Die Entwicklung eines eigenen Suchsystems ist eine durchaus herausfordernde Aufgabe, die nicht nur technische Fähigkeiten, sondern auch ein tiefes Verständnis der Informationsrückgewinnung und Performanceoptimierung voraussetzt. Im August 2024 stellte ich mich genau dieser Herausforderung, indem ich mit SearchArray eine eigene Suchbibliothek entwickelte und diese mit dem Branchenriesen Elasticsearch verglich. Das Ergebnis war ernüchternd – mein System blieb in allen relevanten Bereichen deutlich hinter Elasticsearch zurück. Doch gerade diese Erfahrung ermöglichte tiefe Einblicke in die Funktionsweise moderner Suchmaschinen und zeigte eindrucksvoll, warum etablierte Suchtechnologien wie Elasticsearch weiterhin ungeschlagen sind. Diese Erkenntnisse möchte ich im Folgenden ausführlich teilen und damit nicht nur das Scheitern erläutern, sondern auch den Lernprozess für andere Entwickler dokumentieren, die sich im Bereich der Suchtechnologien versuchen möchten.
Grundlagen moderner Suchmaschinen Basierend auf dem BM25-Modell Die meisten aktuellen Suchsysteme, darunter auch Elasticsearch, setzen auf sogenannte lexikalische Suche, bei der Dokumente anhand der Vorkommen bestimmter Suchbegriffe bewertet werden. Ein gängiges Ranking-Verfahren ist das BM25-Modell, welches die Relevanz eines Dokuments zu einem Suchbegriff über verschiedene Faktoren wie Termfrequenz, Dokumentenlänge und Inverse Dokumentenhäufigkeit berechnet. Wenn beispielsweise nach "luke skywalker" gesucht wird, wird nicht nur die individuelle Bewertung jedes einzelnen Begriffs untersucht, sondern mithilfe spezieller Algorithmen ein kombinierter Score über alle relevanten Dokumente ermittelt. Die Herausforderung im Suchprozess besteht insbesondere darin, bei Suchanfragen mit mehreren Begriffen effizient nur die wirklich relevanten Dokumente zu bewerten, um hohe Leistung und Antwortgeschwindigkeit zu garantieren. Elasticsearch nutzt hierfür ausgeklügelte Algorithmen wie den Weak-AND oder WAND-Algorithmus, die das Durchsuchen riesiger Datenmengen optimieren, indem sie gezielt nur diejenigen Dokumente prüfen, die überhaupt Chancen haben, in den Top-Ergebnissen zu landen.
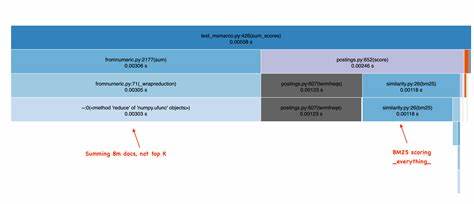
Der Unterschied zu SearchArray: Vom simplen BM25-Array zur effizienten Top-K Suche Mein Projekt SearchArray war ursprünglich als Werkzeug konzipiert, um innerhalb von Pandas DataFrames Volltextsuche zu ermöglichen. Dabei berechnet das System BM25-Scores für jeden Begriff über alle Dokumente, gibt diese als große NumPy-Arrays zurück und addiert diese simpel für alle Suchbegriffe. Obwohl diese Methode theoretisch korrekt ist, so ist sie in der Praxis höchst ineffizient – da sie keine Mechanismen für frühes Aussortieren von weniger relevanten Dokumenten oder andere Optimierungen nutzt, die Elasticsearch auszeichnen. Elasticsearch hingegen durchbricht mit seinen WAND-Techniken diese naive Summierung, indem es gezielt nur eine Untermenge von Dokumenten scannt, die zusammen mit dem höchsten BM25-Score Aussicht auf eine Platzierung in den Top-Ergebnissen haben. Besonders seltene Begriffe (wie "skywalker") kommen nur in wenigen Dokumenten vor, daher kann das System diese gezielt und schnell durchsuchen.
Häufige Begriffe (wie "luke") haben dagegen ein riesiges Postings-List, aus dem Elasticsearch nur große Teile überspringt, wenn klar ist, dass deren Bewertung nicht zu besseren Ergebnissen führen kann. Implementierungstechnische Hintergründe und deren Auswirkungen auf Performance Ein weiterer ausschlaggebender Punkt ist die Datenstruktur für die Speicherung der Indizes. Während Suchmaschinen üblicherweise Postings-Listen verwenden, die termbezogene Dokumentlisten mit Häufigkeitsangaben enthalten, arbeitet SearchArray mit einer Positionsindex-Struktur, die ursprünglich für Phrasensuche optimiert ist. Diese basiert auf sogenannten Roaring Bitmaps, die präzise Dokumentpositionen einzelner Begriffe speichern und durch effiziente Bitoperationen das Auffinden von Phrasen ermöglichen. Diese Bitmaps bieten zwar Vorteile für Phrasensuche, verursachen bei reinen BM25-Berechnungen jedoch erheblichen Mehraufwand, weil daraus erst noch Termfrequenzen ermittelt werden müssen.
