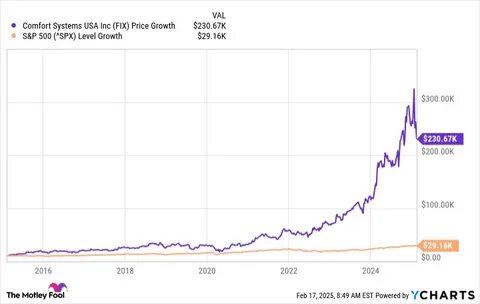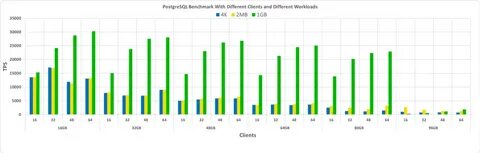
Mit der Veröffentlichung von Postgres 18 Beta1 wurde erneut der Fokus auf die Optimierung von Datenbankleistung in anspruchsvollen Umgebungen gelegt. Besonders spannend sind die Testergebnisse auf einem Großserver mit IO-begrenzten Einfügeoperationen, die Rückschlüsse sowohl auf technische Verbesserungen als auch auf mögliche Flaschenhälse erlauben. In der Verarbeitung großer Datenmengen ist es essenziell, nicht nur die Rohleistung der CPU zu betrachten, sondern vor allem das Zusammenspiel von Speicher, Festplattenzugriffen und paralleler Verarbeitung. Das Ziel ist, den Durchsatz zu maximieren und gleichzeitig die Systemlatzenz möglichst gering zu halten. Die aktuelle Benchmark wurde auf einem Hetzner-Server vom Typ ax162-s durchgeführt, ausgestattet mit einem AMD EPYC 9454P Prozessor mit 48 Kernen, ohne SMT, daneben mit 128 GB RAM und einer Storage-Konfiguration aus zwei NVMe-Laufwerken, die via Software-RAID 1 gespiegelt werden.
Das Dateisystem ext4 kommt dabei zum Einsatz. Die Benchmark misst gezielt IO-gebundene Insert-Schritte und nutzt für diesen Test 20 Clients, die jeweils eine eigene Tabelle mit 200 Millionen Zeilen befüllen. Da der Datenbestand größer ist als der verfügbare Hauptspeicher, ist im Benchmark das I/O-Verhalten ein dominierender Einflussfaktor. Die verwendeten Konfigurationen für Postgres 18 Beta1 variieren dabei hinsichtlich der IO-Methoden und können Aufschluss darüber geben, welche Strategien in der Praxis am effektivsten sind. Verglichen wurde die neue Version mit dem stabilen Release 17.
4 als Basislinie. Die Konfigurationen für Postgres 18 Beta1 nutzen unterschiedliche IO-Methoden: ein synchroner Standardmodus, eine Worker-basierte parallele IO-Nutzung mit vier Arbeitern sowie die moderne io_uring-Schnittstelle, die direkte Asynchronität für Linux-Dateisysteme ermöglicht. Diese Varianten erlauben einen Vergleich hinsichtlich Schreibdurchsatz und paralleler Verarbeitungslast. Die Benchmark umfasst mehrere wesentliche Schritte, die die verschiedenen Aspekte von Insert-Workloads und Abfragen abdecken. Beim initialen Laden (l.
i0) werden zehn Millionen Zeilen pro Tabelle sequenziell unter Nutzung des Primärschlüssels eingefügt. Besonders auffällig ist hier, dass Postgres 18 Beta1 mit allen getesteten IO-Methoden einen rund 4% höheren Durchsatz als Version 17.4 erzielt. Ursächlich dafür scheinen ein niedrigerer Kontextwechselrate und ein höherer konstanter Schreibdurchsatz auf die Speichermedien (gemessen in write MB/s) zu sein. Dies ist ein klarer Hinweis darauf, dass die interne Verarbeitung von IO-Operationen für den Erstbefüllungsprozess deutlich effizienter geworden ist.
Anschließend folgt die Indexerstellung (l.x), hierbei werden pro Tabelle drei sekundäre Indizes erzeugt. In dieser Phase zeigt sich, dass die neuen IO-Methoden mit synchroner und Worker-basierten Abläufen eine ähnliche Performance wie die alte Version bieten. Sogar ein Vorteil von etwa 7% entsteht gegenüber dem io_uring-Modus in Version 17.4.
Überraschend ist hier, dass die io_uring-Konfiguration in 18 Beta1 den höchsten Schreibdurchsatz zeigt, was auf eine bessere Ausnutzung der Hardwarekontrolle der asynchronen IO-Calls hinweist. In den schreibintensiven Phasen, l.i1 und l.i2, bei denen neben Einfügungen auch Löschen in hoher Frequenz mitlaufen, sind zunächst keine dramatischen Performanceveränderungen im Vergleich zu Vorgängerversionen zu verzeichnen. Spannend ist allerdings ein stark verbessertes Ergebnis bei l.
i2 mit der io_method=worker Konfiguration, bei dem Postgres 18 Beta1 rund 40% mehr Durchsatz erzielen konnte. Diese Leistungssteigerung geht einher mit einer deutlich geringeren CPU-Zeit pro Operation, was auf Optimierungen im Task-Scheduling und Threadmanagement hindeutet. Diese Auswertung ist allerdings vorläufig, da die Messung wiederholt wird, um Schwankungen auszuschließen. Während der Abfragephasen mit Bereichssuchen (range queries) und punktuellen Suchanfragen (point queries) zeigen sich leichte Performanceverschlechterungen mit bis zu 3-5% weniger Durchsatz gegenüber Version 17.4.
