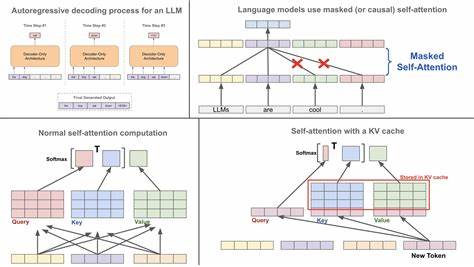
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) und Transformer-Architekturen hat die natürliche Sprachverarbeitung (Natural Language Processing, NLP) revolutioniert. Eine der zentralen Herausforderungen bleibt jedoch die effiziente Verarbeitung langer Textkontexte. Die quadratische Zeitkomplexität der traditionellen Selbstaufmerksamkeitsmechanismen führt bei wachsender Sequenzlänge zu massiven Rechenaufwänden und Speicherproblemen. Infolgedessen suchen Forscher weltweit nach innovativen Methoden, um lange Kontexte mit hoher Genauigkeit und akzeptabler Rechenzeit zu integrieren. Hier setzt CacheFormer an, ein neuartiger Ansatz, der von Prinzipien der Computerarchitektur wie Cache- und virtueller Speicher inspiriert ist.
CacheFormer revolutioniert die Aufmerksamkeitstechnologie, indem es das Konzept segmentbasierten Cachings mit hohen Aufmerksamkeitsbewertungen nutzt, um relevante Informationsbereiche in unkomprimierter Form dynamisch und effizient handzuhaben. Das Grundprinzip von CacheFormer besteht darin, lange Texte in kleinere Segmente zu unterteilen und anhand komprimierter Aufmerksamkeitswerte die am meisten relevanten Segmente zu identifizieren. Diese hochaufmerksamen Segmente werden im Gegensatz zu herkömmlichen Methoden nicht komprimiert, sondern im Originalzustand abgerufen und erneut in die Aufmerksamkeitsschicht eingespeist. Dadurch wird der Informationsverlust durch Segmentkompression minimiert und eine bessere Kontextualisierung gewährleistet. Darüber hinaus führt CacheFormer ein intelligentes Segmentüberlappungskonzept ein, das Fragmentierungseffekte der Segmentierung reduziert.
Indem angrenzende Segmente zu einem Teil überlappen, ermöglicht das Modell eine fließendere Informationsbindung zwischen Segmenten. So werden Übergänge und Beziehungen über Segmentgrenzen hinweg effizienter erfasst. CacheFormer aggregiert vier unterschiedliche Aufmerksamkeitsmechanismen in seinem Modell: eine lokale Short-Range-Aufmerksamkeit mit sliding-window-Mechanismus, die klassische komprimierte Long-Range-Aufmerksamkeit auf Segmentebene, die dynamische Rückgewinnung der Top-k hochaufmerksamen unkomprimierten Segmente sowie die neuartige überlappende Segmentaufmerksamkeit. Diese Kombination führt zu einer erheblichen Leistungssteigerung bei der Verarbeitung langer sequenzieller Daten. Im Vergleich zu bisherigen Ansätzen wie Transformer-XL, Linformer oder Performer bietet CacheFormer eine durchdachte Balance zwischen Rechenaufwand und Modellgenauigkeit.
Viele bestehende Modelle leiden unter Informationsverlust aufgrund starrer Kompressionen oder fokussieren nur auf lokale Abhängigkeiten, was die Erfassung globaler Zusammenhänge erschwert. CacheFormers dynamisches Segmentcaching und die Überlappungstechnologie ermöglichen dagegen eine flexible, situationsabhängige Nutzung von Kontextinformationen – ob sie am Anfang, in der Mitte oder am Ende eines langen Textes stehen. Die Praxis zeigt, dass CacheFormer bei der Sprachmodellierung auf Benchmarks wie WikiText-103 signifikante Verbesserungen erzielt. Das Modell erreicht eine Reduktion der Perplexität um etwa 8,5 % im Vergleich zum Long-Short Transformer bei ähnlicher Modellgröße. Dies bedeutet eine genauere Vorhersagewahrscheinlichkeit der nächsten Wörter und eine bessere Modellperformance im Kontextverständnis.
Ebenso auf Charakter-Ebene, gemessen durch Bits per Character (BPC) auf dem enwik-8-Datensatz, bestätigt sich die Robustheit des Modells. Ein besonders spannendes Merkmal von CacheFormer ist das dynamische Retrieval der Segmente. Anders als starre Systeme, die stets feste Segmente berücksichtigen, berechnet CacheFormer während der Laufzeit die Aufmerksamkeitsstärken über die komprimierten Segmente. Die Segmente mit den höchsten Aufmerksamkeitswerten werden dann im unkomprimierten Originalformat in den Kontext gezogen und erhalten somit mehr Einfluss auf die Vorhersage. Dies erinnert an das Prinzip eines Computer-Caches, in dem durch intelligente Vorhaltung von häufig benötigten Daten Zugriffszeiten drastisch reduziert werden.
Die überlappende Segmentierung adressiert ein altbekanntes Problem der Segmentierung in Transformer-basierten Architekturen: die Fragmentierung von Kontextinformationen. Standardverfahren schneiden den Text streng in nicht überlappende Chunks, was dazu führt, dass wichtige semantische Zusammenhänge an den Segmentgrenzen verloren gehen. CacheFormer gleicht dies aus, indem es Segmente mit einer Überlappungsgröße von 50 % konstruiert, sodass für einen Teil jeder Segmente die angrenzenden Nachbarsegmente mitberücksichtigt werden. Dies verleiht dem Modell ein fast nahtloses Verständnis der Textstrukturen. Natürlich bringt die Aggregation mehrerer Aufmerksamkeitstypen auch Herausforderungen mit sich.
Die Berechnung von Short-Range-, Long-Range-, Cache-basierten sowie überlappenden Aufmerksamkeiten hat theoretisch eine erhöhte Komplexität. CacheFormer begegnet dem durch gezielte Komprimierung der Long-Range-Komponente auf eine kleinere Dimension r und effiziente Mittelung der Aufmerksamkeit über Texteinheiten. So bleibt die Gesamtzeitkomplexität nahe an der von implementierten Sliding-Window-Ansätzen. Die Implementierung und Evaluation des CacheFormer-Modells erfolgte mit Hardware wie der NVIDIA RTX 4090, wobei eine sorgfältige Wahl von Parametern wie Segmentlänge, Kompressionsrate, Top-k-Werten für die Cache-Retrieval und der Zahl der überlappenden Segmente zu optimalen Ergebnissen führte. Die verwendeten Modellgrößen (z.
B. 12 Layer, 12 Köpfe, Embedding-Dimension 768) ermöglichen einen fairen Vergleich mit anderen State-of-the-Art-Modellen ähnlicher Größe. Abschließend ist zu erwähnen, dass trotz der ausgezeichneten Ergebnisse die Trainingszeit durch die dynamische Segmentauswahl erhöht ist. Hier setzen die Entwickler auf zweistufige Trainingsstrategien, bei denen zunächst ohne dynamisches Caching vorgelernt und dann auf das volle CacheFormer-System feinjustiert wird. Zudem sind Erweiterungen wie hierarchische Cache-Designs in Planung, die noch längere Kontexte effizient verarbeiten sollen.