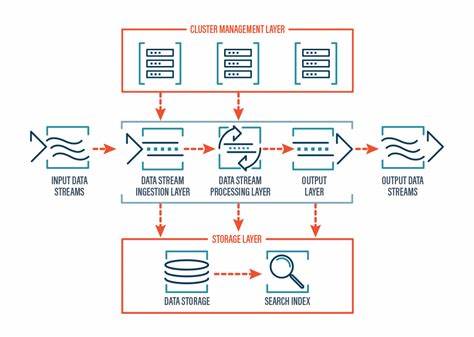
In der heutigen datengetriebenen Welt gewinnt die Fähigkeit, große Mengen an Daten in Echtzeit zu generieren und zu verarbeiten, immer mehr an Bedeutung. Besonders in Bereichen wie Big Data, Machine Learning, Echtzeit-Überwachung und Softwareentwicklung sind realistische Streaming-Daten essenziell, um Systeme unter realen Bedingungen zu testen und Anwendungen effektiv zu trainieren. Hier setzt GlassGen an, ein innovativer Streaming-Datengenerator, der in Python entwickelt wurde und eine flexible, benutzerfreundliche Lösung für die Generierung synthetischer Datenströme bietet. GlassGen stellt Entwicklern eine umfangreiche und vielseitige Plattform zur Verfügung, die maßgeschneiderte synthetische Daten basierend auf vordefinierten oder benutzerdefinierten Schemata erzeugt. Anders als einfache Datenmocks ermöglicht GlassGen dynamische und konfigurierbare Datenströme, die in Echtzeit bereitgestellt werden können und sich somit optimal für komplexe Anwendungsszenarien eignen.
Dabei lässt sich die Erzeugungsgeschwindigkeit individuell einstellen, was eine präzise Simulation von unterschiedlichen Datenlasten erlaubt. Ein herausragendes Merkmal von GlassGen ist die Unterstützung zahlreicher Ausgabeformate und Schnittstellen. Die generierten Daten können in CSV-Dateien gespeichert, direkt an Kafka-Themen gesendet oder per Webhook an definierte HTTP-Endpunkte übertragen werden. Auch eine Schnittstelle zum iterativen Abruf der Daten ist vorhanden, was insbesondere bei Integration in Python-Anwendungen Vorteile bietet. Dieses breite Spektrum an Ausgabemöglichkeiten macht GlassGen sehr anschlussfähig für verschiedenste Data-Pipelines und Testumgebungen.
Für Unternehmen, die auf ereignisbasierte Architekturen oder Streaming-Analytics setzen, ist die Kafka-Integration besonders interessant. GlassGen nutzt das bewährte Python-Paket confluent_kafka und unterstützt sowohl selbst gehostete Kafka-Cluster als auch Cloud-Varianten wie Confluent Cloud oder Aiven. Dadurch ist eine einfache Einbindung in bestehende Systemlandschaften gewährleistet und die Daten können nahtlos in Echtzeit weiterverarbeitet werden. Neben den klassischen Datentypen bietet GlassGen eine beeindruckende Auswahl an Schema-Generatoren, die diverse reale Datenmodelle abdecken. Von einfachen Strings, Ganzzahlen und Zeitstempeln über persönliche Informationen wie Namen, E-Mail-Adressen und Telefonnummern bis hin zu ortsbezogenen Daten und Geschäftsinformationen steht eine umfangreiche Bibliothek bereit.
Auch UUIDs, boolesche Werte, Preise, URLs oder IP-Adressen lassen sich problemlos generieren. Diese Vielfalt ermöglicht es, realitätsnahe, komplexe Datensätze zu erstellen, die für unterschiedliche Test- und Entwicklungszwecke genutzt werden können. Das Hinzufügen von benutzerdefinierten Schema-Definitionen ist unkompliziert und erlaubt es Entwicklern, eigene Datentypen oder Felder nach Bedarf zu implementieren. Zudem existieren vorgefertigte Schemata wie beispielsweise ein UserSchema, das typische Nutzerinformationen abbildet und sofort einsatzbereit ist. Dies spart Zeit bei der Konfiguration und bietet gleichzeitig Flexibilität für individuelle Anforderungen.
