Apache Spark hat sich in den letzten Jahren als eine der wichtigsten Plattformen für Big Data-Verarbeitung etabliert. Die Fähigkeit, große Datenmengen schnell und effizient zu analysieren, macht Spark zu einem beliebten Werkzeug in Unternehmen und Forschungseinrichtungen. Doch wie bei jeder komplexen Softwareumgebung kann die Performance von Spark-Jobs stark variieren, und ohne entsprechende Analysewerkzeuge wird die Optimierung zur Herausforderung. Hier kommt SparkMeasure ins Spiel – ein Tool, das gezielt entwickelt wurde, um Performance-Probleme bei Apache Spark Jobs zu identifizieren, zu messen und zu verstehen. SparkMeasure erlaubt es Entwicklern und Dateningenieuren, die Leistung ihrer Spark-Anwendungen mit detaillierten Metriken transparent und umfassend zu überwachen.
Anders als die standardmäßigen Überwachungs- und Logging-Tools von Spark konzentriert sich SparkMeasure auf die Sammlung granularer Leistungsdaten auf Task- und Stufenebene. Diese Daten bilden die Grundlage, um Engpässe, ineffiziente Ressourcennutzung oder andere Flaschenhälse systematisch aufzudecken. Das Tool unterstützt verschiedene Anwendungen und Workflows. Egal ob in der Entwicklungsphase, im kontinuierlichen Integrationstest oder bei der Analyse produktiver Batch-Jobs – SparkMeasure liefert wertvolle Insights zur Laufzeit und Ressourcenverwendung. Zudem kann es nahtlos in gängige interaktive Umgebungen wie Jupyter Notebooks, pyspark oder spark-shell integriert werden.
Diese Flexibilität macht SparkMeasure ideal, um sowohl im explorativen Kontext als auch für automatisierte Testpipelines eingesetzt zu werden. Eine der besonderen Stärken von SparkMeasure ist die Möglichkeit, komplexe Spark-Metriken nicht nur zu erfassen, sondern auch direkt auszuwerten. Die Benutzer erhalten umfassende Berichte über verschiedene Kennzahlen wie die Anzahl der ausgeführten Aufgaben, die Dauer einzelner Stufen, die CPU-Zeit der Executor, Garbage Collection Zeiten oder Shuffle-Operationen mit ihren jeweiligen Kosten. Diese Kennzahlen helfen unmittelbar dabei, Performance-Beeinträchtigungen zu identifizieren und fundierte Optimierungsschritte zu planen. Im Gegensatz zu herkömmlichen Monitoring-Tools, die sich oft nur auf reine Laufzeit oder Ressourcenspitzen beschränken, bietet SparkMeasure einen detaillierten Einblick in die internen Abläufe der Spark-Architektur.
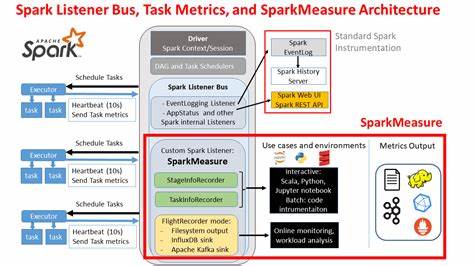
Beispielsweise wird ersichtlich, wie lange einzelne Tasks auf Executor-Ebene laufen, wie viel Zeit für Netzwerk- oder Festplattenoperationen aufgewendet wird und wie der Speicherverbrauch innerhalb der JVM aussieht. Diese Detailgenauigkeit ermöglicht eine präzisere Ursachenforschung und schützt Entwickler davor, an Symptomen statt an der eigentlichen Problemstelle zu arbeiten. Die technische Architektur von SparkMeasure basiert auf Spark Listenern, einer Schnittstelle, die bereits in Apache Spark verwendet wird, um Ausführungsmetriken zu sammeln. Über diese Listener werden während der Ausführung von Spark-Jobs Datenströme von den Executor-Prozessen an den Treiber gesandt, wo sie aggregiert, ausgewertet und in Berichtsform gebracht werden. Dadurch ist eine nahezu „live“ Analyse möglich, ohne dass der normale Jobablauf wesentlich gestört wird.
Darüber hinaus unterstützt SparkMeasure die sogenannte Flight Recorder Mode, bei der Performance-Daten während der Job-Ausführung transparent und kontinuierlich erfasst und extern gespeichert werden. Dies ist besonders für produktive Cluster-Rechenumgebungen von Vorteil, wo eine dauerhafte Performanceüberwachung etabliert werden soll. Die Metriken können in Dateisysteme abgelegt oder an externe Überwachungslösungen wie InfluxDB, Apache Kafka oder Prometheus Pushgateway übergeben werden. Diese Integration ermöglicht es Unternehmen, zentrale Monitoring-Dashboards aufzubauen und Trends sowie Anomalien frühzeitig zu erkennen. Die Nutzung von SparkMeasure beginnt klassisch mit der Integration in die Spark-Umgebung.
