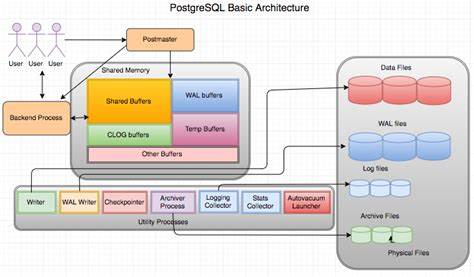
Die Entwicklung moderner Datenbanktechnologien stellt Entwickler vor immer komplexere Herausforderungen, insbesondere wenn es um die Integration von Volltextsuche in relationale Systeme wie PostgreSQL geht. PostgreSQL gilt als eine der fortschrittlichsten Open-Source-Datenbanken mit einem umfangreichen Ökosystem von Erweiterungen. Eine bedeutende Innovation in diesem Bereich ist das neue Block-Storage-Layout, das speziell für Volltextsuche konzipiert wurde und maßgeblich von ParadeDB durch die Migration der pg_search Erweiterung vorangetrieben wurde. PostgreSQL verwendet sein eigenes Blockspeicher-API (Application Programming Interface), das den Kern der Datenspeicherung für Tabellen und Indexe bildet. Die fundamentale Einheit dieses Speichermodells ist der Block, der standardmäßig eine Größe von 8192 Bytes hat.
Bis vor kurzem basierte die Volltextsuch-Erweiterung pg_search auf einem dateibasierten Speichermodell außerhalb von PostgreSQLs Blockspeicher. Dies bedeutete, dass pg_search selbständig Dateien erzeugte und direkt von der Festplatte lesen konnte, was zwar praktikabel, jedoch vor allem hinsichtlich Integration und Performance Nachteile mit sich brachte. Mit der Migration von pg_search in das Blockspeichersystem von PostgreSQL ergeben sich zahlreiche Vorteile und neue Möglichkeiten. Ein entscheidender Faktor ist die vollständige Integration in den Write-Ahead-Log (WAL)-Mechanismus von PostgreSQL. Dadurch ist es möglich, physische Replikationen des Indexes durchzuführen, was eine hohe Verfügbarkeit und Ausfallsicherheit gewährleistet.
Zudem wird Crash Recovery unterstützt und das Multi-Version Concurrency Control (MVCC) vollständig implementiert, wodurch parallele Datenbankzugriffe sicher und konsistent abgewickelt werden können. Darüber hinaus profitiert pg_search von der direkten Anbindung an den Buffer Cache von PostgreSQL, was sowohl die Index-Erstellung als auch die Schreibdurchsatzrate signifikant verbessert. Die intelligente Nutzung des Buffer Caches reduziert die Anzahl der notwendigen Festplattenzugriffe erheblich und beschleunigt somit alle Operationen, die auf die Volltextsuche zugreifen. Die Herausforderung bei der Migration liegt unter anderem darin, die strengen Anforderungen der Blockgröße und der parallelen Zugriffsmodelle zu erfüllen. Da ein Block nur 8 Kilobyte umfasst, können komplexe oder große Datenstrukturen nicht in einem Block gespeichert werden.
Eine Lösung wurde in Form einer verketteten Liste von Blöcken implementiert, die es ermöglicht, große Segmente effizient über mehrere Blöcke zu verteilen. Die Verkettung wird mithilfe eines eigens reservierten Metadaten-Bereichs in jedem Block realisiert, der die Adresse des nächsten Blocks speichert. Das zugrunde liegende Suchsystem von pg_search basiert auf Tantivy, einer in Rust geschriebenen Suchbibliothek, die von Apache Lucene inspiriert ist. Tantivy organisiert seine Daten in sogenannte Segmente, die jeweils einen Teilbestand der Dokumente enthalten. Jedes Segment wiederum besteht aus mehreren Dateien, die verschiedene Aspekte der Suche abdecken, darunter Postingslisten, Positionsdaten, Term-Informationen und andere Metadaten.
Die ursprüngliche Speicherung bei Tantivy erfolgte dateibasiert, was jedoch bei der Integration in PostgreSQLs Blockspeicher auf Herausforderungen stößt. So ist die Speicherung und Verwaltung der vielen kleinen Dateien komplexer geworden und muss an das Blockspeichermodell angepasst werden. Die Transformation von Dateien in Blöcke erforderte eine neue Struktur zur Serialisierung, womit Speicherbereiche atomar innerhalb der Blockgrenzen verwaltet werden können. Ein weiteres technisches Problem war die Annahme von Tantivy, dass große Dateien durch Memory Mapping (mmap) direkt adressierbar sind. Block Storage unterstützt diese Technik nicht, weil jeder Zugriff auf einen Block seinen eigenen separaten Speicherpuffer bereitstellt.