Die Vermutung liegt in einem zusätzlichen CPU-basierten Overhead, der durch neue Architekturänderungen zustande kommen könnte, zum Beispiel durch Anpassungen im Locking oder Scheduling in der Datenbankengine. Die Tests für Bereichsabfragen wurden mit drei verschiedenen Intensitätsstufen bei der Hintergrundlast durchgeführt: 100, 500 und 1000 Inserts und Deletes pro Sekunde. Hier konnte keiner der getesteten Systeme die gewünschte SLA von 20.000 Inserts und Deletes pro Sekunde vollständig erfüllen, es wurden stets rund 18.000 Operationen pro Sekunde erreicht.
Diese Tatsache illustriert die Grenzen der Hardware und Software bei stark konkurrierenden IO- und Rechenlasten. Bei den Punktabfragen wurden vergleichbare Resultate erzielt. Auch hier zeigte sich, dass die neuen IO-Methoden auf dem Großserver insgesamt eine solide Funktion bieten, wobei io_method=sync leicht besser abschneidet als andere Varianten. Die Benchmark zeigt eindrucksvoll, welche Fortschritte in der Datenbankentwicklung bei Postgres mit der Version 18 Beta1 erzielt wurden, vor allem hinsichtlich effizienterer IO-Verarbeitung bei großen, speicherübergreifenden Workloads. Gleichzeitig weisen die leicht verschlechterten Ergebnisse bei den Abfragen auf Optimierungsbedarf im Umgang mit CPU-Overhead und paralleler Last hin.
Die Verwendung moderner IO-Strategien wie io_uring eröffnet enorme Potenziale, um den schreiblastigen Teil der Datenbankoperationen besser zu skalieren. Besonders auf leistungsstarken Servern mit vielen CPU-Kernen und schnellen NVMe-Laufwerken zeigt sich, dass die Wahl der IO-Methode und die richtige Konfiguration der Parallelität unmittelbare Auswirkungen auf die Gesamtperformance haben. Die Benchmarks verdeutlichen, wie wichtig eine differenzierte Betrachtung der einzelnen Schritte einer typischen Datenbankarbeitslast ist. Neben der reinen Einfügegeschwindigkeit spielen Indexerstellung, gemischte Lese- und Schreibzugriffe sowie SLA-gerechte Verarbeitungsraten eine entscheidende Rolle. Unternehmen und IT-Teams gewinnen somit wertvolle Orientierung, wenn sie die für ihre spezifischen Workloads geeignete Version und Konfiguration finden möchten.
Darüber hinaus zeigen die Ergebnisse, dass bei komplexen parallelen Workloads ein ausgewogenes Verhältnis von CPU-Ressourcen, IO-Fähigkeiten und Softwareoptimierung unverzichtbar ist. Einfache Upgrades auf neue Versionen bringen nicht zwangsläufig uneingeschränkte Performancegewinne bei allen Einsatzszenarien – gezielte Profilierung und wiederholte Tests sind essenziell. Für Datenbankadministratoren bedeutet die Erkenntnis, dass Postgres 18 Beta1 insbesondere bei initialem Laden und write-intensiven Szenarien punktet, während bei Mixed-Read-Write Query-Arten noch kleine Einbußen auftreten, eine wertvolle Hilfestellung bei der Planung von Systemupgrades oder Hardwareinvestitionen. Die Benchmark liefert pragmatische Einblicke in das Zusammenspiel von Linux-Kernel-Funktionalität (wie io_uring), Postgres-Interna und modernen High-End-Servern. Somit sind zukünftige Entwicklungen im Open-Source-Projekt PostgreSQL weiterhin spannend zu beobachten, vor allem im Hinblick auf Performanceoptimierung bei realistischen, praxisrelevanten Lastprofilen.
Der Benchmark wurde sorgfältig mit einem konsistenten Software-Setup durchgeführt, inklusive kompiliertem Quellcode mit optimierendem Compiler-Flag (-O2), um repräsentative Resultate zu erzielen. Die Testserien wurden mehrfach durchgeführt, um Varianz zu minimieren und belastbare Vergleichswerte zu erhalten. Dabei konnten aussagekräftige Kennzahlen wie Kontextwechselraten, CPU-Zeit pro Abfrage sowie Durchsatz in Megabyte pro Sekunde erfasst werden. Insgesamt bestärkt das Ergebnis von Postgres 18 Beta1, dass die neue Major-Version für Workloads auf großen Servern mit speicher- und IO-intensiven Szenarien gut positioniert ist. Die Kombination aus verbesserten IO-Mechanismen und hoher Parallelität bietet eine solide Basis für anspruchsvolle Enterprise-Datenbanksysteme.
Gleichzeitig sind noch kleinere Stellschrauben bei CPU-Effizienz und Lastverteilung zu justieren, um auch bei komplexen Mixed-Workloads vollends überzeugen zu können. Für Praktiker empfiehlt sich ein kontrollierter Test der Beta-Version auf eigenen Systemen, um konkrete Auswirkungen auf die jeweiligen Anwendungsfälle zu evaluieren und von den frühen Performanceverbesserungen zu profitieren. PostgreSQL bleibt somit ein flexibles, leistungsstarkes System, das mit jeder neuen Version seine Fähigkeit zur Skalierung und Optimierung weiter ausbaut – ein entscheidender Faktor für moderne datenintensive Anwendungen und Big-Data-Umgebungen.