Die Organisation und Planung von Veranstaltungen ist eine anspruchsvolle Aufgabe, die in vielen Bereichen des privaten und beruflichen Lebens von großer Bedeutung ist. Traditionell wird die Terminplanung oft durch spezialisierte Software oder manuelle Methoden erledigt, die auf deterministischen Algorithmen basieren. Doch mit dem rasanten Fortschritt im Bereich der Künstlichen Intelligenz und insbesondere der leistungsstarken Sprachmodelle eröffnen sich neue Möglichkeiten. Ein faszinierendes Experiment zeigt, wie ein Sprachmodell mithilfe der sogenannten Group Relative Policy Optimization, kurz GRPO, darauf trainiert wurde, eigenständig effiziente Zeitpläne zu erstellen. Dabei geht es darum, aus einer Liste von Events und gegebenen Prioritäten eine optimale Terminübersicht zu generieren, die die Bedeutung einzelner Termine berücksichtigt und die Gesamtdauer der wichtigsten Events maximiert.
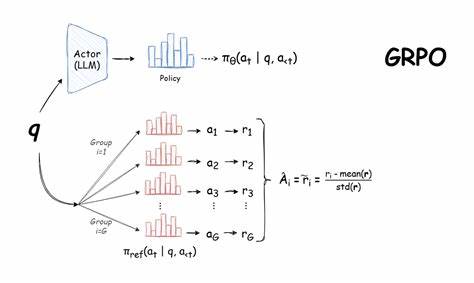
GRPO markiert einen innovativen Ansatz im Bereich des Reinforcement Learning für Sprachmodelle. Anders als herkömmliche Methoden der finetuning-basierten Trainingsverfahren, bei denen Modelle anhand vorgegebener Zieltexte optimiert werden, erfolgt beim GRPO-Training eine Belohnungsorientierung. Das Modell lernt durch Interaktionen und Bewertungen seiner Vorschläge, ohne explizite Zielantworten zu sehen. Dies bedeutet, dass das Sprachmodell eigenständig Strategien entwickelt, um das definierte Belohnungskriterium – in diesem Fall die bestmögliche zeitliche Organisation der Events – zu maximieren. Dieser Prozess ist vergleichbar mit dem Lernen durch Erfahrungen, was in der Künstlichen Intelligenz als besonders zielgerichtete und nachhaltige Lernmethode gilt.
Die Idee, gerade die Eventplanung als Testumgebung für solch ein Lernverfahren auszuwählen, ist bemerkenswert. Während derartige Aufgaben technisch mit klassischen Verfahren gut lösbar sind, bietet der menschliche Kontext und die Komplexität bei Prioritäten eine Herausforderung, die herkömmliche Programme oft mit Einschränkungen stemmen. Ein Sprachmodell, das kontextbezogenes Verständnis und flexible Problemlösungen kombiniert, kann einen deutlichen Mehrwert bieten. Es ist in der Lage, nicht nur stur Zeiträume zusammenzufügen, sondern die Wichtigkeit einzelner Ereignisse mit einzubeziehen und mögliche Konflikte kreativ zu umgehen. Im konkreten Experiment wurde ein 7 Milliarden Parameter großes Sprachmodell als Basis gewählt.
Training und Tests zeigten, dass dieses Modell durch den GRPO-Ansatz in der Lage war, seine ursprüngliche Leistungsfähigkeit zu übertreffen und sogar ein größeres 14 Milliarden Parameter Modell zu schlagen. Die Belohnungsfunktion belohnte das Modell so, dass prioritär markierte Events mit einem Gewicht von zwei und reguläre Events mit einem Gewicht von eins versehen wurden. Die Aufgabe bestand darin, den Zeitplan aufzustellen, der die maximale gewichtete Gesamtdauer der eingebuchten Termine realisiert. Dies gewährleistet, dass wichtiger erscheinende Veranstaltungen den Vorrang bekommen, ohne dass die Leistung im Umgang mit weniger priorisierten Events darunter leidet. Ein wichtiger Aspekt bei der Trainingsphase war die Entwicklung eines angemessenen Belohnungssystems.
