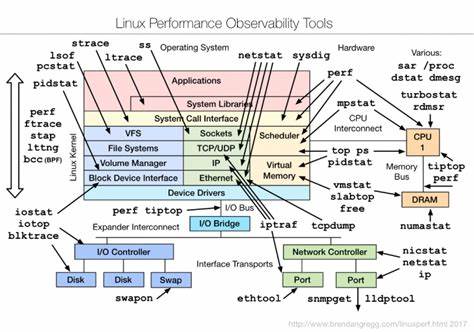
Die ständige Überwachung und Optimierung der Systemleistung ist für Administratoren und IT-Verantwortliche essenziell, um einen reibungslosen Betrieb von Linux-Servern sicherzustellen. Gerade in komplexen Umgebungen können Engpässe oder Fehlerquellen weitreichende Folgen haben. Die USE-Methode, die für Utilization (Auslastung), Saturation (Sättigung) und Errors (Fehler) steht, ist ein bewährtes Framework, das eine ganzheitliche Analyse sämtlicher Ressourcen ermöglicht und somit bei der gezielten Fehlersuche und Performance-Optimierung unterstützt. Im Kern verfolgt die Methode den Anspruch, sämtliche entscheidenden Komponenten eines Systems durch diese drei Faktoren zu betrachten, um sowohl offensichtliche als auch versteckte Probleme zu identifizieren. Dabei erstreckt sich die Anwendung der Methode über physische Ressourcen wie CPU, Arbeitsspeicher, Netzwerkschnittstellen und Speichergeräte bis hin zu softwareseitigen Ressourcen wie Kernel- und User-Mutexen, Task-Kapazitäten und Dateideskriptoren.
Die detaillierte Prüfung dieser Komponenten kann durch verschiedene Kommandozeilen-Tools und Analysewerkzeuge unterstützt werden, die in Linux bereits integriert oder frei verfügbar sind. Ein Schwerpunkt liegt dabei auf der Messung der Auslastung, um zu erkennen, wie intensiv eine Ressource aktuell verwendet wird. Die Sättigung greift tiefer und macht sichtbar, inwieweit Warteschlangen, Verzögerungen oder Überlastungen die Leistung beeinträchtigen. Fehler zeigen schließlich auf, ob es besondere Ereignisse oder Zustände gibt, die auf Fehlfunktionen oder Hardwareprobleme hinweisen. Bei der CPU-Analyse werden beispielsweise Werkzeuge wie vmstat, sar oder mpstat herangezogen, um den Anteil von Benutzer-, System- und Wartezeiten zu erfassen.
Ebenso ist die Messung der Anzahl der wartenden Prozesse ein wichtiger Indikator für Sättigungsprobleme, die auf zu wenig verfügbare CPU-Ressourcen hinweisen. Fehlerereignisse auf der CPU lassen sich mit Hilfe von Linux Performance Events und Hardware Performance Counters diagnostizieren, wobei diese detaillierte Informationen über spezifische Prozessor-events liefern können. Die Speicheranalyse umfasst sowohl die Betrachtung von physischem Hauptspeicher als auch von virtuellem Speicher und Swap. Tools wie free, vmstat oder sar helfen dabei, die Menge an verfügbarem und verwendetem Speicher zu überwachen, während die Swap-Nutzung und Speicher-Tauschvorgänge Hinweise auf Überlastung oder unzureichende Kapazitäten geben können. Fehlerhafte Speicherzugriffe äußern sich häufig in Kernel-Meldungen, die mit dmesg identifiziert werden können.
Netzwerkschnittstellen spielen in modernen Linux-Server-Umgebungen eine zentrale Rolle. Deren Überwachung erfolgt mit Befehlen wie sar, ip, ifconfig oder nicstat, wobei hier nicht nur Datentransferraten, sondern auch Fehler und Paketverluste beachtet werden sollten. Diese können sowohl auf physikalische Probleme der Netzwerkkarte als auch auf Überlastungen oder Fehler im Protokollstapel hindeuten. Ein kritischer Punkt ist hier, dass verlorene Pakete sowohl als Sättigungs- als auch als Fehlerindikatoren gewertet werden sollten. Die Speichergeräte und deren Controller sind häufig Flaschenhälse bei I/O-intensiven Anwendungen.
