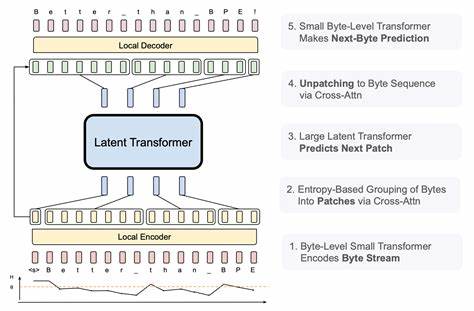
Die Entwicklung der großen Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren bahnbrechende Fortschritte gemacht. Klassisch basieren viele dieser Modelle auf Tokenisierung, bei der Text in vorab definierte Token zerlegt wird. Diese Token sind meist Wörter oder Wortbestandteile, die über ein festgelegtes Vokabular abgebildet werden. Der Byte Latent Transformer (BLT) bringt eine völlig neue Perspektive in die Sprachmodellierung, indem er auf Byte-Ebene arbeitet und die Daten nicht in statische Token, sondern in dynamisch segmentierte Patches zerlegt. Dieses innovative Konzept verspricht eine Effizienz- und Skalierungsexplosion sowie eine gesteigerte Robustheit der Modelle.
Der Kern der BLT-Architektur ist die sogenannte Patch-Segmentierung, die dynamisch anhand der Entropie des nächsten Bytes erfolgt. Während traditionelle Token-basierte Modelle immer dieselben, vorbestimmten Einheiten verarbeiten, passt BLT die Größe der Patches flexibel an die Komplexität der Daten an. Bei vorhersehbaren Textpassagen können längere Patches gebildet werden, was den Rechenaufwand erheblich senkt, während bei komplexen Stellen kürzere Patches und damit mehr Einsatz von Modellkapazität genutzt werden. Dieses Prinzip sorgt dafür, dass die Rechenressourcen effizienter genutzt und unnötige Berechnungen vermieden werden.Einer der größten Vorteile des Byte Latent Transformers liegt in seiner Fähigkeit, ohne ein festes Vokabular zu operieren.
Während Token-basierte Modelle auf ein vordefiniertes Token-Set angewiesen sind und bei unbekannten Wörtern oder seltenen Ausdrucksweisen an ihre Grenzen stoßen können, greift BLT direkt auf die Rohdaten zu – die Bytes – und umgeht so Problematiken bezüglich Out-of-Vocabulary (OOV). Das führt zu einer verbesserten Robustheit bei vielseitigen Eingaben, insbesondere bei mehrsprachigem Text oder bei seltenen Schreibweisen und Fachbegriffen.Skalierung spielt eine entscheidende Rolle in der Leistungsfähigkeit moderner KI-Systeme. Die Forschungsergebnisse des BLT zeigen erstmals eine kontrollierte FLOP-Skalierungsstudie, bei der Modelle bis zu 8 Milliarden Parameter und 4 Billionen Trainingsbytes erfolgreich trainiert wurden. Dabei konnte gezeigt werden, dass die Effizienz nicht nur erhalten bleibt, sondern sich bei steigendem Modell- und Patchumfang deutlich verbessert.
Das ist ein Meilenstein, da herkömmliche Byte-basierte Modelle bisher oft im Vergleich zu tokenisierten Varianten in Sachen Effizienz zurückblieben.Ein weiterer positiver Effekt der Patch-basierten Verarbeitung zeigt sich in der Verbesserung der generalisierenden Fähigkeiten der Modelle. Gerade bei komplexen Aufgaben wie logischem Denken, mehrstufigem Schlussfolgern oder der Verarbeitung langanhaltender Kontextinformationen erzielen BLT-Modelle signifikante Leistungszuwächse. Diese Fortschritte eröffnen spannende Perspektiven für Anwendungen im Bereich Forschungsliteratur, juristische Dokumente oder jede Domäne, in der langfristige Kontextbezüge entscheidend sind.Die erhöhte Effizienz wirkt sich nicht nur beim Training, sondern vor allem bei der Inferenz aus.
BLT kann bei fixierten Rechenkosten bessere Ergebnisse liefern als traditionelle tokenbasierte Systeme. Besonders in Produktionsumgebungen, in denen Reaktionszeit und Kosten eine zentrale Rolle spielen, ist das ein entscheidender Vorteil. Anwendungen wie Chatbots, Echtzeit-Übersetzung oder assistierende KI-Systeme profitieren dadurch von schnelleren Antworten und geringerem Energieverbrauch.Die Einführung der dynamischen Patch-Größen erweitert die Flexibilität und Anpassungsfähigkeit der Modelle signifikant. Während frühere Methoden stets auf fixe Eingabeeinheiten angewiesen waren, ermöglicht BLT den adaptiven Umgang mit Daten.
So passt sich die Modellarchitektur intelligent an die jeweilige Aufgabenstellung und Eingabelänge an, was in einer besseren Nutzung von Modellkapazität resultiert.Ein weiterer interessanter Aspekt ist die demokratisierende Wirkung der Byte-basierung. Tokenbasierte Modelle sind oft stark abhängig von der Qualität der Tokenisierung und deren Vokabulare, die vornehmlich für dominante Sprachen optimiert sind. BLT fördert durch seine einfache Byte-Level-Verarbeitung die Barrierefreiheit für unterrepräsentierte Sprachen und kann somit zur Förderung von Mehrsprachigkeit und Inklusion in KI-Systemen beitragen.Die Forschung hinter BLT ist ein gutes Beispiel für das Zusammenspiel von Theorie und praktischer Anwendung.
Durch den Fokus auf die Entropie als Maß für Datenkomplexität nutzt BLT ein informationstheoretisches Prinzip, um Modellkapazitäten intelligent zu allokieren. Dieses Konzept kann mögliche Anwendungen weit über NLP hinaus inspirieren, beispielsweise in Bereichen der Signalverarbeitung, Bildverarbeitung oder molekularen Datenanalyse, wo rohe Daten ebenfalls hinsichtlich ihrer Komplexität unterschiedlich behandelt werden könnten.Die Entstehung des Byte Latent Transformers ist nicht nur aus technologischer Sicht relevant, sondern setzt auch neue Maßstäbe für die Zukunft der KI-Forschung. Er zeigt, dass durch kreative Neuinterpretationen etablierter Paradigmen – wie etwa der Wechsel von char- oder token-basierten Repräsentationen zu patch-basierten – nachhaltige Fortschritte erzielt werden können. Die Kombination hoher Modellkapazität mit adaptiver Datenrepräsentation ist ein vielversprechender Weg, um die Leistungsgrenzen heutiger Systeme zu überwinden.