Auch die Verwendung von Bit-Counts und das notwendige Caching stellen hier einen Kompromiss dar, welcher zu längeren Rechen- und Verzögerungszeiten führt. Ein weiterer wichtiger Faktor ist das Caching von BM25-Komponenten, die nicht von den Suchbegriffen abhängen. In einer Service-Umgebung lohnt es sich, Teile der Fitness-Berechnung für Dokumentlängen je einmal global vorzuberechnen und abzulegen. Viele Suchmaschinen implementieren eine solche Cache-Strategie bereits, während mein System bewusst aus Wartungsaufwandsgründen darauf verzichtet, was in der Summe die Latenz erhöht. Dynamische Query-Verarbeitung versus starre Summierung Große Suchplattformen wie Elasticsearch oder Solr bieten flexible Query-Sprachen (Query DSL) an, mit denen komplexe Suchanfragen geplant, optimiert und zwischengespeichert werden können.
Diese ermöglichen eine intelligente und datenabhängige Herangehensweise an Mehrbegriff-Anfragen. Im Gegensatz dazu stellt SearchArray dem Nutzer lediglich Werkzeuge bereit, um einzelne BM25-Scores auszurechnen, zwingt diesen aber, die Aggregation und Summierung selbst zu betreiben. Dies ist zwar transparent und für Prototyping nützlich, verursacht aber Leistungseinbußen und erschwert die Umsetzung effizienter, skalierbarer Suchmechanismen. Die Bedeutung von Ingenieurskunst und Infrastruktur Die großen Suchsysteme, die Elasticsearch seit Jahren prägen, sind das Ergebnis umfangreicher Ingenieurarbeit, die auch auf eine robuste Infrastruktur, verteilte Indizierung, Load-Balancing und Optimierung für Parallelisierung ausgelegt ist. Diese Komponenten fehlen einem kleinen Side-Project zwangsläufig, weshalb Skalierung auf Millionen von Dokumenten und gleichzeitige Behandlung von Suchanfragen limitiert sind.
So bleibt SearchArray mit etwa 18 Anfragen pro Sekunde (QPS) deutlich hinter Elasticsearchs 90 QPS zurück. Auch das Indexieren großer Dokumentmengen ist mit 3.500 Dokumenten pro Sekunde verglichen zu den 10.000 von Elasticsearch langsamer. Die NDCG@10 (Normalized Discounted Cumulative Gain) Werte des Suchergebnisses – ein Maß für die Relevanzbewertung – liegen hingegen nahe beieinander, was zeigt, dass die Grundlagen im BM25-Algorithmus korrekt implementiert sind und die Differenz in der Performance vor allem in den Optimierungen liegen.
Lerneffekt und Ausblick für Suchtechnologien Obwohl SearchArray in Performance und Effizienz begrenzt ist, zeigt das Projekt sehr schön die Komplexität, die hinter der scheinbar einfachen Aufgabe "Suche" steht. Neben der zugrundeliegenden Mathematik sind es vor allem intelligente Datenstrukturen, ausgefeilte Abbruchkriterien, Query-Optimierungen und Caching-Strategien, die einen suchmaschinenähnlichen Dienst robust und schnell machen. Die Vision, Suchabfragen mit einer Dataframe-artigen Query-Sprache zu verbinden, ist interessant und könnte in Zukunft neue Möglichkeiten eröffnen, die Flexibilität von Suchmaschinen mit der Nutzerfreundlichkeit und Kombinierbarkeit moderner Data Science Werkzeuge zu verknüpfen. Die aktuelle Landschaft zeigt allerdings, dass der Weg dorthin mit viel Aufwand und Detailarbeit gepflastert ist. Fazit: Wertschätzung für Suchingenieure und realistische Erwartungen Die Entwicklung einer effizienten Volltextsuchmaschine ist mehr als nur Softwareentwicklung – sie ist ein Handwerk, das jahrelange Expertise, Geduld und Know-how erfordert.
Während eigene Prototypen wie SearchArray wertvolle Lernerfahrungen bieten, sind die ausgereiften Systeme wie Elasticsearch und Solr nach wie vor das Nonplusultra in Sachen Skalierbarkeit, Geschwindigkeit und Suchqualität. Mit dieser Erkenntnis sollten Entwickler, Anwender und Entscheider die Arbeit von Suchingenieuren viel stärker würdigen. Ihre Arbeit hinter den Kulissen ermöglicht es uns allen, auf Millionen von Dokumenten in Bruchteilen von Sekunden relevante Informationen zu finden und intelligente Anwendungen wachsen zu lassen – eine Technologie, die wir nicht für selbstverständlich halten dürfen.