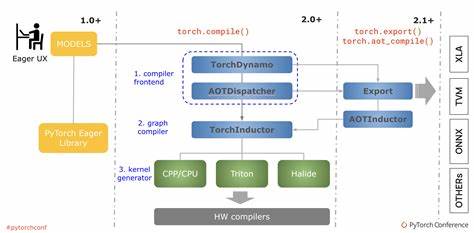
PyTorch hat sich in den letzten Jahren zu einem der führenden Frameworks für maschinelles Lernen und Deep Learning entwickelt. Ein wichtiger Bestandteil seiner Leistungsfähigkeit liegt in den sogenannten Torch Backends. Diese Backends steuern das Verhalten und die Leistung verschiedener Hardware- und Softwarekomponenten, die PyTorch beim Rechnen nutzt. Wer die Torch Backends versteht, kann nicht nur die Performance seiner Modelle verbessern, sondern auch gezielter auf unterschiedliche Hardwaresysteme optimieren. Torch Backends sind modulare Softwarekomponenten, die verschiedene Hardware-Architekturen wie CPU, CUDA-fähige GPUs, Metal Performance Shaders (MPS) von Apple und andere beschleunigen.
Sie ermöglichen es PyTorch, auf unterschiedliche Plattformen zuzugreifen und dabei optimale Rechenleistung zu erzielen. Gleichzeitig sind diese Backends anpassbar und steuerbar, sodass Nutzer auf den individuellen Bedarf reagieren können. Der wichtigste und meistgenutzte Backend-Typ ist der CUDA-Backend. NVIDIA CUDA ist die parallele Rechenplattform, die GPUs programmierbar macht und das maschinelle Lernen immens beschleunigt. PyTorch überprüft über torch.
backends.cuda, ob CUDA in der jeweiligen Umgebung verfügbar ist und steuert Features wie TensorFloat-32 (TF32), reduzierte Präzision bei fp16 oder bf16 zur effizienteren Matrixmultiplikation. Nutzer können beispielsweise die Verwendung von TF32 Core-Multiplikationen aktivieren oder deaktivieren, was sich maßgeblich auf die Geschwindigkeit bei gleichbleibender Genauigkeit auswirken kann. Neben der Aktivierung bietet das CUDA-Backend auch Funktionen, mit denen die genutzten Bibliotheken für lineare Algebra, BLAS-Operationen oder Flash Attention gewählt werden können. Durch Overrides wie torch.
backends.cuda.preferred_blas_library() können Entwickler zwischen verschiedenen CUDA-Bibliotheken wie cuBLAS, cuBLASLt oder auch speziellen ROCm-Bibliotheken wechseln, um für ihr Modell die beste Performance zu erzielen. Diese Flexibilität ist besonders für High-Performance-Computing oder spezialisierte Forschungsaufgaben interessant. Ein erweitertes Feature sind die CUDA-basierten Scaled Dot Product Attention (SDPA)-Backends.
Attention-Mechanismen sind heutzutage unverzichtbar bei Transformer-Modellen. PyTorch bietet verschiedene Backends an, um die Berechnung der Attention möglichst effizient zu gestalten – etwa FlashAttention, Memory Efficient SDPA oder cuDNN-basierte Varianten. Über eine Reihe von torch.backends.cuda Funktionen können Nutzer überprüfen, welches der Attention-Backends verfügbar und nutzbar ist.
Mit den entsprechenden Einstellungen lässt sich die optimale Variante für das jeweilige Projekt auswählen, um Rechenzeit und Speicherverbrauch zu minimieren. Ein weiterer bedeutender Backend-Bereich sind die CPU-basierten Optionen. Viele Aufgaben laufen zwar primär auf GPUs, aber CPU-Berechnungen bleiben unverzichtbar, insbesondere für kleinere Modelle oder Vorverarbeitungsschritte. Das Modul torch.backends.
cpu unterstützt Funktionalitäten wie das Auslesen der CPU-Fähigkeiten (etwa AVX2, AVX512, oder SVE256) und kann so programmatisch entscheiden, welche Optimierungen sinnvoll sind. Dieses Vorgehen hilft nicht nur bei der Performance-Steigerung, sondern auch bei der plattformunabhängigen Entwicklung. Darüber hinaus steuert PyTorch Backends für verschiedene Bibliotheken, die auf CPUs agieren. Dazu zählen beispielsweise MKL und MKLDNN von Intel, die besonders für lineare Algebra und neuronale Netze optimierte Implementierungen bereitstellen. Nutzer können über torch.
