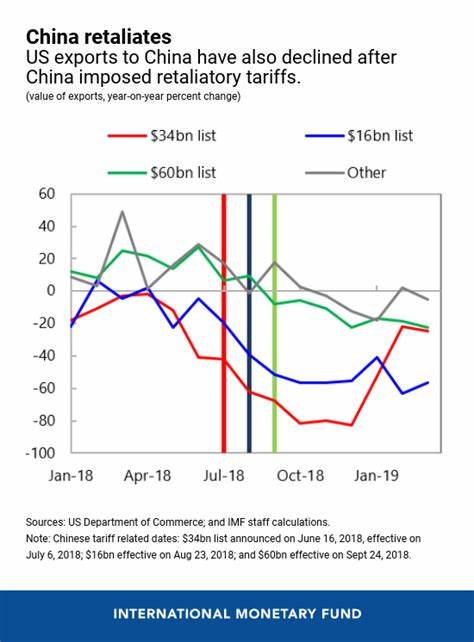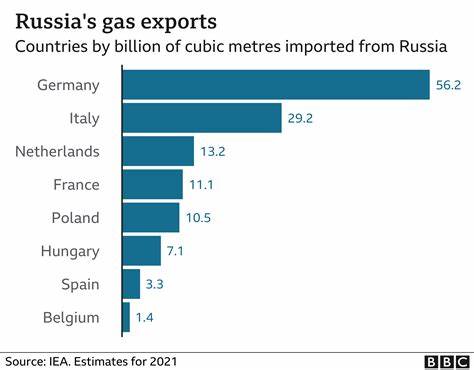
Die Analyse von Maschinencode ist ein spannendes und technisch anspruchsvolles Gebiet, das viele Möglichkeiten eröffnet, tiefere Einblicke in die generierte Maschinensprache von Compilern zu erhalten. Insbesondere wenn man statistische Auswertungen über die erzeugten Instruktionen oder das Verhalten von Registern anstellen möchte, ist es hilfreich, sich mit den richtigen Werkzeugen und Ansätzen vertraut zu machen. Im Fokus steht dabei häufig der x86_64 Maschinencode unter der SysV-ABI, da diese Architektur in der modernen Softwareentwicklung eine wichtige Rolle spielt. Viele Entwickler und Forscher stehen vor der Herausforderung, zu verstehen, wie Compiler wie gcc den Quellcode in Maschinensprache übersetzen und welche Instruktionen dabei wie häufig genutzt werden. Die Auswertung solcher Daten kann die Optimierung von Code ermöglichen, Sicherheitsanalysen unterstützen oder Einblicke in die Performance-Critical Paths einer Anwendung bieten.
Ein typisches Ziel ist es beispielsweise, Histogramme von verwendeten Befehlen zu erstellen oder die Verteilung der Nutzung von flüchtigen (volatile) sowie bewahrten (preserved) Registern innerhalb von Funktionen zu ermitteln. Ein Kernproblem besteht dabei darin, dass es keine leicht zugänglichen, vorgefertigten Tools gibt, die auf einfache Weise statistische Analysen direkt auf Maschinencode durchführen können. Insbesondere wenn man sich auf gcc spezialisiert und seinen Assembly-Dialekt benötigt, fehlen oft geeignete Parser oder Analysewerkzeuge, die zuverlässig und effizient mit der GNU Assembler-Syntax umgehen können. Dementsprechend greifen viele Nutzer auf zwei grundlegende Strategien zurück. Die erste besteht darin, gcc so zu konfigurieren, dass es nicht direkt Machine-Code, sondern Assembler-Code ausgibt.
Die erzeugte Assemblerausgabe kann dann geparst werden, um daraus Statistiken abzuleiten. Dieses Vorgehen bietet den Vorteil, dass die von gcc verwendete Assembler-Syntax weit dokumentiert ist und sich grob als Textdatei verarbeiten lässt. Dennoch erfordert das Erstellen eines robusten Parsers für GNU Assembler ein hohes Maß an Detailkenntnis, da die Syntax flexibel und manchmal komplex sein kann. Projekte wie der Compiler Explorer verfügen bereits über eigene Asm-Parser, die man als Grundlage oder Inspiration nutzen kann. Dadurch lässt sich der Entwicklungsaufwand deutlich reduzieren.
Die zweite Strategie zielt darauf ab, den Maschinencode direkt in Form von Objektdateien zu analysieren. Das bedeutet, dass man die Binärformate wie ELF (Executable and Linkable Format) versteht und entsprechend mit Bibliotheken wie elfutils arbeitet, um aus den Binärdaten Maschinencode zu extrahieren und zu disassemblieren. Anschließend kann man mit Disassembler-Tools die Maschinencodeinstruktionen identifizieren und auf diese Weise Statistiken generieren. Diese Methode ist näher an der echten Binärstruktur und ermöglicht zum Beispiel die Analyse kompletter Programme oder Bibliotheken. Allerdings erfordert sie mehr technisches Hintergrundwissen hinsichtlich der ELF-Spezifikationen, der Disassemblierung und der Interpretation der Maschinencodebefehle.
Für viele Projekte ist der Begriff „statische Analyse“ maßgeblich, da es darum geht, den Maschinencode ohne Ausführung zu untersuchen. Dies kann ohne Bezug zum ursprünglichen Quellcode erfolgen, was den Aufwand deutlich reduziert, da kein Mapping zwischen Instruktionen und Quelltext erforderlich ist. Möchte man jedoch Zusammenhänge zum Quellcode verstehen, beispielsweise für Debugging oder Optimierungszwecke, so sind Compiler-interne Datenstrukturen wie Abstract Syntax Trees (AST) relevant. Für gcc existieren Veröffentlichungen und Tools, die den Zugriff auf den AST erleichtern und Quellcodebezüge herstellen. Dies ist allerdings für reine Statistikzwecke nicht zwingend notwendig.
