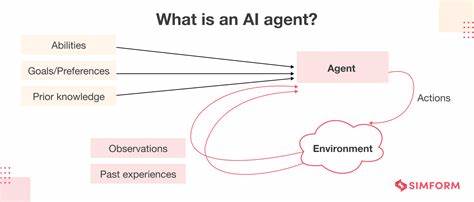
Die Entwicklung von KI-Agenten, die auf großen Sprachmodellen basieren, hat in den letzten Jahren enorme Fortschritte gemacht. Doch je mehr diese Systeme in der Praxis eingesetzt werden, desto deutlicher treten Herausforderungen zutage, die sowohl die Zuverlässigkeit als auch die Effizienz dieser Agenten beeinflussen. Zwei zentrale Probleme dominieren derzeit die Diskussion: Wie gestaltet man die Übergabe von Kontext beziehungsweise das Teilen von Informationen zwischen Agenten und über die Zeit hinweg am besten? Und wie schafft man es, Prompts so zu formulieren, dass die KI das gewünschte Verhalten zeigt, ohne dass die Eingaben dabei zu lang, kompliziert oder fehleranfällig werden? Der erste Aspekt, das sogenannte Kontextsharing, spielt eine Schlüsselrolle bei der Koordination zwischen mehreren Modulen und bei der Bewahrung von Informationen über längere Interaktionen. KI-Agenten müssen nicht nur in der Lage sein, den aktuellen Input zu verarbeiten, sondern auch frühere Ergebnisse und den bisherigen Gesprächsverlauf zu berücksichtigen. Das führt unweigerlich dazu, dass große Mengen an Daten gespeichert, organisiert und an das Modell zurückgegeben werden müssen.
Problematisch wird es, wenn der verfügbare Kontext durch das Token-Limit der verwendeten Sprachmodelle begrenzt wird. Entwickler stehen vor der Herausforderung, relevante Informationen auszuwählen, um den Speicherbedarf zu begrenzen, ohne dass wichtige Details verloren gehen. Dies sorgt einerseits für erhöhte Komplexität bei der Datenverwaltung und andererseits für steigende Kosten, da jeder Tokenverbrauch mit direktem Aufwand verbunden ist. Neben der technischen Hürde des Speicherns und Weiterreichens von Kontext stellt Kontextsharing auch eine koordinative Herausforderung dar. Wenn mehrere Agenten miteinander kommunizieren, wird die Synchronisation oft schwierig.
Es ist notwendig, einen konsistenten Status zu bewahren, welcher nicht nur korrekte Informationen liefert, sondern auch zur richtigen Zeit aktualisiert wird. Viele Entwickler vergleichen dieses Problem mit der Bewältigung eines eigenen, oft fragilen Speichersystems außerhalb des eigentlichen KI-Modells, welches schwer an die Denkweise der künstlichen Intelligenz anzupassen ist. Entweder werden die Daten komplett neu an das Modell weitergegeben, was aber zu Verzögerungen und erhöhten Kosten führt, oder man setzt auf externe Speichersysteme, die jedoch oft mit Inkonsistenzen und Wartungsproblemen zu kämpfen haben. Zum anderen ist das Prompting ein nicht minder wichtiges Problem. Prompts sind die unmittelbaren Eingaben, mit denen Nutzer oder Entwickler die KI anweisen, bestimmte Aufgaben auszuführen.
Die Kunst des Promptings liegt darin, diese Eingaben präzise und effektiv so formulieren, dass die KI das gewünschte Verhalten zeigt. Gerade weil große Sprachmodelle so komplex sind, reagieren sie auf kleine Änderungen in der Formulierung oft mit stark unterschiedlichen Ergebnissen. Dieses Phänomen macht das Prompting zu einer Wissenschaft für sich. Entwickler müssen viel Zeit investieren, um Prompts zu optimieren, ohne dabei den Eingabebereich zu sprengen. Zu lange Prompts kosten Ressourcen und können die Wahrscheinlichkeit von Fehlern erhöhen.