Über Paketmanager oder direkt mittels JAR-Dateien kann das Tool eingebunden werden. Anschließend bietet SparkMeasure eine API, die sich sowohl in Scala- als auch in Python-Projekte einfügt. Entwicklern stehen einfache Funktionen zur Verfügung, um Messungen zu starten, Zwischenergebnisse abzurufen und finale Reports zu generieren. Als Beispiel kann man Spark SQL Queries messen, indem man die jeweilige Ausführungsphase explizit umgarnt und die gesammelten Metriken direkt ausliest. Ein großer Vorteil von SparkMeasure ist die Unterstützung mehrerer Programmiersprachen.
Ob Scala, Java oder Python – alles wird vollumfänglich unterstützt. Damit stehen vielfältige Einsatzszenarien offen, die sowohl klassischen Big Data-Entwicklern als auch Datenwissenschaftlern und DevOps-Teams gerecht werden. Insbesondere bei der Arbeit in interaktiven Notebooks wird die Echtzeitanalyse der Performance zu einem praktischen Helfer. Neben der direkten Performance-Messung kann SparkMeasure auch als Lern- und Lehrwerkzeug dienen. Es illustriert eindrucksvoll die Arbeitsweise der Spark Listener und macht intern erhobene Leistungsdaten für Anwender zugänglich.
Für viele, die Apache Spark vertiefen wollen, ist SparkMeasure so eine wertvolle Ergänzung, um praktische Einblicke in die Funktionsweise der Plattform zu gewinnen und ein besseres Verständnis für Optimierungsansätze zu entwickeln. Bei der Auswahl zwischen Stage- und Task-Metriken gilt es zu beachten, dass die Stufen-Metriken generell leichtergewichtig und für viele Anwendungen ausreichend sind. Werden tiefergehende Einblicke benötigt, etwa zur Analyse von „Straggler“-Tasks oder Lastverteilung im Cluster, können Task-Metriken genutzt werden, die detailreicher, aber auch speicher- und rechenintensiver sind. Ein weiterer wichtiger Punkt ist die Kompatibilität mit unterschiedlichen Spark-Versionen. SparkMeasure wird aktiv weiterentwickelt und unterstützt die aktuellen Major Releases, darunter Spark 4.
x mit Scala 2.13 sowie verschiedene Versionen der Spark 3.x Reihe. Für ältere Spark-Versionen gibt es weiterhin passende SparkMeasure-Ausgaben, so dass auch Legacy-Projekte profitieren können. Die Dokumentation des Tools ist umfangreich und hält zahlreiche Beispiele bereit, die den Einstieg erleichtern.
Von einfachen Mess-Skripten über die Integration in CI/CD-Pipelines bis hin zur Nutzung der Flight Recorder Funktionalität finden Anwender reichlich Material, um SparkMeasure optimal zu nutzen. Präsentationen und Blogartikel vermitteln zudem Best Practices und Fallstudien, wie SparkMeasure in realen Szenarien eingesetzt wird. Wie bei jedem Instrument gibt es auch Limitierungen. SparkMeasure ist hauptsächlich für Single-Threaded-Driver-Umgebungen konzipiert, weshalb parallele Spark-Aktionen auf dem Driver zu verfälschten Metriken führen können. Zudem erfasst das Tool vor allem erfolgreich durchgeführte Tasks und zieht bei fehlerhaften Tasks keine Ressourcenwerte heran.
Auch externe Ressourcenverbraucher, etwa Python-Prozesse in UDFs, werden aktuell nicht erfasst. Trotz dieser Einschränkungen ist SparkMeasure ein unverzichtbarer Helfer, wenn es darum geht, Spark-Jobs genauer zu verstehen und gezielt zu optimieren. In einer Welt, in der effiziente Big Data Verarbeitung oft die Grundlage für geschäftlichen Erfolg darstellt, sind Tools wie SparkMeasure der Schlüssel zu Transparenz und maximaler Performance. Die wachsende Bedeutung von Apache Spark in der Industrie erfordert ein ebenso professionelles Werkzeugset zur Performanceanalyse. SparkMeasure füllt diese Lücke überzeugend aus, indem es die komplexen Spark-Metriken in verständliche und nutzbare Informationen umwandelt.
So ermöglicht es Anwendern, verborgene Probleme zu entdecken, die Performance zu verbessern und letztlich zuverlässigere Datenpipelines zu betreiben. In Zukunft wird SparkMeasure voraussichtlich durch weitere Features und tiefere Integrationen wachsen. Die aktive Community trägt kontinuierlich zur Verbesserung und Erweiterung bei. Entwickler und Dateningenieure profitieren somit von einem ständig aktuellen und praxisnahen Toolset. Zusammenfassend lässt sich sagen, dass SparkMeasure einen wertvollen Beitrag zur Optimierung von Apache Spark Jobs leistet.
Es verbindet technisches Know-how mit praktischer Anwendbarkeit und unterstützt Anwender von der Entwicklungsphase bis zum produktiven Betrieb. Wer Spark-Prozesse performant und stabil gestalten möchte, sollte SparkMeasure in seiner Toolbox haben.




![The Synthesizer - a blessing or a curse? (1983) [video]](/images/684D7D44-55C0-4CBB-BF55-801AC0946150)