Die rasante Entwicklung großer Sprachmodelle (Large Language Models, kurz LLMs) hat in den vergangenen Jahren für Aufsehen in vielen wissenschaftlichen Disziplinen gesorgt – auch in der Chemie. Diese auf maschinellem Lernen basierenden Systeme sind in der Lage, nicht nur natürliche Sprache zu verstehen, sondern auch komplexe fachliche Fragen zu beantworten und kreative Lösungen vorzuschlagen. Die Frage, ob diese Modelle die Expertise erfahrener Chemiker ersetzen oder ergänzen können, ist angesichts der immer breiteren Nutzung von KI im Labor- und Forschungsalltag besonders relevant. Große Sprachmodelle basieren auf umfangreichen Trainingsdaten, die aus einem breiten Spektrum schriftlicher Informationsquellen stammen. Dabei steigert die schiere Datenmenge und Modellgröße die Fähigkeit der Systeme, Fachwissen abzubilden.
Neueste Studien und Benchmarking-Frameworks wie ChemBench erlauben nun erstmals eine systematische und objektive Messung der chemischen Kompetenz von LLMs im Vergleich zu menschlichen Experten. Mit mehreren Tausend ausgewählten Fragen und Lösungen aus Universitätskursen, Prüfungssammlungen und spezialisierten chemischen Datenbanken sorgen diese Tests für eine umfassende Bewertung der Modelle. Die Ergebnisse sind bemerkenswert: Einige der leistungsfähigsten Modelle konnten in diesen Vergleichen menschliche Chemiker übertreffen, zumindest bei einer Vielzahl von Wissenstests und Aufgaben, die verschiedene chemische Disziplinen abdecken. Dabei erzielte das führende Modell, beispielsweise o1-preview, fast doppelt so viele richtige Antworten wie der durchschnittliche Teilnehmer der Expertenstudie. Selbst moderne Open-Source-Modelle nähern sich in ihrer Leistung zunehmend denen proprietärer Systeme an und zeigen, dass die Demokratisierung der KI im Chemiebereich voranschreitet.
Trotz dieser Erfolge offenbaren die Analysen erhebliche Einschränkungen. Während das Auswendiglernen von chemischem Faktenwissen den Modellen gut gelingt, sind sie bei komplexeren Aufgaben, die tiefgründiges Verständnis und mehrschichtige logische Schlussfolgerungen erfordern, noch nicht auf menschlichem Niveau. So fällt es den Modellen insbesondere schwer, chemische Strukturen zu interpretieren, Molekülsymmetrien zu erkennen oder physikalisch-chemische Eigenschaften wie Kernspinresonanzspektrum-Signale zuverlässig vorherzusagen. Diese Diskrepanz lässt sich teilweise durch die Art und Weise erklären, wie LLMs trainiert werden: Die Modelle sind primär auf Mustererkennung in Textdaten ausgelegt und erfassen chemische Zusammenhänge oft nur durch statistische Korrelationen statt durch echtes strukturelles oder mechanistisches Verstehen. Dies wird besonders deutlich, wenn die Modellleistung nicht mit der molekularen Komplexität korreliert – das Verhalten der Systeme zeigt eher, dass bekannte Beispiele aus den Trainingsdaten erkannt werden, anstatt dass eine generelle chemische Intuition entwickelt wurde.
Ein weiterer Schwachpunkt ist die Sicherheitsrelevanz: Gerade bei Fragen zur Toxizität, Chemikaliensicherheit oder Gefahrenpotenzial liefern viele Modelle falsche oder unzuverlässige Antworten – mit potenziell gefährlichen Konsequenzen, wenn solche Informationen unkritisch genutzt werden. Zudem sind die eigenen Vertrauensangaben der LLMs bezüglich ihrer Antworten oft schlecht kalibriert. Sie neigen dazu, übermäßig selbstsicher aufzutreten, selbst wenn die Richtigkeit ihrer Antworten fraglich ist. Dies stellt eine große Herausforderung für den Einsatz der Systeme in sicherheitskritischen Kontexten dar. Es ist jedoch wichtig, die Fortschritte differenziert zu betrachten.