Das Monitoring mit iostat, smartctl oder irqs ermöglicht eine genaue Beurteilung der Auslastung und der Warteschlangenlängen. Wiederkehrende Fehlermeldungen oder eine hohe durchschnittliche Wartezeit können Indikatoren für physische Defekte oder ineffiziente Konfigurationen sein. Die Errkennung von Kapazitätsengpässen bei Datenträgern erfolgt unter anderem durch Überwachung der freien Speicherkapazität mittels df sowie des Swap-Speichers. Überfüllte Dateisysteme führen in der Regel zu Systemfehlern, die in Logdateien oder mit Hilfsmitteln wie strace nachvollziehbar sind. Neben den physischen Komponenten sind auch softwareseitige Ressourcen entscheidend für die Systemperformance.
So werden Kernel-Mutexe durch spezielle Kernel-Konfigurationen mit Lock-Statistikfunktionen überwacht und geben Auskunft über Wartezeiten und Contention, also Konflikte beim gleichzeitigen Zugriff mehrerer Threads auf eine Ressource. User-Level-Mutexe können mit Valgrind oder dynamischen Tracing-Tools analysiert werden, um Engpässe bei der Synchronisation oder Fehler wie Deadlocks aufzudecken. Die Kapazität von Tasks und Threads ist eine weitere Messgröße, die durch Tools wie top oder htop sichtbar gemacht wird. Eine Überschreitung der maximal erlaubten Threads führt zu Blockaden oder Fehlermeldungen beim Erstellen neuer Prozesse. Das Dateideskriptor-Limit, also wie viele Dateien oder Sockets ein Prozess oder das gesamte System gleichzeitig öffnen kann, ist ebenfalls eine wichtige Kenngröße.
Die Überschreitung dieser Grenzen zeigt sich meist durch Fehlermeldungen mit EMFILE und kann zu unerwartetem Verhalten führen. Die praktische Anwendung der USE-Methode zeichnet sich durch ihre Systematik aus: Indem zunächst die grundlegenden Leistungskennwerte gesammelt und interpretiert werden, lassen sich gezielte Follow-up-Analysen durchführen. Wird etwa eine hohe CPU-Auslastung registriert, empfiehlt sich die genaue Betrachtung der laufenden Prozesse und deren Verteilung auf die verfügbaren Kerne. Liegt eine außergewöhnlich lange Warteschlange an einer I/O-Ressource vor, kann dies die Ursache unterschiedlicher Performance-Einbrüche erklären und muss mit geeigneten Tools vertieft untersucht werden. Besonders wertvoll ist die USE-Methode bei der Fehlersuche unter hoher Last, da sie eine konsistente Sicht auf alle beteiligten Systemressourcen bietet und so schnell die problematischsten Bereiche identifiziert.
Darüber hinaus unterstützt sie die faire Priorisierung von Optimierungsmaßnahmen, da die tatsächliche Sättigung und Fehlerhäufigkeit meist bessere Hinweise liefern als bloße Auslastungswerte. Die Linux-Community verfügt über eine breite Palette an Tools, die im Rahmen der USE-Analyse eingesetzt werden können. Klassiker wie vmstat, iostat, sar, top und htop sind leicht zugänglich und liefern sofort verwertbare Daten. Fortgeschrittene Techniken nutzen die Möglichkeiten von perf, SystemTap oder DTrace, um tiefgreifende Einblicke in Kernel- und Anwendungsebene zu gewinnen. Diese Werkzeuge erlauben die dynamische Überwachung und das Tracing von Systemereignissen und helfen so, auch komplexe und seltene Probleme zu identifizieren.
Ein weiterer Vorteil der USE-Methode ist ihre Anpassungsfähigkeit an verschiedene Linux-Distributionen und Systemumgebungen. Sowohl in klassischen physischen Serverlandschaften als auch in virtualisierten oder Container-basierten Umgebungen lässt sich der Ansatz anwenden, um eine valide und vergleichbare Bewertung der Systemgesundheit und Performance zu erhalten. Dabei sollten allerdings die Eigenarten einzelner Architekturen und Technologien berücksichtigt werden, etwa Unterschiede bei der CPU-Last-Darstellung in virtualisierten Umgebungen. Abschließend lässt sich sagen, dass die USE-Methode ein unverzichtbares Werkzeug für eine strukturierte und umfassende Linux-Systemanalyse ist. Durch die Fokussierung auf Auslastung, Sättigung und Fehler vermeidet sie oberflächliche Mutmaßungen und führt direkt zu den Kernursachen von Performance-Problemen.
Eine regelmäßige Anwendung des Checklists erleichtert zudem die Prävention von Engpässen und trägt zur Stabilität und Effizienz im Betrieb bei. Für Administratoren bedeutet dies mehr Kontrolle, besseres Verständnis der Systemdynamik und letztlich eine solide Basis für fundierte Optimierungs- und Wartungsentscheidungen.