backends.mkl oder torch.backends.mkldnn Einfluss auf die Verfügbarkeit und sogar das Verbose-Level der Bibliotheken nehmen, um beim Profiling oder Debuggen gezielte Einblicke in die Performance zu erhalten. Für Mac-Nutzer ist das Backend torch.
backends.mps interessant, welches den Metal Performance Shader als Hardwarebeschleunigung nutzt. Dies ermöglicht, dass PyTorch auf Apple Silicon Chips (wie M1 oder M2) beschleunigt laufen kann, obwohl keine NVIDIA-GPU vorhanden ist. Die Verfügbarkeit und der Build-Status dieses Backends lassen sich testen, um sicherzustellen, dass die eigene Umgebung für Hardware-beschleunigtes Training richtig aufgesetzt ist. Ein besonders bemerkenswertes Feature der Torch Backends ist die Integration von Experimental-Features wie opt_einsum.
Dieses Backend erlaubt die Optimierung von sogenannten Einstein Summationsoperationen, die häufig in komplexen Matrizenberechnungen auftauchen. Ist die Python-Bibliothek opt-einsum installiert, kann PyTorch automatisch optimalere Rechenpfade wählen, was die Effizienz bei großen Tensoroperationen deutlich verbessert. Über torch.backends.opt_einsum lassen sich Einstellungen vornehmen, um Strategien zur Pfadsuche wie “auto”, “greedy” oder “optimal” zu definieren.
Neben Performance und Flexibilität sind Torch Backends auch ein Schlüssel zur deterministischen und reproduzierbaren Modellberechnung. Beispielsweise erlaubt torch.backends.cudnn Einstellungen wie deterministisch=true, um sicherzustellen, dass bei der Verwendung von cuDNN immer dieselben Algorithmen genutzt werden und damit gleiche Ergebnisse erzeugt werden. Das ist insbesondere für die Forschung und das Debugging unverzichtbar, da neuronale Netze sonst von nicht-deterministischen Operationen beeinflusst werden könnten.
Ein weiteres spannendes Thema im Bereich Torch Backends ist die Nutzung von Threading und paralleler Ausführung über OpenMP. Das Backend torch.backends.openmp prüft, ob die PyTorch-Installation OpenMP unterstützt, was Einfluss auf die Thread-Verwaltung bei parallelen CPU-Berechnungen hat. Durch eine optimale Konfiguration können PyTorch-Anwendungen so auch auf CPUs skaliert werden, die viele Kerne besitzen, was gerade in Server-Umgebungen oder auf Hochleistungs-Workstations effektiv ist.
Die Verantwortung der Torch Backends geht noch tiefer. Sie bilden eine Zwischenschicht zwischen PyTorchs abstrakten Tensor-Funktionen und den tatsächlichen Hardware-Ressourcen. Durch modulare und erweiterbare Architektur ermöglicht PyTorch eine schnelle Anpassung an neue Hardware und Technologien ohne umfangreiche Änderungen am Nutzer-Code. So ist die Migration auf neue GPUs oder spezialisierte Recheneinheiten minimal-invasiv. Die Backend-Module werden kontinuierlich weiterentwickelt und oft mit experimentellen Funktionen ausgestattet, die parallel im Rahmen von Beta-Versionen erprobt werden.
Dazu zählen etwa Fortschritte bei der FlashAttention-Technologie oder gedächtniseffiziente Aufmerksamkeitsmechanismen, die besonders bei der Verarbeitung großer Sequenzen leistungsfähiger Transformer-Modelle relevant sind. Diese Entwicklungen geben PyTorch-Entwicklern in Echtzeit den Zugang zu aktuellsten Forschungsergebnissen und Performance-Verbesserungen. Als Entwickler ist es ratsam, sich mit den Torch Backends auseinanderzusetzen, wenn Performance, Skalierbarkeit oder die Nutzung spezieller Hardware eine wichtige Rolle spielen. Das Verständnis der Backend-spezifischen Funktionen ermöglicht nicht nur das Feinjustieren von Parametern, sondern auch das gezielte Aktivieren oder Deaktivieren bestimmter Optimierungen und Sicherheitsmaßnahmen. Abschließend kann gesagt werden, dass Torch Backends der Motor sind, der PyTorch seine enorme Flexibilität und Leistungsfähigkeit verleiht.
Sie sorgen dafür, dass das Framework auf verschiedensten Plattformen gleichermaßen effizient läuft und erlauben es Entwicklern, das Maximum aus ihrer Hardware herauszuholen. Von CUDA-GPUs über CPUs bis hin zu Apple Silicon beschleunigten Geräten oder spezialisierten Bibliotheken und neuen Entwicklungen – Torch Backends sind der Schlüssel zu moderner, skalierbarer KI-Entwicklung mit PyTorch.