In der heutigen datengetriebenen Welt sind Unternehmen zunehmend auf effiziente und skalierbare Datenarchitekturen angewiesen, um ihre riesigen Datenmengen zu verwalten und zu analysieren. Eine der vielversprechendsten Entwicklungen ist die sogenannte Lakehouse-Architektur, die die Flexibilität von Data Lakes mit den strukturierten Vorteilen traditioneller Data Warehouses kombiniert. Das DuckLake Manifesto stellt hierbei eine richtungsweisende Neuentwicklung dar, die das Konzept des Lakehouses grundlegend überdenkt und das Potenzial von SQL auf eine ganz neue Ebene hebt. DuckLake verfolgt den ambitionierten Ansatz, die Komplexität vieler bestehender Lakehouse-Formate zu reduzieren, indem es sämtliche Metadaten in einer herkömmlichen SQL-Datenbank verwaltet, anstatt auf komplexe, dateibasierte Systeme zu setzen. Die eigentlichen Daten werden weiterhin in offenen Formaten wie Parquet auf völlig skalierbarem Blob-Speicher abgelegt.
Dieses Design schafft eine verlässliche und performante Lösung, die gleichzeitig die Verwaltung deutlich vereinfacht. Dabei greift DuckLake auf bewährte Prinzipien zurück, die bereits bei etablierten Systemen wie Google BigQuery und Snowflake Einzug gehalten haben, setzt jedoch konsequent auf Offenheit und Portabilität. Im Kern der Lakehouse-Architektur steht die Trennung von Speicher und Rechenleistung, ein Konzept, das sich in den letzten Jahren als überaus effektiv erwiesen hat. Speicherressourcen können kosteneffizient skaliert werden, ohne dass die Rechenkapazitäten zwangsläufig mitwachsen müssen. Gleichzeitig verhindern offene Dateiformate wie Parquet Vendor-Lock-in und ermöglichen einfache Integration und Teilen von Daten über verschiedene Plattformen hinweg.
Doch diese Offenheit bringt auch Herausforderungen mit sich: Während einfache Datenanhänge über das bloße Hinzufügen von Dateien in einem Verzeichnis realisiert werden konnten, waren komplexere Operationen wie Updates, Deletes oder gar Transaktionen bisher schwer umsetzbar und oft fehleranfällig. Hier setzen Formate wie Apache Iceberg und Delta Lake an, die als erste ernsthafte Versuche gelten, Datenänderungen innerhalb offener Speicherformate zu strukturieren und Transaktionsfähigkeit zu ermöglichen. Iceberg etwa implementiert umfangreiche JSON- und Avro-basierte Metadatenstrukturen, um die Historie von Parquet-Dateien und deren Versionsstände nachzuhalten. Doch diese Lösungen stoßen schnell an Grenzen, wenn es um atomare Konsistenz, Multi-Table-Management oder mögliche Schwankungen der Konsistenz bei Cloud-basierten Blob-Stores geht. Deshalb wurde in der Branche oft eine zusätzliche Katalogschicht eingeführt, die als Bindeglied zwischen den verteilten Daten und den Applikationen wirkt.
