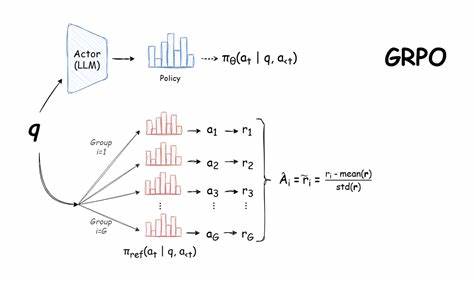
Im Zuge der rasanten Entwicklungen im Bereich der Künstlichen Intelligenz hat sich die Fähigkeit von Sprachmodellen stetig verbessert. Insbesondere das Trainieren eines Sprachmodells mit der Methode GRPO (Generative Reinforcement Learning with Policy Optimization) hat neue Türen für komplexe Aufgabenstellungen geöffnet. Eine besonders interessante Anwendung liegt in der automatisierten und optimierten Planung von Veranstaltungen – ein Bereich, der in verschiedensten Branchen eine enorme Bedeutung besitzt. Das Training eines solchen Modells wirft spannende Herausforderungen und Lernmöglichkeiten auf, von der klaren Definition der Problemstellung über den Aufbau eines geeigneten Datensatzes bis hin zur Feinjustierung der Belohnungsfunktionen für das Training. Damit eröffnet sich nicht nur Innovation im technischen Sinne, sondern es werden auch praktische Lösungen für ein komplexes Planungsproblem geboten.
Beginnend mit der konkreten Problemdefinition wird die Notwendigkeit deutlich, eine Planung zu erzeugen, die eine Liste von Ereignissen mit vorgegebenen Start- und Endzeiten sowie unterschiedlichen Prioritäten berücksichtigt. Ziel ist es, den maximalen Gesamtwert des Zeitplans zu erreichen, wobei prioritäre Termine doppelt gewichtet werden. Obwohl die Aufgabe grundsätzlich nachvollziehbar scheint, stellt sie aufgrund von terminlichen Überschneidungen und der Gewichtung der Prioritäten eine nicht-triviale Herausforderung dar. Die Problemstellung entspricht einer Variante des gewichteten Intervall-Scheduling-Problems, das klassischerweise durch dynamische Programmierung gelöst wird. Damit kann ein optimaler Referenzwert für die Bewertung von Modelloutputs berechnet werden, was essenziell für eine verifizierbare Belohnung im GRPO-Training ist.
Ein weiterer wichtiger Schritt ist die Generierung eines realitätsnahen Datensatzes. Anstatt auf fertig annotierte Outputs zurückzugreifen, wie es bei überwachten Lernverfahren üblich ist, genügt bei GRPO die Bereitstellung von Prompt-Daten und der Definition von Belohnungsfunktionen. So entstand ein Datensatz mit hunderten Beispielen, die verschiedene Veranstaltungen aus unterschiedlichen Kategorien und zufälligen Priorisierungen enthalten. Durch die Simulation von Zeitüberschneidungen werden die realen Planungsprobleme abgebildet. Die Datenaufbereitung integriert systematische Anweisungen an das Sprachmodell, um die Einhaltung klarer Formatregeln zu gewährleisten, wie etwa die Verwendung bestimmter XML-ähnlicher Tags für Denkprozess- und Ergebnisdarstellung.
Die Wahl des Basismodells ist eine strategische Entscheidung mit hoher praktischer Relevanz. Ein Code-basiertes Modell der Qwen-Familie mit 7 Milliarden Parametern erwies sich als geeignet, da es schon vorab strukturiertes Output-Format gut beherrscht und eine ausreichende Leistungsfähigkeit für den komplexeren Planungsprozess zeigt. Kleinere Modelle waren weniger effektiv, was die Grenze der Leistungsfähigkeit und die Voraussetzungen für erfolgreiches GRPO-Training verdeutlicht. Das Training selbst erfordert die Definition geeigneter Belohnungsfunktionen, die den Lernprozess inhaltlich steuern. Neben der Überprüfung des korrekten Formats fordert eine zentrale Funktion die Modelloutputs auf, eine chronologisch geordnete Planung aus mindestens zwei gültigen Events ohne Überschneidungen zu liefern, um ein positives Signal zu erzeugen.
