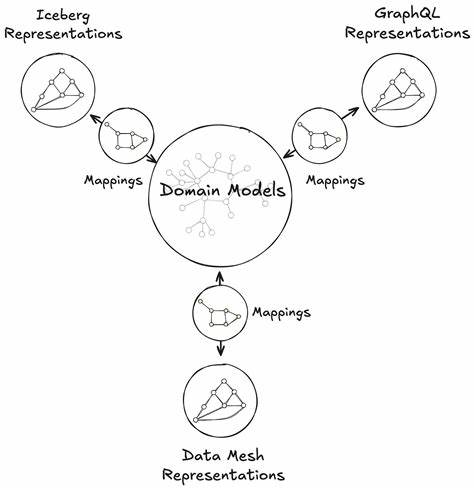
Netflix ist seit Langem führend darin, wie Streamingdienste ihre Daten verwalten, analysieren und nutzen, um ihren Nutzern personalisierte Erlebnisse zu bieten. Ein großer Teil dieses Erfolgs liegt in der Art und Weise, wie Netflix seine Datenarchitektur organisiert und kontinuierlich weiterentwickelt hat. Ein herausragendes Konzept in diesem Zusammenhang ist die sogenannte Unified Data Architecture (UDA), die Netflix implementiert hat, um die Herausforderungen einer komplexen, vielfältigen Datenlandschaft zu bewältigen. Die Kernidee hinter UDA, die auch unter dem Motto „Model Once, Represent Everywhere“ bekannt ist, beruht darauf, dass einmal definierte Datenmodelle universell verwendet werden können, um verschiedene Anwendungsfälle zu bedienen. Das bedeutet, dass Daten nicht immer wieder neu modelliert oder umgewandelt werden müssen, sondern als eine „einzige Quelle der Wahrheit“ bereitgestellt werden.
Vor dem Hintergrund der vielen verschiedenen Arten von Daten – von Content-Metadaten über Nutzerinteraktionen bis hin zu Streaming-Performance-Daten – hatte Netflix das Bedürfnis, eine Plattform zu schaffen, die flexibel genug ist, um unterschiedliche Zugriffe und Anforderungen abzudecken. Traditionelle Architekturen waren oft fragmentiert und mussten individuelle Anpassungen erfahren, was zu einem hohen Wartungsaufwand und Silos führte. Das UDA-Konzept zielt darauf ab, diese Fragmentierung zu überwinden und eine einheitliche, skalierbare Infrastruktur bereitzustellen. Ein zentraler Aspekt ist die Trennung von Datenmodellierung und Datenrepräsentation. Daten werden zunächst in einem konsistenten, wohlüberlegten Modell gehalten.
Dieses Modell bildet die Grundlage für unterschiedliche Repräsentationen, die für diverse Analyse-, Reporting- oder Machine-Learning-Aufgaben verwendet werden. Dadurch wird sichergestellt, dass alle Teams mit denselben Grundlagen arbeiten und die Gefahr von Inkonsistenzen oder Konflikten minimiert wird. Die Architektur nutzt moderne Technologien, die eine schnelle und kosteneffiziente Verarbeitung großer Datenmengen ermöglichen. Netflix setzt dabei auf Cloud-native Dienste, die elastisch skalierbar sind und sowohl Streaming- als auch Batch-Analysen unterstützen. Durch den Einsatz von standardisierten Schnittstellen und APIs gewährleisten sie eine hohe Interoperabilität zwischen den verschiedenen Plattformkomponenten.
Ein wesentliches Element des UDA ist die Automatisierung der Metadatenverwaltung und der Datenpipelining-Prozesse. So können Daten automatisch katalogisiert, versioniert und aufbereitet werden, was sowohl die Datenqualität verbessert als auch die Nutzererfahrung für Data Scientists und Entwickler optimiert. Zudem fördert diese Automatisierung die Transparenz und Nachvollziehbarkeit der Datenherkunft, was für Governance und Compliance von großer Bedeutung ist. Das Prinzip „Model Once, Represent Everywhere“ hebt auch das Thema Wiederverwendbarkeit hervor. Werden einmal belastbare Datenmodelle erstellt, können diese in verschiedensten Kontexten, sei es in Dashboards, Reports oder Algorithmen, eingesetzt werden.
Dies spart Zeit und Ressourcen und erhöht gleichzeitig die Agilität des Unternehmens, da neue Anwendungen schneller auf vorhandenen Modellen aufbauen können. Netflix profitiert durch die UDA maßgeblich bei der Personalisierung der Nutzererfahrung. Durch konsistente und gut verwaltete Datenmodelle können Algorithmen präzisere Empfehlungen aussprechen, die direkt auf ein einheitliches Datenfundament zurückgreifen. Darüber hinaus erleichtert die einheitliche Architektur die Zusammenarbeit zwischen Teams unterschiedlicher Fachrichtungen, etwa zwischen Data Engineers, Data Scientists und Produktmanagern. Im Zuge der stetigen Erweiterung des Contents und der stark wachsenden Nutzerzahlen ist eine skalierbare Architektur von entscheidender Bedeutung.