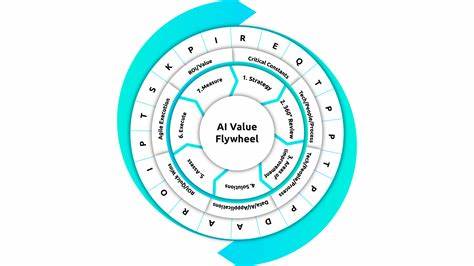
Die rasante Entwicklung von Künstlicher Intelligenz (KI) stellt Entwickler und Unternehmen vor besondere Herausforderungen. Die Frage, wie man KI-Features kontinuierlich verbessern und validieren kann, ist dabei zentral. Hier setzt das Konzept des AI Eval Flywheel an – ein systematischer Kreislauf, der Scoring-Methoden, den Einsatz von Datensätzen, die Nutzung in der Produktion und schnelle Iterationen miteinander verbindet und so eine stetige Optimierung von KI-Anwendungen ermöglicht. Dieses Konzept wurde auf renommierten Veranstaltungen wie dem AI Engineer World’s Fair 2025 in San Francisco intensiv diskutiert und findet bereits Anwendung bei großen Unternehmen wie Google, Notion, Zapier und Vercel. Ohne systematische Evaluation arbeiten Teams häufig nach „Gefühl“ – sie testen ein KI-Feature mit einigen Eingaben, bewerten die Antworten ad hoc und entscheiden dann über die Einsatzbereitschaft.
Dieses Vorgehen stößt schnell an Grenzen, sobald neue Modelle eingeführt oder komplexe Randfälle betrachtet werden müssen. KI-Systeme agieren oft nicht-deterministisch, das heißt ihre Antworten variieren auch bei gleichen Eingaben. Das macht es noch komplexer, Änderungen nachvollziehbar und einschätzbar zu gestalten. Ein strukturierter Ansatz ist daher essentiell, wenn es darum geht, Qualität kontinuierlich zu messen und zu verbessern. Das Kernstück des AI Eval Flywheel bildet die systematische Bewertung der Ergebnisse, die sogenannte „Eval“-Phase.
Dabei unterscheidet man zwischen dem umfassenden Prozess (Big Evals) und dem konkreten Schritt des Scorings (Little E). Beim Scoring wird jede Ausgabe des KI-Features anhand verschiedener Kriterien oder Signale bewertet und mit einer Punktzahl versehen. So kann beispielsweise die Qualität einer geschriebenen Antwort, ihre Relevanz oder Einhaltung bestimmter Formatvorgaben ermittelt werden. Die Bewertung erfolgt häufig als gewichtete Summe aus mehreren einzelnen Signalen, um eine aussagekräftige Gesamtnote zu erhalten. Unternehmen wie Google verfolgen diese Prinzipien bereits seit Jahren im Bereich Suchmaschinenoptimierung.
Dort bewertet man Suchergebnisse anhand von hunderten verschiedenen Signalen, darunter Ladegeschwindigkeit, Qualität der Backlinks oder inhaltliche Genauigkeit. Diese Methoden lassen sich problemlos auf KI-Features übertragen – man muss lediglich passende Signale definieren, die den Qualitätsanspruch widerspiegeln. Neben technischen Messgrößen, die sich durch Code verifizieren lassen, spielen bei KI auch weiche Bewertungen eine Rolle. So werden natürliche Sprachqualität oder der Stil der Antworten oftmals durch den Einsatz von großen Sprachmodellen (LLMs) als Bewertungsinstanz beurteilt. Der richtige Mix aus automatisierten Bewertungen und menschlicher Expertise ist entscheidend.
Automatisierte Scorer können durch vorab definierte Regeln oder LLM-basierte Prompts schnelle und reproduzierbare Bewertungen liefern. Trotzdem ist es unabdingbar, die Qualität dieser Scorer regelmäßig zu überprüfen, indem man stichprobenartige menschliche Bewertungen heranzieht. Nur so lässt sich sicherstellen, dass die automatischen Bewertungen valide sind und nach Bedarf justiert werden können. Eine weitere wichtige Komponente sind gut strukturierte Datensätze als Inputs für die KI-Tests. Diese Datensätze können sorgfältig kuratiert sein oder synthetisch mithilfe von LLMs generiert werden.