Dieses musste das Modell dazu anregen, Kollisionen zwischen Events zu vermeiden, also Überlappungen im Zeitplan strikt zu minimieren. Trotz positiver Fortschritte bleibt dieser Teil des Trainings eine Herausforderung. Das Modell neigt dazu, gelegentlich Überschneidungen zu übersehen, was aufzeigt, dass die Belohnungsfunktion noch optimiert werden kann. Die Gestaltung solcher Bedingungen ist ein bekanntes Problem im Reinforcement Learning und bedarf fortlaufender Anpassungen, um gewünschte Verhalten konsequent zu fördern. Der Datensatz zur Trainingsversorgung wurde speziell für dieses Projekt generiert.
Er umfasst verschiedene Event-Listen mit dazugehörigen Prioritäten, die das Modell mit unterschiedlichen Schwierigkeitsgraden konfrontieren. Diese Vielfalt zwingt das Sprachmodell, generalisierbare Strategien zu entwickeln, was im professionellen Umfeld von Vorteil ist, wo Termine selten einem einheitlichen Muster folgen. Zudem wurde das Training in mehreren Runden durchgeführt, um das Modell kontinuierlich zu verfeinern und unterschiedliche Belohnungskomponenten zu erproben. Die Softwarestruktur des Projektes ist gut organisiert: Von der Datenerzeugung über die Trainingsnotebooks bis hin zu Evaluationsskripten existieren einzelne Module, die den gesamten Entwicklungsprozess abdecken. Dies ermöglicht nicht nur nachvollziehbare Forschung, sondern auch praktische Nachnutzung.
Wer die Entwicklungsschritte versteht, kann mit eigenen Anpassungen experimentieren und so die Potentiale von Sprachmodellen in der Planungswelt weiter ausloten. Mehr noch als reine Leistungsdaten zeigt sich in diesem Projekt die Möglichkeit, Reinforcement Learning innovativ außerhalb der typischen Bildungsdomänen einzusetzen. Statt einfacher Rechenaufgaben oder logischer Spiele erfährt ein Sprachmodell hier eine „echte“ Problemstellung mit mehreren Zwischenschritten und Teillösungen. Dies entspricht mehr den Herausforderungen im Alltag und bringt die Vorteile von KI-Technologien näher an die praktische Anwendung. Die Ergebnisse ermutigen zu weiteren Forschungen.
Die einzigartige Kombination aus Reinforcement Learning und natürlichen Sprachverarbeitungsfähigkeiten bietet die Chance, komplexe Planungsprozesse mit dem intuitiven Verständnis und der Flexibilität von LLMs (Large Language Models) zu verbinden. Beispielsweise könnten zukünftige Systeme für Meeting-Organisation, Ressourcenverwaltung oder persönliche Kalenderassistenz auf solchen Konzepten beruhen und menschenähnliche Anpassungsfähigkeit zeigen. Zusammenfassend zeigt das Experiment mit einem GRPO-trainierten Sprachmodell, wie sich neuartige Lernmethoden und klassische Planungsthemen gewinnbringend kombinieren lassen. Der Schritt weg von superstarr vorgegebenen Lösungen hin zu eigenständig entwickelter Problemlösung markiert einen wichtigen Meilenstein für KI-Anwendungen im Terminmanagement. Obwohl noch Verbesserungspotential bei der Vermeidung von Terminüberschneidungen besteht, deutet der Erfolg bei der Priorisierung und Formatierung bereits auf das große Zukunftspotential solcher Systeme hin.
Dank der offenen Freigabe von Code, Daten und Analysen steht das Projekt anderen Forschern und Entwicklern offen und beflügelt die Kreativität weiterführender Innovationen. Abschließend ist der Ansatz, Sprachmodelle durch GRPO auf spezifische Planungsaufgaben hin zu trainieren, ein vielversprechender Weg, um die Grenzen künstlicher Intelligenz zu erweitern. Besonders im Kontext einer zunehmend vernetzten und effizienzorientierten Welt kommt solchen Entwicklungen eine große Bedeutung zu, welche künftig das Zusammenleben und Arbeiten prägen könnten.