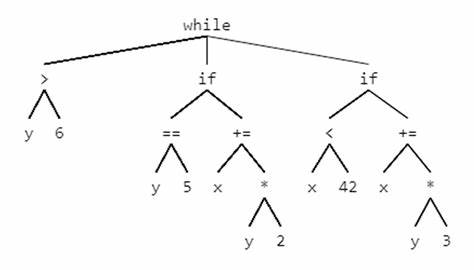
Der abstrakte Syntaxbaum, oft als AST bezeichnet, ist ein zentrales Konzept in der Compilerentwicklung und der Quellcodeanalyse. Er stellt den Quellcode in einer Baumstruktur dar, die für Compiler leicht verarbeitbar und interpretierbar ist. Statt linearer Quellcodezeilen werden Operatoren, Operanden und Konstrukte als Knoten in einem Baum abgebildet. Das ermöglicht Optimierungen, Analyseoperationen und die Generierung von Maschinencode. Gerade in der Sprache C, die keine eingebauten Sprachmittel für komplexe Datenstrukturen wie tagged unions und Vererbung besitzt, wird die handwerkliche Umsetzung eines solchen Baumes zu einer besonderen Herausforderung.
Dieses Thema wurde 2022 von Vladimir Keleshev ausführlich behandelt und mit einem praktischen Beispiel illustriert, das zeigt, wie ein abstrakter Syntaxbaum in C effizient konstruiert, benutzt und sogar in x86-64 Assembly-Code übersetzt werden kann. Ein AST besteht grundsätzlich aus verschiedenen Knotentypen. In Keleshevs Beispiel stehen drei Typen im Vordergrund: Zahlenwerte (AST_NUMBER), Addition (AST_ADD) und Multiplikation (AST_MUL). Die Baumstruktur spiegelt dabei den Rechenausdruck in übersichtlicher Form wider. Ein komplexer arithmetischer Ausdruck wie 4 + 2 * 10 + 3 * (5 + 1) wird nicht einfach von links nach rechts gelesen, sondern entsprechend der mathematischen Operatorprioritäten und Klammerung als Baum organisiert.
Das erleichtert spätere Verarbeitungsschritte. Im Unterschied zu objektorientierten oder funktionalen Sprachen, die beispielsweise Klassenhierarchien oder variant types (Tagged Unions) bereitstellen, muss C diese Konstrukte manuell implementieren. Keleshev wählt dafür eine Technik, die eine enumerierte Struktur (enum) mit einem union-Datentyp kombiniert. Das enum definiert die Art des Knotens (also ob es sich um eine Zahl, Addition oder Multiplikation handelt), während das union unterschiedliche Speicherkonstrukte für jede Knotentype festlegt. Wichtig ist hierbei, dass die einzelnen union-Elemente selbst wieder rekursive Verweise auf andere AST-Knoten beinhalten können – somit entsteht die Baumstruktur.
Da C keine rekursiven Typdefinitionen innerhalb der einfachen Strukturbeschreibung zulässt, erfolgt eine sogenannte forward-declaration. Das heißt, der Typ AST wird zunächst als struct AST deklariert, bevor die genaue Definition folgt. Dadurch können die union-Mitglieder Pointer auf AST enthalten, die zum Beispiel bei komplexen Ausdrucksknoten die linken und rechten Teilbäume darstellen. Das Design der tagged union verlangt eine mehrfachige Verwendung von identischen Bezeichnern: als Enum-Wert, als Name der verschachtelten Struktur und als Union-Mitglied. Dieses Vorgehen bringt den Vorteil mit sich, dass Code später klar und nachvollziehbar ist.
Die Einheitlichkeit der Namensgebung erleichtert beispielsweise das Schreiben von Funktionsaufrufen oder die Wartung. Gleichzeitig ist diese Technik typisch für C, das nicht über Sprachfeatures verfügt, die solche Muster auf natürliche Weise abbilden könnten. Die Erstellung eines konkreten AST-Knotens erfolgt über eine Funktion namens ast_new, die Speicher dynamisch auf dem Heap alloziert und initialisiert. Dadurch kann der Baum beliebig wachsen, ohne an feste Array-Größen gebunden zu sein. Durch die Übergabe eines AST-Werts an ast_new wird eine neue Kopie des Knotens erzeugt und dessen Adresse zurückgegeben.
Dieser Pointer verweist dann auf ein Element im Baum. Allerdings ist die schlichte Konstruktion eines Knotens in C durch die Notwendigkeit von expliziten Typangaben und Designated Initializers etwas umständlich. Ein Beispiel: Um einen Ausdruck wie 5 + 1 zu erzeugen, müssen die Teilbäume für die Zahlen 5 und 1 als AST_NUMBER-Knoten separat erzeugt und dann in einen AST_ADD-Knoten eingepackt werden. Dabei verlangt C, dass das union-Mitglied mit .AST_ADD bezeichnet wird, um den richtigen Teil der Union zu initialisieren.
Um den Programmieraufwand zu verringern, bietet sich die Nutzung von Makros an, die mehrfach verwendete Muster bündeln und somit Boilerplate reduzieren. Ein variadisches Makro namens AST_NEW verbindet die Enum-Werte und Strukturnamen miteinander und erlaubt die kompakte Erstellung von AST-Knoten. So wird etwa AST_NEW(AST_NUMBER, 4) zu einem Ausdruck, der den entsprechenden AST_NUMBER-Knoten erstellt und ihn mit der Zahl 4 befüllt. Diese Art der Implementierung zeigt deutlich die typischen Stärken und Schwächen von C in der Compilerentwicklung: Einerseits lässt sich alles manuell und präzise steuern, andererseits ist mehr Boilerplate notwendig als in moderneren Sprachparadigmen. Trotzdem gelingt es auf diese Weise, eine handhabbare und performante Datenstruktur für den AST zu schaffen.