Kuratierte Datensätze sind besonders wertvoll, da sie typische Anwendungsfälle sowie spezielle Edge Cases abdecken, also schwierige oder seltene Szenarien, die besonders herausfordernd für das KI-Feature sind. Synthetische Datensätze hingegen erlauben eine skalierbare Ergänzung und Simulation verschiedenster Input-Varianten, um die Leistungsfähigkeit der KI unter verschiedenen Bedingungen zu prüfen. Ergänzend zur Offline-Evaluation, die im Entwicklungsprozess mit festen Datensätzen stattfindet, wird im modernen AI Eval Flywheel ein starker Fokus auf Online-Evaluation gelegt. Dabei werden reale Nutzereingaben aus der Produktion direkt ausgewertet, um ein realistisches und aktuelles Bild über die Performance des Features zu erhalten. Online-Evals bieten den Vorteil, dass sie eine Art Live-Feedbackloop schaffen und es ermöglichen, Regressionen oder neue problematische Anwendungsfälle frühzeitig zu erkennen.
Darüber hinaus liefern Online-Evaluationen weitere wertvolle Signale basierend auf Nutzerverhalten. Explizites Feedback, wie Thumbs-up oder Thumbs-down Bewertungen, geben Hinweise auf die Zufriedenheit mit den generierten Inhalten. Implizite Signale, etwa ob eine Antwort gespeichert, kopiert oder geteilt wird, erlauben Rückschlüsse darüber, wie nützlich und relevant die KI-Antworten tatsächlich sind. Solche Signale sind essenziell, um Eval-Methoden weiter zu verfeinern und das System noch besser an die Bedürfnisse der Nutzer anzupassen. Aus der Kombination von Scoring, strukturierten Datensätzen sowie produktionsbasiertem Feedback entsteht ein sich selbst verstärkender Kreislauf.
Jede Iteration bietet die Möglichkeit, den Datensatz um neue, realistische Eingaben zu erweitern, die Bewertungsmetriken zu verbessern und dadurch die KI kontinuierlich auf hohem Niveau zu halten. Je mehr Nutzer das Feature verwenden, desto besser und schneller können Schwachstellen identifiziert und behoben werden. Somit wirkt sich der Flywheel-Effekt direkt auf die Qualität und Robustheit der KI-Features aus. Ein weiterer wesentlicher Erfolgsfaktor für den AI Eval Flywheel sind sogenannte „Playgrounds“. Diese Entwicklungsumgebungen erlauben es, neue Modelle oder Änderungen der Prompts schnell und ohne umfangreiche Codeanpassungen zu testen.
Solche Tools unterstützen die schnelle Durchlaufzeit der Evaluationszyklen sowie eine flexible Anpassung an neue Anforderungen. Plattformen wie Braintrust bieten bereits fertige Lösungen für die Erstellung von Scorern und das Management von Evaluationsprozessen, wodurch Teams erhebliche Zeit und Ressourcen sparen können. Abschließend wird deutlich, dass die Zukunft erfolgreicher KI-Features maßgeblich von einem strukturierten und iterativen Evaluationsprozess abhängt. Nur durch eine systematische Analyse der Outputs, eine kontrollierte Aufbereitung der Inputs und eine stetige Einbindung von Nutzerdaten aus der Produktion kann ein KI-Feature nachhaltig und zuverlässig optimiert werden. Der AI Eval Flywheel stellt hier ein leistungsfähiges Rahmenwerk bereit, um diesen kontinuierlichen Verbesserungsprozess zu gestalten.
Um praxisnahe Einblicke und Best Practices zu vertiefen, stehen mehrere Ressourcen zur Verfügung. Kurse wie „AI Evals for Engineers & PMs“ vermitteln fundiertes Wissen zur Konzeption und Umsetzung von Evaluationen. Ebenso bieten Expertenblogs und Vortragssammlungen, etwa von Eugene Yan oder den Sessions beim AI Engineer World’s Fair, wertvolle Impulse für die tägliche Arbeit. Unternehmen, die bereits auf den AI Eval Flywheel setzen, zeigen, wie man effektives Scoring, intelligente Datensätze, Echtzeit-Feedback und agile Experimentation in einem einzigen Kreislauf zusammenführt und somit eine nachhaltige Qualitätssicherung in der KI-Entwicklung etabliert. Die konsequente Anwendung des AI Eval Flywheel bietet damit nicht nur einen klaren Wettbewerbsvorteil, sondern ist auch eine Voraussetzung dafür, den komplexen Anforderungen moderner KI-Systeme gerecht zu werden.
Von der Startup-Phase bis zur Skalierung ermöglicht dieses Framework eine transparente, reproduzierbare und auf den Nutzerfokus ausgerichtete Produktentwicklung, die dem hohen Tempo der KI-Innovation gerecht wird.