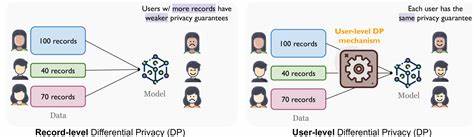
Die Entwicklung von Künstlicher Intelligenz (KI) und insbesondere großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren enorme Fortschritte gemacht. Diese Modelle benötigen für optimale Leistungsfähigkeit häufig eine Feinabstimmung auf spezifische, oft sehr sensible Datensätze. Ein zentrales Problem dabei ist der Schutz der Privatsphäre der einzelnen Nutzer, deren Daten für das Training verwendet werden. Hier kommt das Konzept der User-Level Differential Privacy ins Spiel, das einen starken Datenschutz auf Nutzerbasis gewährleistet und dabei hilft, die Leistungsfähigkeit der Modelle auch bei der Verarbeitung vertraulicher Daten zu erhalten. Differential Privacy ist ein mathematisches Verfahren, das sicherstellt, dass die Einbeziehung oder der Ausschluss einzelner Datenpunkte keinen signifikanten Einfluss auf das Ergebnis eines Modells hat.
Klassischerweise wird dies auf Ebene einzelner Beispiele (Example-Level) angewandt, was jedoch nicht ausreicht, wenn ein Nutzer sehr viele Datenpunkte bereitstellt. Bei dieser Vorgehensweise könnten Angreifer möglicherweise durch Auswertung der Datensätze Rückschlüsse auf einzelne Nutzer ziehen. User-Level Differential Privacy adressiert dieses Problem, indem der Schutz auf die Gesamtheit der Daten eines einzelnen Nutzers ausgeweitet wird. Dadurch ist es unmöglich, basierend auf dem trainierten Modell zu erkennen, ob Daten eines bestimmten Nutzers in die Trainingsmenge eingeflossen sind oder nicht. Dies entspricht einer deutlich strengeren Datenschutzanforderung und reflektiert besser die Realität moderner Datenbesitzverhältnisse, bei denen individuelle Nutzer oft viele Dateneinträge besitzen.
Die Umsetzung von User-Level Differential Privacy gestaltet sich komplexer als die Beispiel-basierte Variante. Insbesondere muss wesentlich mehr Rauschen in die Trainingsverfahren eingebracht werden, um den stärkeren Schutz zu ermöglichen. Dieses höhere Maß an zusätzlichem Rauschen wirkt sich üblicherweise negativ auf die Lernfähigkeit und die Qualität des resultierenden Modells aus. Dieses Problem verschärft sich mit der Größe des Modells, was bei der Feinabstimmung von LLMs eine große Herausforderung darstellt. In jüngster Forschung wurden daher Methoden entwickelt, um User-Level Differential Privacy effizient und skalierbar bei LLMs umzusetzen, insbesondere in der flexiblen Umgebung von Rechenzentren.
Dort stehen mehr Möglichkeiten zur Verfügung als beim klassischen föderierten Lernen auf verteilten Endgeräten wie Smartphones. So können sowohl einzelne Beispiele als auch komplette Nutzer gezielt für die einzelnen Trainingsrunden ausgewählt werden, was mehr Kontrolle und Optimierungspotenzial bietet. Zwei zentrale Trainingsansätze für User-Level Differential Privacy sind das Beispiel-Level Sampling (ELS) und das Nutzer-Level Sampling (ULS). Beim ELS werden zufällig einzelne Datenpunkte gezogen, wie im Standard-Verfahren, bei ULS werden komplette Nutzer samt all ihren zugehörigen Daten gezogen. Beide Ansätze haben ihre Vor- und Nachteile und verlangen jeweils eine sorgfältige Wahl der sogenannten 'Contribution Bound' – einer Obergrenze der nutzerbezogenen Datenmenge, die in den Trainingsprozess einfließt.