Ein weiteres bemerkenswertes Feature ist die Möglichkeit, kontrollierte Ereignisduplikationen zu erzeugen, um realistische Anwendungsfälle nachzubilden, in denen identische Events mehrfach auftauchen können. Dies ist zum Beispiel hilfreich bei der Simulation von Netzwerkausfällen, verteilten Systemen oder Fehlerszenarien. GlassGen ermöglicht es, den Anteil duplizierter Events sowie das zugehörige Zeitfenster und das Duplikationskriterium wie etwa eine E-Mail-Adresse als Schlüssel festzulegen. So lassen sich Szenarien modellieren, die eine besonders hohe Nähe zur Realität aufweisen. Die Nutzung von GlassGen gestaltet sich dank der sowohl als CLI als auch als Python Software Development Kit (SDK) verfügbaren Schnittstellen besonders anwenderfreundlich.
Entwickler können den Generator mit wenigen Zeilen Code in eigene Skripte integrieren oder ihn direkt über eine Konfigurationsdatei steuern. Diese Konfiguration erlaubt die Spezifikation von Schema, Ausgabeziel, Generierungsgeschwindigkeit und der Gesamtzahl der zu erzeugenden Events. So ist eine schnelle Anpassung an unterschiedliche Szenarien und Testzyklen möglich. Die offene Architektur von GlassGen unterstützt zudem die Erstellung eigener Ausgabe-Sink-Module. Indem man die Basisklasse für Sinks erweitert, kann man beliebige neue Ausgabekanäle definieren, die genau auf die eigenen Bedürfnisse zugeschnitten sind.
Dies macht GlassGen zu einem sehr flexiblen Werkzeug, das mit den Anforderungen von modernen Daten-Ökosystemen mitwachsen kann. Da GlassGen in Python geschrieben wurde, profitiert es von der großen Beliebtheit und dem breiten Ökosystem dieser Programmiersprache. Es ist einfach installierbar via pip, lässt sich in virtuelle Umgebungen einbetten und ist dank moderner Softwareentwicklungsmethoden stabil und erweiterbar gestaltet. Das Projekt wird aktiv gepflegt und verfügt über eine klare Versionspolitik und Release-Management, was langfristige Einsatzsicherheit schafft. Die Möglichkeit, Daten mit hoher Geschwindigkeit zu erzeugen, macht GlassGen auch für Szenarien interessant, in denen Lasttests oder Performance-Analysen von Datenverarbeitungssystemen durchgeführt werden müssen.
Durch die konfigurierbare Rate („records per second“) lässt sich die Testbelastung präzise steuern. Dies unterstützt Entwickler und Operations-Teams dabei, Engpässe frühzeitig zu entdecken und Systeme gezielt zu optimieren. GlassGen kann somit als unverzichtbares Werkzeug für Data Engineers, Softwareentwickler und Forscher betrachtet werden, die realistische und skalierbare Testdaten benötigen. Insbesondere bei Anwendungen, wo Echtzeitdatenströme zum Einsatz kommen, bietet der Generator die Möglichkeit, komplexe Datenflüsse zu simulieren, ohne auf teure oder schwer zugängliche Realdaten angewiesen zu sein. Zusammenfassend bietet GlassGen eine leistungsfähige und vielseitige Lösung zur Echtzeit-Generierung von Streaming-Daten.
Die Kombination aus vielfältigen Schema-Generatoren, verschiedenen Ausgabemöglichkeiten, einfacher Konfiguration und Erweiterbarkeit macht das Tool zu einer attraktiven Wahl für verschiedenste Projekte im Bereich Daten-Engineering und Software-Entwicklung. Die Fähigkeit, realistische Duplikationen einzubauen und die hohe Performance eröffnen zudem neue Möglichkeiten für Simulationen unter realen Bedingungen. Wer auf der Suche nach einer modernen, flexiblen und quelloffenen Lösung für synthetische Streaming-Daten ist, findet in GlassGen ein wertvolles Werkzeug, das sich schnell implementieren lässt und in der Praxis durch Zuverlässigkeit und Vielfalt überzeugt. Dank der aktiven Community und kontinuierlichen Entwicklung wird das Projekt auch zukünftig eine wichtige Rolle im Bereich der Datenproduktion spielen und das Arbeiten mit Big Data und Echtzeitdatenströmen maßgeblich erleichtern.