Die Fragilität von Prompts führt dazu, dass Entwickler ständig experimentieren und justieren müssen. Kleinigkeiten können dazu führen, dass eine KI plötzlich nicht mehr versteht, was sie tun soll oder Ergebnisse liefert, die nicht den Erwartungen entsprechen. Eine der Herausforderungen ist somit, Prompts so zu gestalten, dass sie robust gegen Schwankungen sind und gut generalisieren. Dazu kommt, dass der Mangel an hochwertigen gemeinschaftlich verfügbar gemachten Prompts viele Entwickler zwingt, den Großteil ihrer Arbeit selbst zu erledigen, was die Entwicklungszeit erhöht. Obwohl Prompting grundsätzlich deterministisch erscheint – man verändert den Input und beobachtet die Output-Veränderung – bietet das Kontextsharing ein komplexeres Bild, das schwerer zu kontrollieren ist.
Der Grund dafür liegt darin, dass Kontext nicht nur aktuelle Informationen liefert, sondern auch den Zustand des Systems abbildet und somit eine Grundlage für fortlaufende Dialoge und Entscheidungen bildet. Wenn dieser Kontext nicht richtig geteilt oder aktualisiert wird, kann die KI leicht inkonsistente oder unerwartete Ergebnisse produzieren. Aus wirtschaftlicher Sicht ist sowohl das Kontextsharing als auch das Prompting durch den Tokenverbrauch begrenzt. Jedes Token, das an das Modell gesendet wird, verursacht Kosten. Gerade in skalierenden Anwendungen, in denen viele Agenten miteinander kommunizieren und viel Kontext übergeben werden muss, können die Kosten schnell explodieren.
Daher suchen Entwickler nach Strategien, um den Kontext effizient zu komprimieren und die Prompts so zu gestalten, dass möglichst wenig relevant sind, aber dennoch klare Anweisungen enthalten. Dieses Spannungsfeld zwischen Kosten, Effektivität und Robustheit prägt die Arbeit mit KI-Agenten maßgeblich. Einige Lösungsansätze versuchen, das Schichtenthema des Kontextsharings mit externen Wissensspeichern oder Speicherungslösungen zu adressieren, welche die Hauptlast der Informationen verwalten und nur relevante Ausschnitte an die KI übergeben. Andere setzen auf fortgeschrittene Prompt-Engineering-Techniken, die nicht nur die Aufforderungen verbessern, sondern auch die Art, wie KI-Modell-Interaktionen strukturiert werden. Dabei geht es zum Beispiel darum, Aktionen oder Zwischenschritte außerhalb des Modells durchzuführen und somit den Kontext effektiver zu verwalten.
Grundsätzlich lässt sich sagen, dass die Herausforderung des Kontextsharings derzeit als die tiefergehende und komplexere betrachtet wird. Gerade in Umgebungen, in denen mehrere Agenten agieren und über längere Zeiträume Informationen austauschen müssen, wird die Problematik besonders sichtbar. Hingegen ist das Prompting zwar ärgerlich und kann die Zuverlässigkeit der Agenten beeinträchtigen, jedoch ist es häufig leichter durch Versuch und Irrtum sowie bessere Tools handhabbar. Dennoch sind beide Aspekte eng miteinander verknüpft und müssen in der Praxis immer zusammen optimiert werden. Fortschritte in der Forschung und Entwicklung bei Speichertechniken, effizienter Kontextkompression und robustem Prompting sind unerlässlich, um die nächste Generation von KI-Agenten effizient und nutzerfreundlich zu gestalten.
Entwickler, Unternehmen und Forschende sind daher gut beraten, in beiden Bereichen Investitionen zu tätigen, um die Systeme skalierbar, kosteneffizient und zuverlässig zu machen. Die Zukunft der KI-Agenten wird maßgeblich davon abhängen, wie gut diese Kernprobleme adressiert und gelöst werden.