In der schnelllebigen Welt der Künstlichen Intelligenz (KI) markiert die Veröffentlichung von DeepSeek-R1 im Januar 2025 einen bedeutenden Meilenstein. DeepSeek-R1 ist ein Open-Weights-Modell mit beeindruckenden Fähigkeiten im Bereich des logischen und mathematischen Reasonings, welches auf Benchmark-Performance auf Augenhöhe mit OpenAIs o1-Modell operiert. Trotz der enormen technischen Leistungsfähigkeit haben Diskussionen und Spekulationen über die tatsächlichen Trainingskosten und die gezeigte Effizienz für Aufsehen gesorgt. Um dieses Modell besser zu verstehen, lohnt es sich, die Kernelemente seiner Architektur, den Trainingsprozess und die Innovationsschritte genauer zu betrachten. Dabei zeigt sich eine Mischung aus bewährter Technik und neuartigen Ansätzen, die DeepSeek-R1 zu einem solch leistungsstarken Modell gemacht haben.
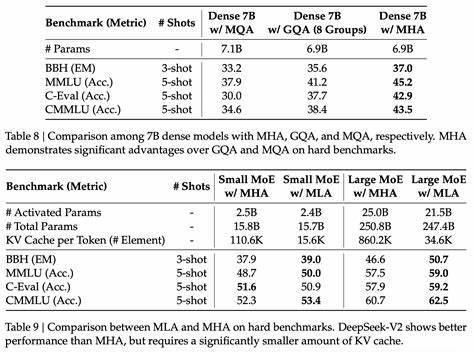
Die Architektur von DeepSeek-R1 baut auf der Basis des Vorgängermodells DeepSeek v3 auf, welches bereits im Dezember 2024 veröffentlicht wurde. Das Modell zeichnet sich durch eine sehr große Anzahl an Parametern aus – insgesamt 671 Milliarden – wobei pro Token stets nur rund 37 Milliarden aktiv sind. Dies wird durch eine Sparse Mixture-of-Experts (MoE)-Architektur ermöglicht, welche Experten in zwei Kategorien unterteilt: Zum einen gibt es einen „Shared Expert“, der für jeden Token aktiviert wird, zum anderen 256 „Routed Experts“, von denen jeweils acht für einen gegebenen Token aktiv sind. Diese Aufteilung sorgt für eine effiziente Verwendung der Rechenressourcen, da nur ein Bruchteil der Gesamtparameter für die Verarbeitung jedes einzelnen Tokens benötigt wird. Ein besonders zukunftsweisendes Element ist das sogenannte Multi-Head Latent Attention (MLA), das in DeepSeek v3 eingeführt wurde.
Dieses neuartige Aufmerksamkeitsmechanismus-Design reduziert die Größe des Key-Value-Caches erheblich, ohne die Performance einzuschränken – ein Problem, das viele andere Ansätze wie grouped-query attention oder multi-query attention nicht beherrschen. Allerdings führt das MLA zu einem höheren Rechenaufwand pro Token während der Decodierung, wodurch DeepSeek anders als viele andere Modelle bei längeren Kontexten eher arithmetisch als speichergebunden arbeitet. Dies manifestiert sich etwa darin, dass ab etwa 5000 Tokens der Rechenaufwand für die Attention vergleichbar ist mit den Parameter-Multiplizierungen, während bei Modellen wie Llama 3 70B dieser Punkt erst bei 50.000 Tokens erreicht wird. Die Bedeutung dieser Architekturinnovationen kann nicht hoch genug eingeschätzt werden.
Zwar sind viele der eingesetzten Techniken nicht brandneu – MLA wurde bereits im Sommer 2024 im Zuge von DeepSeek v2 vorgestellt – doch deren Kombination und Verfeinerung hat die Grundlage für ein effizienteres und leistungsfähigeres Basismodell geschaffen. Besonders wichtig ist diese solide Ausgangsbasis, da das folgende Reinforcement Learning (RL) auf einem bereits starken Modell fungiert und so die Effektivität des Lernprozesses erhöht. Die Trainingsphase von DeepSeek-R1 gliedert sich im Wesentlichen in zwei Abschnitte: Das Pretraining, welches die Vorstufe und das Fundament bildet, und das darauf aufbauende Reinforcement Learning, mit dem der Reasoning-Aspekt des Modells konkret verbessert wird. Das Pretraining wurde durch das DeepSeek v3-Modell realisiert, das auf einem Cluster von 2048 Nvidia H800 GPUs trainiert wurde. DeepSeek dokumentierte bemerkenswert detailliert, wie sie trotz der enormen Datenmengen zielgerichtet und effizient vorgingen.
Dabei kamen Mixed Precision Trainingsmethoden mit FP8 zum Einsatz, um Rechenzeit und Ressourcen zu optimieren. Die vorliegende Schätzung geht von etwa 14,8 Billionen Tokens aus, die im Pretraining verarbeitet wurden, was bei etwa 3,7 Tagen Rechenzeit pro Billion Tokens auf der genannten Hardware zu einer Gesamtdauer von rund 55 Tagen führte. Die Rechenkapazität, die in FP8-Flops gemessen wird, beläuft sich dabei auf circa 3e24 FLOPs. Zu beachten ist hierbei, dass das Modell nicht die volle theoretische Rechenleistung der GPUs ausschöpfte, sondern eine Modell FLOP Utilization (MFU) von etwa 23% erzielt wurde. Trotz dieser vergleichsweise niedrigen Auslastung erstaunt die Effizienz des Modells, vor allem vor dem Hintergrund, dass der vergleichbare Llama 3 70B mit deutlich mehr Rechenaufwand schlechtere Benchmark-Ergebnisse erzielt.
