In der schnelllebigen Welt der künstlichen Intelligenz ist die Fähigkeit von Modellen, komplexe Denkaufgaben effizient zu bewältigen, von zentraler Bedeutung. Hier setzt die Llama-Nemotron-Modellfamilie an, eine wegweisende Entwicklung, die sowohl durch ihr innovatives Design als auch durch ihre beeindruckende Leistung überzeugt. Die Llama-Nemotron-Serie bietet eine Kombination aus herausragender Denkfähigkeit und technischer Effizienz, die vor allem für Anwendungen in Forschung, Industrie und Unternehmenslösungen interessant ist. Die Modelle der Llama-Nemotron-Reihe bestehen aus drei Varianten, die unterschiedliche Größen und Einsatzprofile abdecken: Nano mit 8 Milliarden Parametern, Super mit 49 Milliarden und Ultra mit satten 253 Milliarden Parametern. Diese gestaffelte Architektur ermöglicht es Anwendern, je nach Anforderung und Ressourcen die optimale Balance zwischen Leistung und Effizienz zu wählen.
Besonders hervorzuheben ist, dass diese Modelle trotz ihrer hohen Kapazitäten speziell für den effizienten Einsatz konzipiert sind und somit eine bemerkenswerte Inferenzgeschwindigkeit bei vergleichsweise geringem Speicherverbrauch bieten. Ein wesentlicher Höhepunkt der Llama-Nemotron-Modelle ist ihr Fokus auf herausragende reasoning- beziehungsweise Denkfähigkeiten, die in vielen KI-Anwendungen essenziell sind. Aufgabe dieser Modelle ist es nicht nur, Antworten zu generieren, sondern auch komplexe Schlussfolgerungen zu ziehen, Probleme zu analysieren und folgerichtige Entscheidungen zu treffen. Diese Fähigkeit wird oft als kritisches Element für den nächsten Entwicklungsschritt in der Künstlichen Intelligenz betrachtet, da sie weit über reine Sprachverarbeitung hinausgeht. Die Erfolge der Llama-Nemotron-Serie beruhen unter anderem auf fortschrittlichen Trainingsmethoden, die eine Kombination aus neuraler Architektur-Suche, Wissensdistillation und weiterem Training nach der Grundausbildung beinhalten.
Dabei wird auf den bewährten Llama 3 Modellen aufgebaut, die durch gezielte Optimierungen signifikante Effizienzgewinne erreichen. Die Wissensdistillation sorgt dafür, dass die kleineren Modelle dennoch das Wissen und die Fähigkeiten der größeren Varianten auf effiziente Weise erhalten, wodurch es möglich wird, Rechenressourcen zu sparen, ohne die Leistung zu stark einzubüßen. Nach der Grundausbildung durchlaufen die Llama-Nemotron-Modelle eine spezielle Phase des post-trainings, welche auf das Reasoning optimiert ist. Diese Phase beinhaltet überwachte Feinabstimmung und ein groß angelegtes Reinforcement-Learning-Verfahren. Durch diese Kombination werden die Modelle nicht nur genauer, sondern auch flexibler und anpassungsfähiger bei komplexen Aufgabenstellungen.
So können sie besser auf unterschiedliche Anforderungen und Fragestellungen reagieren, was für praktische Einsatzzwecke von enormem Vorteil ist. Ein weiterer innovativer Aspekt ist die Einführung eines dynamischen Reasoning-Toggles, der es Nutzern erlaubt, während der Inferenz zwischen einem Standard-Chat-Modus und einem Reasoning-Modus zu wechseln. Dieses Feature eröffnet zahlreiche Möglichkeiten: Es ermöglicht einerseits schnelle und ressourcenschonende Standardanfragen, andererseits eine intensive und detaillierte Problemlösung, wenn diese tatsächlich benötigt wird. Damit wird sowohl die Benutzererfahrung als auch die Effizienz in produktiven Umgebungen optimiert. Llama-Nemotron besticht auch durch seine Unternehmensfreundlichkeit, da die Modelle unter der NVIDIA Open Model License veröffentlicht wurden, die eine breite kommerzielle Nutzung erlaubt.