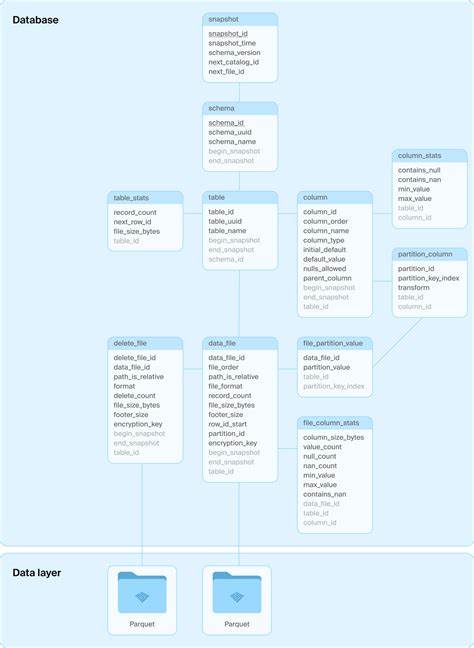
Diese Kataloge setzen wiederum auf relationale Datenbanken, um Konsistenz und Transaktionssicherheit zu gewährleisten. Genau hier setzt DuckLake an und hinterfragt den ursprünglichen Verzicht auf Datenbanken im Lakehouse-Ökosystem. Anstatt lediglich eine Datenbank für die Katalogverwaltung zu nutzen, verlagert DuckLake sämtliches Metadatenmanagement in ein leistungsfähiges, transaktionales SQL-Datenbanksystem. Dieses umfasst sowohl die Verwaltung von Tabellenschemata als auch sämtliche Informationen über die enthaltenen Datenfiles, ihre Statistiken und Versionsstände. Durch diese klare Rollenverteilung profitiert DuckLake von den bewährten Eigenschaften relationaler Datenbanken, beispielsweise ACID-Transaktionen, Primärschlüsseln und referenzieller Integrität – was sich positiv auf Zuverlässigkeit und Performance auswirkt.
Ein zentraler Vorteil besteht darin, dass die zugrundeliegende SQL-Datenbank weitgehend austauschbar ist. Ob PostgreSQL, Spanner, FoundationDB oder DuckDB selbst, alle können zur Metadatenverwaltung eingesetzt werden, solange sie ACID-Konformität und Standard-SQL unterstützen. Das macht DuckLake besonders flexibel und kompatibel mit bereits existierenden IT-Infrastrukturen. Darüber hinaus ist die DuckLake-Schema-Struktur bewusst einfach gehalten, um mögliche Integrationen zu erleichtern und den Einstieg zu erleichtern. Das Vorgehen bei Änderungen an den Daten ist bei DuckLake elegant und performant gelöst.
Neue Daten werden als unveränderliche Parquet-Dateien in den Blob-Speicher geschrieben – die Speicherung der eigentlichen Daten bleibt also stabil und optimiert für Skalierbarkeit und Kompatibilität. Änderungen am Inhalt oder der Struktur werden dann in einer einzigen, atomaren SQL-Transaktion in der Metadatenbank abgebildet. Dabei werden alle betroffenen Tabellen, Statistiken und Snapshots konsistent aktualisiert. Selbst kleine Änderungen, die sonst in anderen Formaten zu vielen kleinen Dateien und umständlichen Cleanup- und Kompressionsprozessen führen würden, können optional direkt in der Datenbank selbst gespeichert werden. Dadurch ergeben sich signifikante Vorteile hinsichtlich Schreibgeschwindigkeit, Systemstabilität und Wartbarkeit.
Ein weiteres zentrales Thema ist die Skalierbarkeit. DuckLake trennt Storage, Compute und Metadatenverwaltung klar voneinander. Das sorgt für eine Flexibilität, die von lokalen Entwicklungsumgebungen bis hin zu riesigen Cloud-Umgebungen mit tausenden von Knoten reicht. Während der Blob-Storage praktisch unbegrenzt skaliert werden kann und die Rechenleistung je nach Bedarf flexibel hinzugefügt wird, benötigt die Metadaten-Datenbank aufgrund der überschaubaren Anzahl an Operationen nicht dieselbe Skalierung wie der Datenspeicher selbst. Selbst ein traditioneller SQL-Server wie PostgreSQL kann so mehrere hundert Terabyte an Metadaten verwalten und tausende Commit-Operationen pro Sekunde verarbeiten.