Die Verwendung des AST beschränkt sich jedoch nicht nur auf die Datenhaltung. Um etwa den Ausdruck lesbar auszugeben, dient eine Pretty-Printing-Funktion. Sie durchläuft den Baum rekursiv und gibt je nach Knotentyp den entsprechenden ausdruck in Klammern und mit Operatoren zwischen den Teilbäumen aus. Dazu wird ein switch-Statement auf den enum-Wert verwendet, das je nach Fall die zugehörigen union-Daten extrahiert und verarbeitet. Diese Technik entspricht dem sogenannten Pattern Matching, wie es aus funktionalen Sprachen bekannt ist, ist aber in C nur über switch-case-Strukturen realisierbar.
Wichtig ist, dabei auf Vollständigkeit zu achten, damit alle Knotentypen behandelt sind. Moderne Compiler wie gcc oder clang können mittels Warnflags (-Wswitch, -Werror) unterstützen, die Entwickler auf fehlende Fälle aufmerksam machen. Das AST kann darüber hinaus auch zur Speicherbereinigung verwendet werden. Da jede AST-Instanz dynamisch alloziert wird, muss die Speicherfreigabe manuell erfolgen, um Speicherlecks zu vermeiden. Die Funktion ast_free tut dies, indem sie ebenfalls rekursiv in die Baumstruktur eintaucht und Kindknoten vor dem Freigeben bearbeitet.
Auch hier hat sich der switch-Ansatz bewährt. Eines der spannendsten Anwendungsfelder eines AST ist schließlich die Codeerzeugung. Keleshev demonstriert, wie einfache Ausdrücke mittels AST in x86-64 Assembly übersetzt werden können. Dazu wird eine ast_emit-Funktion definiert, die für jeden Knoten Maschinencode in Intel-Syntax ausgibt. Die Basisfälle laden dabei Werte in das Register rax, während Addition und Multiplikation den Stack nutzen, um Zwischenergebnisse zu speichern und zu kombinieren.
Zur Kompilierung komplexerer Programme bietet es sich an, einen Einstiegspunkt zu definieren. Keleshev erweitert hierfür den AST um einen Knotentyp namens AST_MAIN, der einen einzelnen Baumknoten als Programmkörper enthält. Beim Emitten generiert der Compiler dann die passenden Direktiven für eine globale main-Funktion, ergänzt mit einem ret-Befehl für die Rückkehr. So wird aus dem Baum ein eigenständiges ausführbares Programm. Das generierte Assembly kann direkt mit einem Assembler wie gccs native Unterstützung für Intel-Syntax übersetzt werden.
Das Ergebnis entspricht der mathematischen Auswertung des ursprünglichen Ausdrucks und wird als Rückgabewert des Programms übergeben. Abschließend bietet Keleshev einen Vergleich mit einer funktionalen Sprache wie OCaml an. Dort sind solche Baumstrukturen mit Varianten und Pattern Matching viel eleganter realisierbar, was Typ- und Speichersicherheit vereinfacht und den Entwickleraufwand mindert. Trotzdem zeigt das C-Beispiel eindrucksvoll, wie wichtige Grundlagen und Konzepte einer AST-basierten Compilerarchitektur auch in einer minimalistischen Umgebung umgesetzt werden können. Für Entwickler und Interessierte ist dieses Beispiel ein wertvoller Einblick in die pragmatische Arbeit mit abstrakten Syntaxbäumen in C.
Es verdeutlicht die Herausforderungen und erläutert praktikable Lösungen zur Konstruktion, Verarbeitung und Erweiterung von ASTs. Dabei lässt sich nicht nur das nötige technische Know-how gewinnen, sondern auch ein tieferes Verständnis für den Aufbau moderner Compiler und deren innere Funktionsweise. Die Kombination aus Memory-Management, rekursiver Programmierung und Codegenerierung macht das Arbeiten mit ASTs zu einer faszinierenden Aufgabe, die weit über die reine Syntaxanalyse hinausgeht. In der Praxis eröffnen solche Strukturen viele Möglichkeiten, etwa für Syntaxanalyse, Optimierungen oder die Implementierung eigener Domain-spezifischer Sprachen. Wer sich mit Compilerbau beschäftigt, findet in der dargestellten Technik eine solide Basis, die auf C-Grundlagen aufbaut und trotzdem effizient und erweiterbar ist.
Die vorgestellten Muster und Herangehensweisen sind dabei universell anwendbar und helfen, den Umgang mit komplexen Datenstrukturen in C besser zu meistern. Zusammenfassend zeigt sich, dass abstrakte Syntaxbäume trotz der sprachlichen Limitierungen von C realisierbar sind und viele Vorteile für die Programmverarbeitung bieten. Durch sorgfältiges Design, klare Namenskonventionen und unterstützende Compilerhinweise kann die Robustheit gesteigert werden. Der Weg vom Quellcode über den AST hin zu lauffähigem Maschinencode wird sichtbar und nachvollziehbar gemacht – und das mit verhältnismäßig wenig Aufwand und großer Flexibilität.



![US Banned All Huawei Chips Worldwide Then Reversed It? (Gov Docs) [video]](/images/3E8D9C2F-5569-4CCC-B32E-EE4C5CC16F2A)