Um hier die Performance nicht zu verlieren, wurde eine verzögerte und speichereffiziente Zugriffsmethode entwickelt: Bytes werden nur bei Bedarf gelesen und zwischengespeichert, sodass mehrfaches Nachladen vermieden wird. Im täglichen Betrieb von Datenbanken mit hoher Schreiblast können sich zahlreiche neue Segmente aneinanderreihen, da jede Änderung im Index zur Entstehung neuer Segmente führt. Das kann zur Segmentflut führen, die Performance leidet, weil Suchanfragen über viele Segmente laufen müssen. Um diese Explosion zu verhindern, wurde eine sogenannte merge_on_insert Funktion eingeführt. Sie identifiziert nach jeder Einfügeoperation Merge-Potenziale, bei denen kleinere Segmente zusammengefügt werden, bevor die Anzahl unkontrolliert anwächst.
Diese Merge-Operationen müssen mit größter Sorgfalt ausgeführt werden, denn gleichzeitige Merges können zu Dateninkonsistenzen führen. Daher wird sichergestellt, dass immer nur ein Merge-Prozess aktiv ist. Dafür schreibt jeder Merge-Prozess seine Transaktions-ID atomar in einen Metadatenblock. Nachfolgende Prozesse prüfen diese ID und fahren nur fort, wenn die Änderungen der letzten Transaktion sichtbar sind, was auf dem MVCC-Prinzip von PostgreSQL basiert. Der Abbau der traditionellen Lock-Mechanismen von Tantivy ist ein weiterer Fortschritt dieser Integration.
Während Tantivy bislang auf dateibasierte Lockdateien setzte, übernimmt PostgreSQLs Buffer-Level-Locking nun diese Aufgabe. Das entlastet das System von zusätzlichen Synchronisationsproblemen und nutzt die bewährten Mechanismen des Datenbanksystems. Die Umstellung von einem externen dateibasierten Indexsystem hin zur eigentlichen Blockspeicherarchitektur von PostgreSQL umfasst eine erhebliche Reduktion der Systemkomplexität und der Fehleranfälligkeit. Dennoch erforderte dies eine tiefgreifende Auseinandersetzung mit den Eigenheiten der MVCC, des WAL und des Parallelitätsmodells von PostgreSQL. Zudem eröffnet diese Integration neue Perspektiven für analytische Workloads, die über die reine Volltextsuche hinausgehen.
ParadeDB erforscht bereits weitere Optimierungen für facettierte Suchen, Aggregationen und Analysen innerhalb der neuen Blockspeicherarchitektur. Die Entscheidung, Block Storage zu verwenden, ist eine strategische Antwort auf die Limitationen von dateibasierten Indexen. Sie verspricht nicht nur eine engere Verzahnung mit dem Host-Datenbanksystem, sondern auch nachhaltige Leistungsverbesserungen und eine robustere Fehlerabsicherung. Insgesamt stellt die neue Block-Storage-Architektur für Postgres einen bedeutenden Schritt nach vorne dar. Unternehmen wie Alibaba setzen bereits erfolgreich auf ParadeDB und pg_search, um komplexe Volltextsuchanforderungen im Data Warehouse zu bewältigen.
Diese Innovation zeigt, wie Open-Source-Datenbanken durch Erweiterungen und kreative Ingenieursarbeit maßgeblich verbessert werden können, ohne die Stabilität und die Integrität des Kernsystems zu gefährden. ParadeDB und seine Entwicklergemeinde arbeiten kontinuierlich daran, das Design weiter zu verfeinern. Zukünftige Beiträge und Updates versprechen tiefere Einblicke in die Umsetzung von MVCC-Sicherheit in Update-intensiven Umgebungen sowie die Optimierung für analytische Abfragen. Für Entwickler und Datenbankadministratoren bedeutet die Umstellung auf das neue Blockspeicher-Layout langfristig ein Plus an Geschwindigkeit, Stabilität und einfacher Wartbarkeit. Durch die Vorteile der nativen PostgreSQL-Infrastruktur lassen sich Fulltext-Suchindizes nun leistungsfähiger und sicherer einsetzen – ein entscheidender Vorteil in datengetriebenen Geschäftsprozessen, in denen schnelle und präzise Suche unverzichtbar ist.
Wer sich intensiver mit der Materie auseinandersetzen möchte, findet auf GitHub detaillierte Quellcode-Informationen, vernetzt sich in der Community und profitiert von einem regen Austausch zwischen Datenbank-Ingenieuren, Such-Experten und Postgres-Enthusiasten. Die Kombination aus Forschung, Community-Support und professioneller Implementierung macht den Unterschied für moderne Enterprise-Anwendungen, die den vollen Nutzen aus ihren Daten ziehen wollen.






![Gumroad CEO's playbook to 40x his team's productivity with v0, Cursor, and Devin [video]](/images/B74510CD-07B7-4638-B201-91E4F1B21479)