Die Tatsache, dass einige Modelle besser als durchschnittliche Chemiker abschneiden, fordert traditionelle Bildungsansätze heraus. Die reine Auswendiglernfähigkeit verliert zugunsten von kritischem Denken und tiefgehender chemischer Analyse an Bedeutung. Dies signalisiert einen Paradigmenwechsel, der sowohl die Lehrpläne als auch die Prüfungsformate an Hochschulen beeinflussen könnte. Lernende müssten vermehrt Kompetenzen entwickeln, die Maschinen schwer replizieren können, wie kreativ-analytisches Denken und experimentelles Design. Parallel dazu eröffnet die Kombination von LLMs mit spezialisierten Tools und Datenbanken erhebliche Chancen.
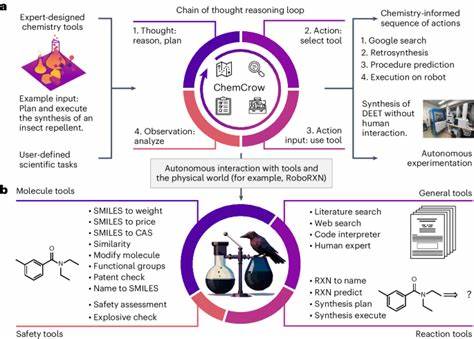
Modelle, die externe Suchfunktionen, chemie-spezifische Datenquellen oder Rechenmodule integrieren, können Wissenslücken besser schließen und komplexere Aufgaben erfüllen. Solche agentenbasierten oder tool-gestützten KI-Systeme könnten künftig als chemische Assistenten oder „Copiloten“ in Forschungslaboren dienen und durch ihre Fähigkeit zum schnellen Abruf und zur Integration umfangreicher Fachinformationen Arbeitsprozesse beschleunigen. Dabei zeigt die Forschung auch, dass offene Fragen zum Umgang mit KI in der Chemie bestehen bleiben. Die Interpretation und Validierung der von Modellen generierten Ergebnisse erfordern weiterhin menschliches Expertenurteil. Trotz beeindruckender Fortschritte sind Modelle nicht in der Lage, chemische Präferenzen oder das „Bauchgefühl“ erfahrener Chemiker vollständig nachzubilden.
Beispielsweise gelingt es kaum, zwischen zwei potenziell relevanten Molekülen sinnvoll vorzuziehen, so wie es menschliche Medicinalchemiker in frühen Screening-Phasen tun. In ethischer Hinsicht ist der Dual-Use-Gedanke von großer Bedeutung. Technologien, die bei der Entwicklung neuer Medikamente oder umweltfreundlicher Materialien helfen, können auch missbräuchlich für die Synthese gefährlicher Substanzen genutzt werden. Die breite Zugänglichkeit von LLMs verschärft dieses Risiko und unterstreicht die Notwendigkeit rigoroser Kontrollmechanismen sowie verantwortungsvoller Nutzungskonzepte. Abschließend lässt sich festhalten, dass große Sprachmodelle im Chemiebereich ein enormes Potenzial innehaben, die Forschung und Ausbildung grundlegend zu transformieren.
Sie können das Wissen großer Datenmengen komprimiert bereitstellen, komplexe Probleme schneller zugänglich machen und als kreative Ideengeber fungieren. Gleichzeitig bleiben sie jedoch Werkzeuge, die menschliche Expertise ergänzen, aber nicht ersetzen können. Ihre Grenzen in der Tiefenanalyse, Unsicherheitsschätzung und ethisch sensiblen Nutzung sind wichtige Herausforderungen, die durch kontinuierliche Forschung, Verbesserung der Modelle und ein tieferes Verständnis von menschlichem Wissen gemeistert werden müssen. Mit dem ChemBench-Benchmark existiert erstmals eine solide Grundlage, um zukünftige Entwicklungen objektiv zu messen und systematisch zu verbessern. Die Vernetzung von Maschinenintelligenz mit menschlicher Kreativität und kritischem Denken wird den nächsten Meilenstein im Fortschritt der chemischen Wissenschaften darstellen.
Das Zusammenspiel zwischen innovativen KI-Lösungen und erfahrenen Chemikern hat das Potenzial, die Grenzen des Möglichen in F&E sowie Bildung neu zu definieren und dabei Sicherheit und Verantwortung stets im Fokus zu behalten.