Somit können Firmen und Entwickler die Modelle flexibel in vielfältigen Anwendungen einsetzen, was ihre Verbreitung und Weiterentwicklung nachhaltig fördern dürfte. Der offene Zugang zu den Modellen, den Trainingsdatensätzen und den zugehörigen Codebasen wie NeMo, NeMo-Aligner und Megatron-LM zeigt das Engagement der Entwicklergemeinschaft hinter Llama-Nemotron, offene Forschung und Innovation zu unterstützen. Die Effizienz der Llama-Nemotron-Modelle äußert sich insbesondere in der hohen Anzahl von Anfragen, die pro Sekunde verarbeitet werden können. Diese Skalierbarkeit und Geschwindigkeit sind ausschlaggebend, wenn KI-Modelle in Echtzeit oder bei großen Datenmengen agieren müssen. Darüber hinaus punktet die Familie durch einen reduzierten Speicherbedarf, was auf modernen Optimierungstechniken in der Architektur und den Trainingsverfahren basiert.
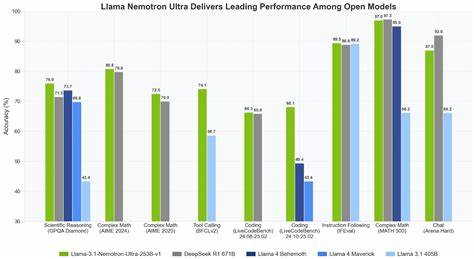
Dies macht die Modelle auch für den Einsatz in ressourcenlimitierten Umgebungen interessant, beispielsweise in mobilen Anwendungen oder eingebetteten Systemen. Im Vergleich zu anderen hochentwickelten Reasoning-Modellen wie DeepSeek-R1 zeigt Llama-Nemotron eine wettbewerbsfähige Leistungsfähigkeit bei gleichzeitig höherer Inferenzdurchsatzrate und besserer Speichereffizienz. Das trägt dazu bei, dass die Modelle in einer Vielzahl von wissenschaftlichen und industriellen Kontexten erfolgreich eingesetzt werden können, etwa in der Wissensverarbeitung, automatisierten Entscheidungsfindung, dem technischen Support oder in der Forschung selbst. Die breite Beteiligung zahlreicher Forschungsinstitute und Experten im Entwicklungsteam von Llama-Nemotron unterstreicht die interdisziplinäre Ausrichtung und den hohen Anspruch der Modellreihe. Die Integration modernster Verfahren im maschinellen Lernen, kombiniert mit robusten technischen Innovationen, macht diese KI-Modelle zu einem Vorreiter auf dem Gebiet der effizienten automatisierten Problemlösung.
Zusammenfassend zeigt Llama-Nemotron, wie durch gezielte methodische Innovationen und offenes Engagement eine neue Generation von KI-Reasoning-Modellen entstanden ist, die deutlich verbesserte Denkfähigkeiten mit hoher Effizienz verbindet. Diese Entwicklungen öffnen neue Türen für den praktischen Einsatz von KI in Bereichen, die bisher durch die Leistungsgrenzen und Ressourcenanforderungen vieler Modelle beschränkt waren. Die Zukunft der KI-Modellierung dürfte stark von Ansätzen wie Llama-Nemotron geprägt sein, in denen Leistungsfähigkeit, Skalierbarkeit und Benutzerfreundlichkeit gleichermaßen berücksichtigt werden. Für Unternehmen stellt sich daher die Möglichkeit, diese leistungsfähigen Modelle zu integrieren und dadurch Wettbewerbsvorteile durch bessere Analyse, Automatisierung und Entscheidungsunterstützung zu erzielen. Gleichzeitig bietet die offene Lizenzierung eine solide Basis für Forscher, um auf diesem Fundament aufzubauen und innovative neue Anwendungen zu erforschen.
Abschließend zeigt Llama-Nemotron eindrucksvoll, wie durch die Kombination aus intensiver Forschung, technischer Finesse und offenem Zugang die Entwicklung von KI-Modellen einem neuen Standard folgen kann. Dieser Standard verbindet Effizienz, Flexibilität und starke reasoning-Fähigkeiten, während er zugleich die Basis für zukünftige Innovationen bereitstellt. Wer die Entwicklung im KI-Bereich aufmerksam verfolgt, sollte Llama-Nemotron als einen der Schlüsselakteure in der Evolution intelligenter, adaptiver Systeme erkennen.