Der Performancevorteil von DuckLake liegt zudem darin, dass Metadatenabfragen nur einen einzigen Datenbankzugriff erfordern. Dies reduziert Latenzen erheblich, da oft mehrere Aufrufe und Anfragen notwendig sind, um bei konkurrierenden Formaten ein vollständiges Bild der aktuellen Tabellensituation zu erhalten. Die Folge sind weniger Ausfälle, weniger Wartezeiten und eine insgesamt höhere Verfügbarkeit der Daten. DuckLake präsentiert auch eine beeindruckende Funktionalitätsvielfalt, die weit über das hinausgeht, was traditionelle Lakehouse-Formate bieten. Volle ACID-Transaktionen über mehrere Tabellen und Schemata hinweg gehören ebenso zum Standard wie komplexe Datenstrukturen mit geschachtelten Typen.
Die Unterstützung für schema-basierte Zeitreisen und Rollbacks erlaubt es, Tabellenzustände zu historischen Zeitpunkten abzubilden und auf Abruf zu analysieren. SQL-Views bieten die Möglichkeit, abstrahierte Datenansichten zu schaffen, während versteckte Partitionierung und statistische Pruning-Mechanismen für eine höchst effiziente Datenabfrage sorgen. Auch der Umgang mit Datenkompression und Datenverschlüsselung ist innovativ gelöst. DuckLake benötigt erheblich weniger aufwendige Komprimierungsprozesse, was den Verwaltungsaufwand weiter reduziert und die System Performance steigert. Verschlüsselung wird optional auf Dateiebene angeboten und die Schlüsselverwaltung liegt ebenfalls in der Datenbank, was sichere und moderne Anforderungen an Datenschutz und Compliance erfüllt.
Nicht zuletzt erlaubt DuckLake dank seiner Kompatibilität mit Apache Iceberg einen sanften Umstieg für Organisationen, die bereits auf Iceberg setzen und von den Vorteilen einer SQL-zentrierten Metadatenverwaltung profitieren möchten. Das reduziert den Migrationsaufwand erheblich und erleichtert die Integration in bestehende Data-Lake-Infrastrukturen. Die Kombination aus der Leistungsfähigkeit von SQL-Datenbanken und der Flexibilität offener Speicherformate macht DuckLake zu einer wegweisenden Plattform für die moderne Datenverwaltung. Unternehmen erhalten eine stabile, skalierbare und einfach zu handhabende Lösung, die sowohl in kleinen als auch in sehr großen Umgebungen funktioniert – von der Entwicklung auf dem Laptop bis hin zum Betrieb in der Cloud auf tausenden von Compute-Knoten. Insgesamt zeigt das DuckLake Manifesto, dass die nächste Generation von Lakehouses auf bewährten Standards aufbauen kann, diese jedoch mit innovativen Ideen und neuem Design erweitert werden müssen, um den steigenden Anforderungen der Datenwelt gerecht zu werden.
Dabei ist vor allem die Rückbesinnung auf relationale SQL-Datenbanken als Herzstück für Metadatenverwaltung ein wichtiger Schritt, der das Zusammenspiel von Datenspeicherung, Verarbeitung und Verwaltung erheblich vereinfacht und beschleunigt. Die Veröffentlichung von DuckLake v0.1 als Open-Source-Implementierung im DuckDB-Ökosystem zeigt, dass diese Vision längst nicht nur Theorie ist, sondern bereits praktisch angewendet und getestet wird. Die Community erhält damit ein Werkzeug an die Hand, das den aktuellen Herausforderungen im Datenmanagement souverän begegnet und zugleich offen für künftige Erweiterungen und Anwendungsfälle bleibt. Wer im Bereich Datenmanagement nach einer flexiblen, leistungsstarken und zukunftssicheren Lösung sucht, kommt an DuckLake kaum vorbei.
Es verkörpert den Geist moderner Datenarchitekturen, die Einfachheit, Geschwindigkeit und Skalierbarkeit auf einzigartige Weise vereinen. Die Diskussion über das „Was ist ein Lakehouse“ erhält mit DuckLake eine neue, klare Antwort – einen SQL-zentrierten Ansatz, der die Messlatte für kommende Datenmanagementsysteme nachhaltig erhöht.