsabständen, die Plausibilität zu bewerten.
Dadurch konnte eine Beziehung zwischen der von GPT-2 errechneten Token-Wahrscheinlichkeit und deren menschlicher Replaceability nachgewiesen werden. Dennoch waren die Daten insgesamt zu verrauscht, um conclusiv belegen zu können, dass TFS in der Praxis Ersatzbarkeit genauer trifft als Nucleus Sampling. Tail Free Sampling stellt aufgrund seiner theoretischen Fundierung, seiner situativen Robustheit und günstigen Eigenschaften eine wertvolle Erweiterung im Werkzeugkasten für offene Textgenerierung dar. Es empfehlen sich künftige Forschungen, um die Methodik weiter empirisch zu evaluieren und zu verfeinern – beispielsweise durch speziell ausgelegte User-Studien, automatisierte Fehlererkennung in generierten Texten oder die Anwendung auf andere neuronale Modelle und Domänen. Solange keine methodisch robusten Vergleiche vorliegen, ist TFS eine empfehlenswerte Alternative für alle, die in der offenen Textgenerierung sowohl qualitativ hochwertige als auch vielfältige Ergebnisse erzielen wollen.
Zusammenfassend lässt sich sagen, dass Tail Free Sampling das Problem der „Tail“-Identifikation in Wahrscheinlichkeitsverteilungen durch eine mathematisch elegante und konsequente Methode löst. Es adressiert bekannte Schwächen erstarrter Wortauswahltechniken und bietet Kennern der KI-Textgenerierung ein Instrument, mit dem die Balance zwischen Sicherheit und Kreativität wesentlich besser gesteuert werden kann. Die Zukunft der KI-basierten Textgenerierung wird maßgeblich von solchen adaptiven, kontextsensiblen Verfahren geprägt sein, die Tail Free Sampling bereits heute vorgibt.