Die Wahl des geeigneten Weges hängt von den eigenen Anforderungen ab. Geht es ausschließlich um den Maschineninstruktionsstrom und Registerverwendung, so kann das Parsen der Assemblerausgabe bereits ausreichend sein und schneller zum Ziel führen. Möchte man jedoch komplexere Einblicke, etwa wie ein Programm mit dynamischen Sprüngen arbeitet oder wie Objektdateien zusammengesetzt sind, so ist die direkte Arbeit mit Objektdateien und Disassemblern vorteilhaft. Ein wesentliches technisches Detail ist die Architektur selbst. Der x86_64-Standard unter SysV-ABI definiert klare Regeln für die Benutzung von Registern und Aufrufkonventionen, was die Identifikation von volatilen und bewahrten Registern vereinfacht.
Kenntnisse über die ABI machen es möglich, die Relevanz einzelner Register im Kontext von Funktionen besser zu verstehen und in die Statistik einzubeziehen. Somit kann beispielsweise ermittelt werden, wie intensiv bestimmte Register in einem Programm genutzt oder geschont werden. Für die Umsetzung ist es häufig ratsam, auf etablierte Bibliotheken und Werkzeuge zurückzugreifen. Neben elfutils gibt es noch weitere Disassembler-Frameworks wie Capstone, die umfangreiche APIs für das Zerlegen und Interpretieren von x86_64-Instruktionen bieten. Diese erlauben die komfortable Analyse auf einer höheren Abstraktionsebene und sparen den Entwickler vor aufwendigen Low-Level-Implementierungen.
Durch die Kombination von Disassembler und der eigenen Statistiklogik lassen sich passgenaue Analyzer bauen, die genau die benötigten Metriken ausgeben. Darüber hinaus können Techniken aus dem Compilerbau helfen, etwa die Erzeugung und Verarbeitung von ASTs oder Zwischenrepräsentationen (IR) wie LLVM IR. Obwohl diese eher in höheren Phasen der Codeoptimierung liegen, liefern sie natürlich wertvolle Informationen über Instruktionsauswahl und Registerallokation. Insbesondere LLVM bietet sehr gute APIs und Tools, um solche Analysen durchzuführen, deren Ergebnisse sich dann theoretisch auf die eigentliche Maschinenebene zurückführen lassen. Für Nutzer, die sich von gcc lösen möchten, könnte diese Alternative lohnenswert sein.
Im Internet existieren zudem Diskussionsforen und offene Projekte, die sich mit Maschinenebenen-Analyse beschäftigen. Der Austausch mit erfahrenen Entwicklern ist sehr empfehlenswert, da sich viele Herausforderungen leichter lösen lassen, wenn man bewährte Praktiken oder gar fertige Code-Snippets verwenden kann. So wurden beispielsweise in Hacker News oder Open-Source-Communities schon ähnliche Fragen aufgeworfen, die hilfreiche Denkanstöße und Lösungsansätze bieten. Für Entwickler, die kompletten eigenen Workflow aufbauen wollen, sollte das Ziel sein, ein robustes Werkzeug zu erstellen, das sowohl zuverlässig alle Maschineninstruktionen erfasst als auch statistisch auswertet. Dabei ist auch der Umgang mit Sonderfällen wichtig, wie Inline-Assembler-Abschnitte oder ungewöhnliche Compiler-Optimierungen.
Die Aggregation der Daten in einer geeigneten Form etwa als CSV oder JSON ermöglicht die Nutzung weiterer Analysewerkzeuge oder die visuelle Aufbereitung der Resultate. Ein weiterer Aspekt ist die Performance der Analyse selbst. Gerade bei großen Binärdateien oder umfangreichen Programmen können die Datenmengen beträchtlich sein. Effiziente Parser und skalierbare Analysealgorithmen sind daher essenziell, um die Auswertung in angemessener Zeit durchzuführen. Moderne Programmiersprachen und parallele Verarbeitungstechniken bieten hier Optimierungsmöglichkeiten.
Nicht zuletzt sollte man auch mögliche Lizenzfragen bei Verwendung von Code oder Bibliotheken beachten, vor allem bei Einbindung in kommerzielle Projekte oder Open-Source-Anwendungen. Zusammenfassend lässt sich sagen, dass die Erstellung von Statistiken über Maschinencode ein technisch herausfordernder, aber lohnender Prozess ist, der wertvolle Einblicke für Entwickler und Forscher bietet. Die Wahl des richtigen Ansatzes hängt stark von den individuellen Zielen ab und bewegt sich häufig zwischen Assemblerparsing und Binärdatei-Disassemblierung. Wer sich intensiv mit den Details des x86_64-Systems und den verwendeten ABI-Konventionen auseinandersetzt, wird deutlich bessere und präzisere Analysen erzielen. Wer sich in den Themenbereich einarbeitet, wird feststellen, dass Expertenwissen aus den Bereichen Compilerbau, Betriebssysteme und Assemblersprachen notwendig ist.
Doch die Mühe lohnt sich, um das volle Potential der gesammelten Maschinenebenen-Daten auszuschöpfen und neue Wege in der Codeanalyse zu beschreiten.