Zudem wird die Qualität der Planung über den Anteil der maximal möglichen gewichteten Dauer bemessen. Interessanterweise verdeutlicht die Erfahrung eines Zusammenspiels zwischen zu groben und zu feingliedrigen Reward-Komponenten die Bedeutung einer Balance. Zu simple Belohnungen ergeben kaum Lernanreize, während zu viele Teil-Belohnungen den Lernprozess verzerren und reward hacking begünstigen können. Ein präzise abgestimmtes und robustes Belohnungssystem stellte sicher, dass das Modell in Relation zur optimalen Lösung lernte und valide Terminpläne mit gleitender Verbesserung generierte. Die Trainingsverläufe bestätigen, dass das Modell schrittweise immer bessere Ergebnisse liefert, bei denen Schonformat, Reihenfolge und Auswahl von Events deutlich gelernt wurden.
Eine genaue Analyse der Modellausgaben während der verschiedenen Trainingsphasen zeigt einen klaren Lernfortschritt in der Berücksichtigung von Prioritäten und der Vermeidung von Konflikten. Dennoch offenbarten sich auch Schwächen, etwa eine tendenzielle Überschreitung der Start- und Endzeiten einzelner Events oder gelegentliche Überschneidungen, die zu weiteren Optimierungsansätzen anregen. Überraschend bleibt außerdem, dass eine vermeintliche „Aha-Erkenntnis“ im Sinne eines anthropomorphen Reflexionsprozesses beim Modell beim Training mit GRPO in diesem Anwendungsfall kaum sichtbar wurde. Dies deckt sich mit neueren Forschungsergebnissen, die ähnliche Phänomene bereits in unveränderten Basismodellen fanden und die Wirksamkeit eines solchen Effekts skeptisch hinterfragen. Bei der Evaluation auf einem unabhängigen Testsatz zeigte das trainierte Modell eine klare Leistungssteigerung gegenüber dem Ausgangsmodell und übertraf sogar ein deutlich größeres Modell derselben Familie.
Formatfehler, inkorrekte Reihenfolgen und die Wahl nicht existierender Events konnten nahezu eliminiert werden. Zwischenzeitlich zeigte sich allerdings, dass Überschneidungen von Events weiterhin eine Hürde darstellen, was neben möglichen Fehlerquellen bei der Belohnungsformulierung auch dem begrenzten Trainingseinsatz geschuldet sein kann. Aus diesen Erfahrungen lassen sich mehrere wichtige Erkenntnisse ableiten, die für zukünftige Projekte mit GRPO und ähnlichen Reinforcement-Learning-Methoden relevant sind. Das Training erfolgt am effektivsten in klar verifizierbaren Problemfeldern, die per deterministischer Reward-Funktion messbar sind. Ebenso ist die Wahl eines Basismodells mit einer gewissen Grundfähigkeit zur Aufgabe entscheidend für den Erfolg.
Zudem sollten Belohnungsfunktionen sorgfältig geplant werden, um Balance zwischen Lernanreiz und Einflussnahme zu gewährleisten. Nicht zuletzt kann spezialisierte Software wie Unsloth für GPU-effizientes Training nützlich sein, bringt jedoch mitunter Probleme bei Stabilität und Kompatibilität mit sich. Insgesamt demonstriert die experimentelle Anwendung von GRPO bei der Veranstaltungsplanung, wie spezialisierte Sprachmodelle durch verstärkendes Lernen in eingeschränkten, jedoch praxisrelevanten Szenarien trainiert werden können. Diese Methodik eröffnet Potenziale für weitere Anwendungsbereiche, in denen klare Erfolgskriterien vorliegen und flexible Modellanpassungen gewünscht sind. Während noch Verbesserungspotential insbesondere bei der Verhinderung von Terminüberschneidungen besteht, unterstreichen die erzielten Fortschritte die Effektivität von GRPO gegenüber klassischen Ansätzen.
Die Erfahrung zeigt auch, dass eine bewusste Herangehensweise an Problemformulierung, Datengenerierung, Modellwahl und Belohnungsdesign fundamentale Bausteine für erfolgreiches Lernen im KI-Bereich sind. Künftig könnten komplexere Planungsszenarien, Anpassungen an branchenspezifische Vorgaben oder die Kombination mit anderen Trainingsmethoden weiterführende Verbesserungen erlauben und die Automatisierung im Event- und Terminmanagement deutlich voranbringen. Die offene Bereitstellung von Code, Datensätzen und Trainingsergebnissen auf Plattformen wie Hugging Face unterstützt diesen Innovationsprozess und ermöglicht ein breites gemeinschaftliches Weiterarbeiten. Zusammengefasst zeigt die Arbeit exemplarisch, wie aus theoretischen Konzepten reale, praxisnahe Anwendungen entstehen können – ein Meilenstein für den KI-gestützten Ausbau intelligenter Planungssysteme.