Ein zu hoher Wert erfordert mehr Rauschen, was die Modellqualität beeinträchtigen kann, während ein zu kleiner Wert viele Daten einfach verwirft und dadurch ebenfalls negative Folgen für das Modell hat. Durch die Verwendung neuartiger mathematischer Analysen konnten Forscher den tatsächlich notwendigen Grad des hinzugefügten Rauschens dramatisch reduzieren, insbesondere für das Beispiel-Level Sampling. Die Erkenntnisse zeigen, dass der Datenschutz mit Nutzer-Level Differential Privacy nicht so stark exponentiell mit der Größe der Nutzerdatenmenge abnimmt, sondern in etwa linear, was erheblich bessere Trainingsresultate ermöglicht. Darüber hinaus brachte die Forschung verbesserte Heuristiken für die Wahl der Contribution Bound hervor. So ist es bei ELS sinnvoll, ihn an der Mediananzahl der Beispiele pro Nutzer zu orientieren, während bei ULS eine Vorhersage des Gesamtrauschens bei verschiedenen Bound-Werten hilft, den optimalen Punkt zu bestimmen.
Dadurch können aufwändige Trainingsläufe vermieden und Ressourcen effizienter genutzt werden. Experimente, bei denen ein Transformer-Modell mit 350 Millionen Parametern auf realen Datensätzen wie StackOverflow und CC-News mit beiden Sampling-Verfahren getestet wurde, zeigten interessante Ergebnisse: User-Level Sampling erzielt in den meisten Szenarien eine bessere Modellqualität, außer in Fällen mit besonders hohen Datenschutzanforderungen oder wenn nur beschränkte Rechenressourcen zur Verfügung stehen. Auffällig war auch, dass beide Methoden, trotz strikter Datenschutzgarantien, das vortrainierte Modell übertrafen, was die praktische Relevanz der Ansätze unterstreicht. Die Kombination aus mathematischer Innovation, optimierter Parameterwahl und der Nutzung der zentralisierten Infrastruktur von Rechenzentren macht das Fine-Tuning großer Sprachmodelle mit User-Level Differential Privacy erstmals praktikabel und effizient. Dies eröffnet neue Möglichkeiten für den Einsatz von KI in sensiblen Domänen, wie dem Gesundheitswesen, Finanzsektor oder personenbezogenen Kommunikationsdiensten, wo strikte Datenschutzvorgaben gelten.
Neben den technischen Fortschritten hat die Arbeit auch gesellschaftliche Bedeutung. Während viele KI-Anwendungen zunehmend kritisch auf den Datenschutz hinterfragt werden, bietet die Einbettung von User-Level Differential Privacy eine glaubwürdige Lösung, um das Vertrauen der Nutzer zurückzugewinnen und gleichzeitig den Mehrwert der KI weiter zu steigern. Modelle, die nach solchen Verfahren trainiert wurden, können auf sensiblen Daten aufbauen, ohne einzelne Nutzerinformationen preiszugeben. Trotz der bisherigen Erfolge existieren weiterhin Herausforderungen, etwa die hohe Rechenlast der Differential Privacy Verfahren und die feine Abstimmung der Parameter je nach Anwendung und Datensatz. Auch die Integration in bestehende industrielle Pipelines und die Skalierung auf noch deutlich größere Modelle bleiben relevante Forschungsfelder.
Dennoch stellen die bisherigen Erkenntnisse einen bedeutenden Schritt in der verantwortungsvollen Entwicklung von KI dar. Zusammenfassend lässt sich sagen, dass User-Level Differential Privacy ein vielversprechender Ansatz ist, um die Feinabstimmung großer Sprachmodelle sicher und effektiv zu gestalten. Durch innovatives Sampling, verbesserte Rauschminderung und optimale Parameterstrategien gelingt es, den Datenschutz konsequent einzuhalten, ohne die Leistungsfähigkeit der Modelle unnötig zu beeinträchtigen. Dies ebnet den Weg für neue Anwendungen, bei denen sensible Nutzerdaten im Mittelpunkt stehen, und stärkt die Akzeptanz von KI in der Gesellschaft.