Ein Grund für diese scheinbare Diskrepanz liegt in den algorithmischen Fortschritten, die DeepSeek in die Architektur und das Training von v3 einfließen ließ. Insbesondere die MoE-Struktur brachte zwar Herausforderungen mit sich – etwa aufwändige Kommunikation zwischen den Experten über das Netzwerk – aber auch signifikante Vorteile hinsichtlich der Effizienz. DeepSeek begegnete den erwartungsgemäß hohen Kommunikationsanforderungen, die durch die Verteilung der Experten auf verschiedene GPUs entstehen, mit einer intelligenten Optimierung der Datenflüsse. So wurde eine Überlappung von Kommunikation und Berechnung implementiert, und Experten mit höherer Aktivierungswahrscheinlichkeit wurden näher im Netzwerk zusammengebracht, um latenzärmere Verbindungen wie NVLink zu nutzen. Dies trug maßgeblich dazu bei, die Trainingszeit trotz der Komplexität in einem handhabbaren Rahmen zu halten.
Nach dem erfolgreichen Pretraining begann die Phase des Reinforcement Learnings, welche DeepSeek-R1 den entscheidenden Reasoning-Schub verlieh. Die Trainingsmethode ist als Group-Relative Policy Optimization (GRPO) bekannt, eine effizientere Alternative zum populären PPO-Algorithmus. Das Verfahren basiert darauf, dass das Modell für einen gegebenen Input verschiedene Antwortmöglichkeiten generiert, die anschließend eine Bewertung – teilweise durch andere Modelle oder regelbasierte Tests – erhalten. Darauf basierend wird der Algorithmus so angepasst, dass zukünftig bevorzugt hochwertige, belohnte Antworten erzeugt werden. Die Berechnung des FLOP-Aufwands für das RL-Training gestaltet sich komplex.
Neben den 37 Milliarden aktiven Parametern spielen die durchschnittlichen Antwortlängen von etwa 4000 Tokens sowie die Batch- und Generierungsgrößen eine Rolle. Insgesamt wird der Aufwand auf rund 6,1e23 FLOPs geschätzt, was etwa einem Millionen-Dollar-Betrag an GPU-Kosten entspricht, wenn die Auslastung mit der des Pretrainings vergleichbar ist. Dieser Wert ist damit erheblich geringer als die Kosten des Pretrainings und spiegelt die Effektivität der optimierten Trainingsmethode wider. Der Reinforcement Learning Prozess verlief dabei keineswegs in einem einzigen Schritt. Nach dem initialen RL-Loop, der das sogenannte R1-Zero Modell erzeugte, folgten weitere Feinschleifen.
DeepSeek erstellte einen sogenannten Cold-Start-Datensatz, um das Modell auf menschlich lesbare Outputs zu stabilisieren, bevor eine zweite RL-Phase das endgültige DeepSeek-R1 formte. Zusätzlich erfolgte eine Phase des supervised fine-tunings mit einer vergleichsweise geringen Menge an speziellen Reasoning-Beispielen, was zeigt, wie wenig Daten nötig sind, um ein starkes Reasoning-Verhalten aus einem guten Basismodell heraus zu fördern. Die finale Schätzung der Trainingskosten summiert sich somit auf etwa 6 Millionen US-Dollar: rund 5 Millionen für das Pretraining von v3 und etwa eine Million für die RL-Phasen, was für ein Modell dieser Größenordnung als eher moderat gilt. Interessanterweise zeigt sich damit, dass die Debatte über angebliche Unterberichterstattung der Trainingskosten wenig Substanz hat und dass DeepSeek technisch gesehen realistischen Aufwand betrieben hat, um ihr Modell auf Spitzenniveau zu bringen. Im Vergleich zur Konkurrenz, insbesondere zu OpenAIs o1-Modell, positioniert sich DeepSeek-R1 als wirklich konkurrenzfähiger Player.
Leistungsmäßig sind die Modelle etwa gleichauf, wobei DeepSeek-R1 in etwa halb so viele Benchmarks verliert, wie es gewinnt. Die eigentliche Überraschung liegt jedoch in der Preiskalkulation: DeepSeek bietet R1 für etwa 2,2 US-Dollar pro Million Tokens an, während OpenAI für o1 rund 60 US-Dollar verlangt. Diese enorme Preisvariante macht DeepSeek-R1 zu einer äußerst attraktiven Option auf dem Markt – wenn auch die günstigeren Preise vermutlich eher auf geringere Gewinnmargen und schlankerer Preispolitik basieren als auf einer intrinsischen Effizienzsteigerung des Modells. Diese günstige Preisgestaltung dürfte nicht nur Auswirkungen auf die Nutzung von DeepSeek-R1 selbst haben, sondern könnte auch einen Druck auf andere führende KI-Anbieter erzeugen. Vor allem chinesische Anbieter wie DeepSeek positionieren sich als kosteneffiziente Alternativen, was die internationale Wettbewerbslandschaft nachhaltig beeinflussen könnte.